As you know, Google has appealed its search monopoly ruling and with that, filed a number of new documents with the court. One is an affidavit of Elizabeth Reid, Google's Vice President and Head of Search. The other is of Jesse Adkins Director of Product Management for Search Syndication and Search Ads Syndication.
In the Affidavit of Elizabeth Reid '" Document #1471, Attachment #2 Reid talks about why Google thinks it should not go through with some of the court's remedies.
Specifically, Google does not want to go through with the "Required Disclosures of Data" and Section V titled "Required Syndication of Search Results." Why? Reid wrote, "Google will suffer immediate and irreparable harm as a result of the transfer of this proprietary information to Google's competitors, and may additionally suffer irreparable financial and reputational harm should the data provided to competitors be leaked or hacked."
The details Google would have to give competitors include:
- a unique identifier ('DocID') of each document (i.e., URL) in Google's Web Search Index and information sufficient to identify duplicates;
- 'a DocID to URL map'; and
- "for each Doc ID, the (A) time that the URL was first seen, (B) time that the URL was last crawled, (C) spam score, and (D) device-type flag."
Google thinks handing this over will:
(1) Give its competitors an unfair advantage because Google spent dozens of years working on these methods.
(2) It would give away which URLs Google thinks are more important than others.
(3) It would allow spammers to reverse engineer some of its algorithms.
(4) It will make private information from searchers available to its competitors.
Google wrote:
First, Google's crawling technology processes webpages on the open web, relying on proprietary page quality and freshness signals to focus on webpages most likely to serve users' information needs. Second, Google marks up crawled webpages with proprietary page understanding annotations, including signals to identify spam and duplicate pages. Finally, Google builds the index using the marked-up webpages generated in the annotation phase. Google's index employs a proprietary tiering structure that organizes webpages based on how frequently Google expects the content will need to be accessed and how fresh the content needs to be (the fresher the content needs to be, the more frequently Google must crawl the webpage).
It goes on to read, "The image below from the demonstrative (RDXD-28.005) shows the fraction of pages (in green) that make it into Google's web index, compared with the pages that Google crawls (in red). Under the Final Judgment, Google must disclose to Qualified Competitors the curated subset reflected in green."
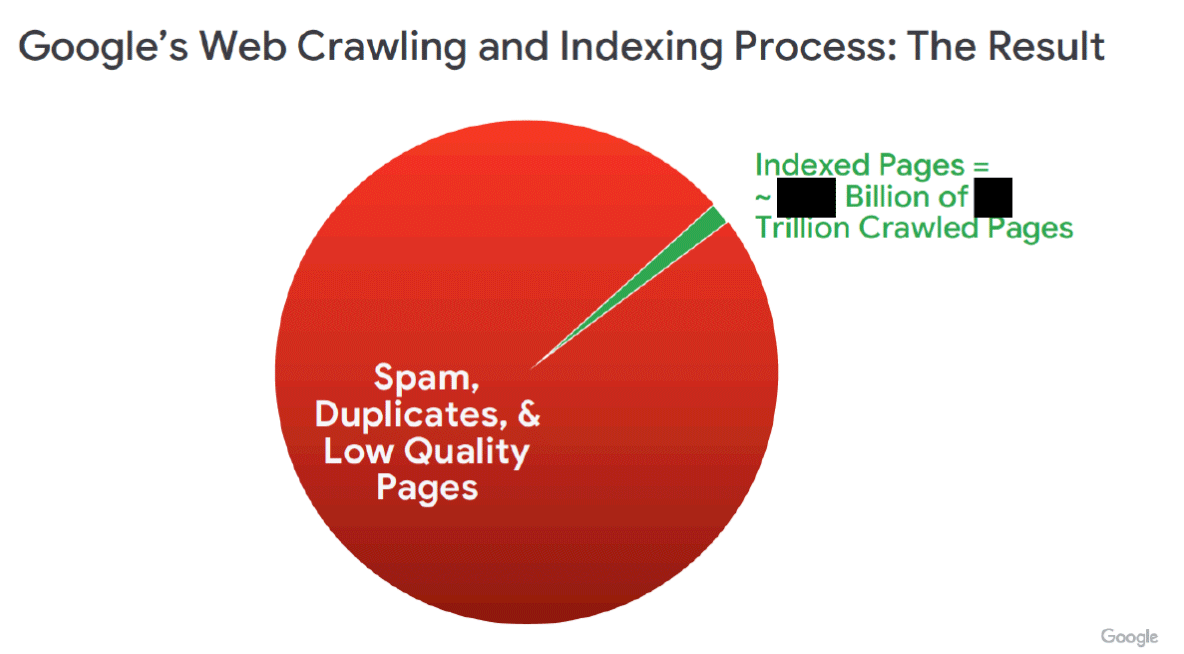
Yea, that shows how many URLs Google knows about what is indexed by Google. That is a huge difference!
Google added:
If spammers or other bad actors were to gain access to Google's spam scores from Qualified Competitors via data leaks or breaches'"a realistic outcome given the tremendous value of the data'"Google's search quality would be degraded and its users exposed to increased spam, thereby weakening Google's reputation as a trustworthy search engine.The disclosure of the spam signal values for Google's indexed webpages via a data leak or breach would degrade Google's search quality and diminish Google's ability to detect spam. As I testified at the remedies hearing, the open web is filled with spam. Google has developed extensive spam-fighting technologies to attempt to keep spam out of the index. Fighting spam depends on obscurity, as external knowledge of spam-fighting mechanisms or signals eliminates the value of those mechanisms and signals.
If spammers or other bad actors gained access to Google's spam scores, they could bypass Google's spam detection technologies and hamstring Google in its efforts to combat spam. For example, spammers commonly buy or hack legitimate websites and replace the content with spam, an attack made easier if spammers can use Google's spam scores to target webpages Google has assessed as low spam risk. In this way, the compelled disclosures are likely to cause more spam and misleading content to surface in response to user queries, compromising user safety and undermining Google's reputation as a trustworthy search engine.
Then it gets into GLUE and RankEmbed:
User-side Data used to build, create, or operate the GLUE statistical model(s)' and (ii) 'User-side Data used to train, build, or operate the RankEmbed model(s),' 'at marginal cost.'The 'User-side Data' encompassed by Section IV.B of the Final Judgment includes highly sensitive user data, including but not limited to the user's query, location, time of search, and how the user interacted with what was displayed to them, for example hovers and clicks.
The data used to build Google's 'Glue' model also includes all web results returned and their order, as well as all search features returned and their order. The Glue model captures this data for the preceding thirteen months of search logs.
You can also review the Affidavit of Jesse Adkins '" Document #1471, Attachment #3 - that is on the ad side.
Forum discussion at Marie Haynes private forums (sorry).