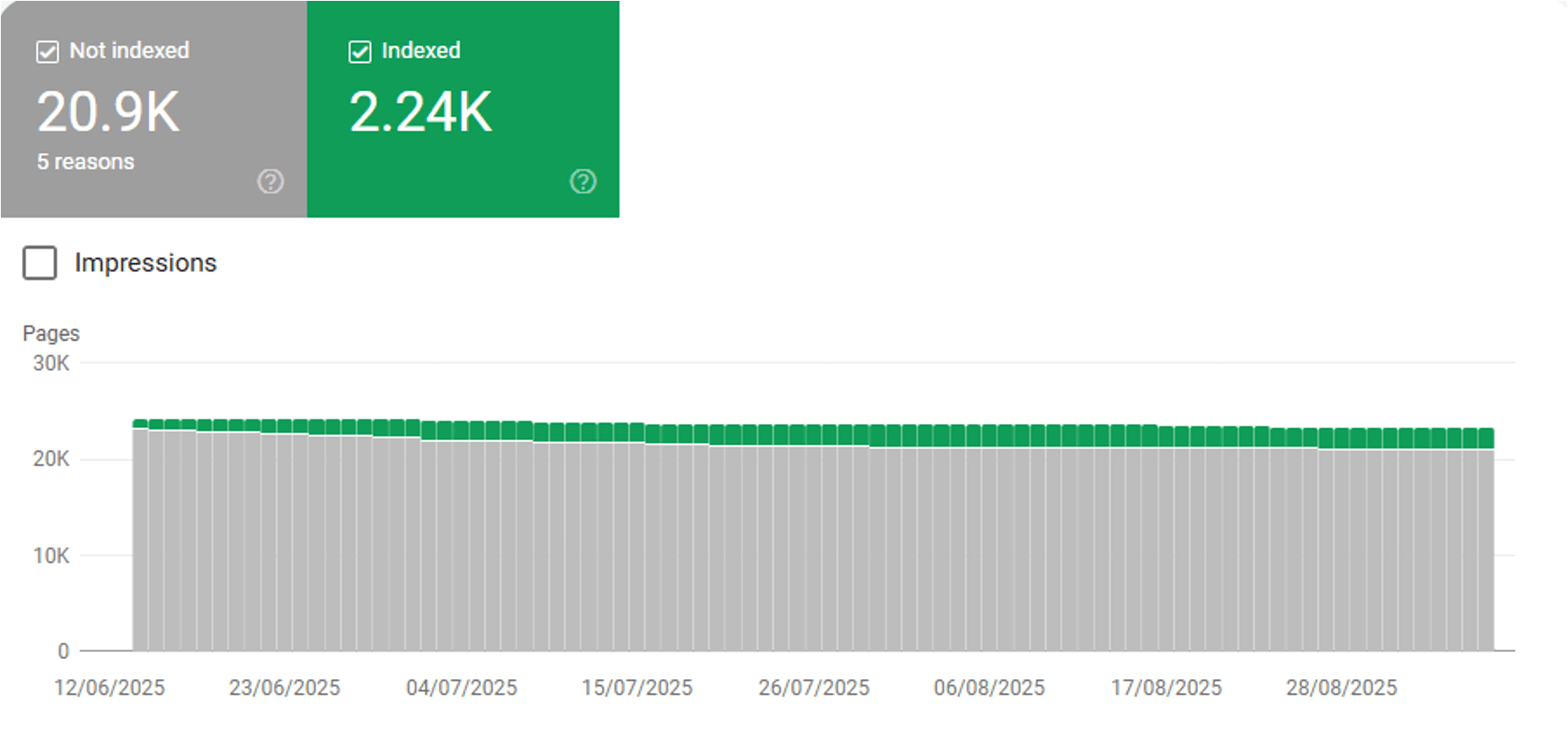
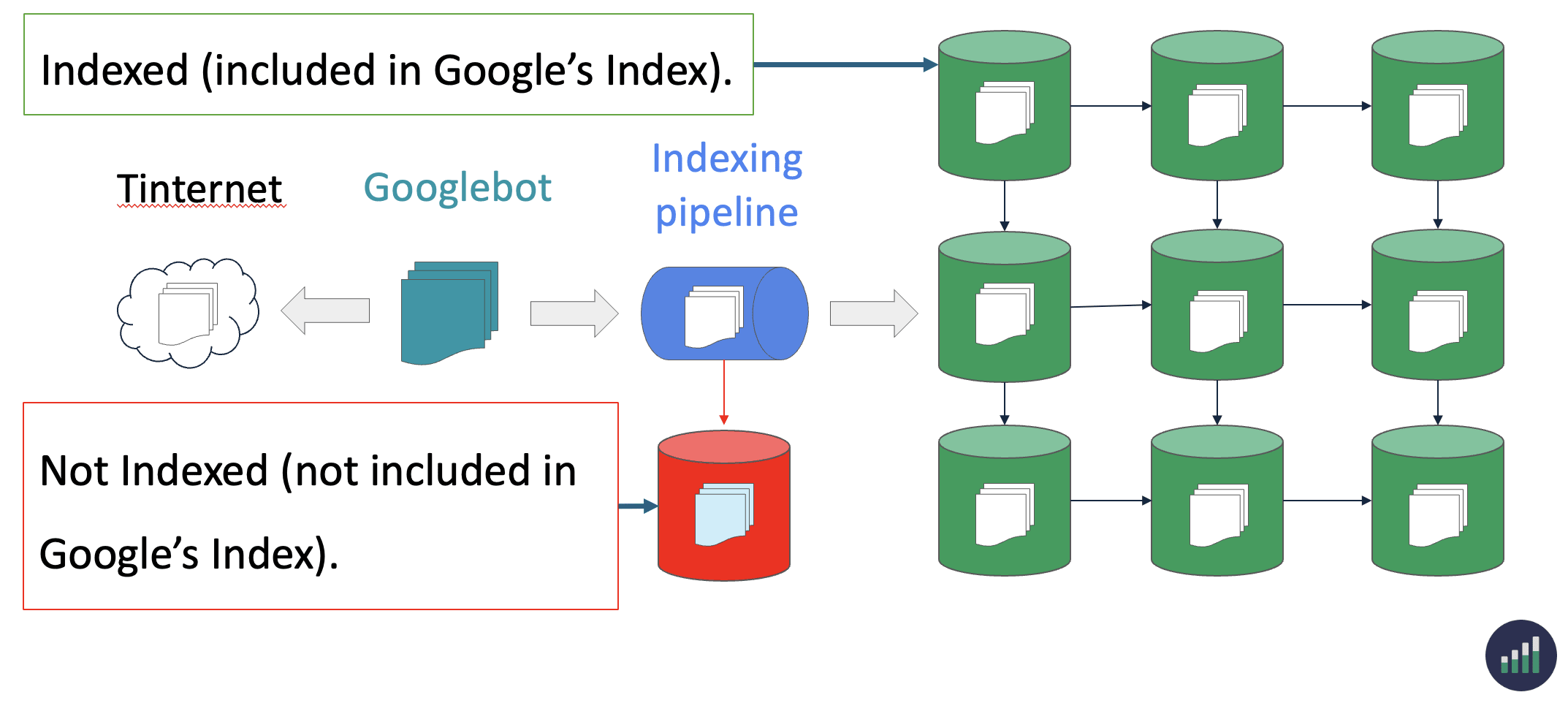
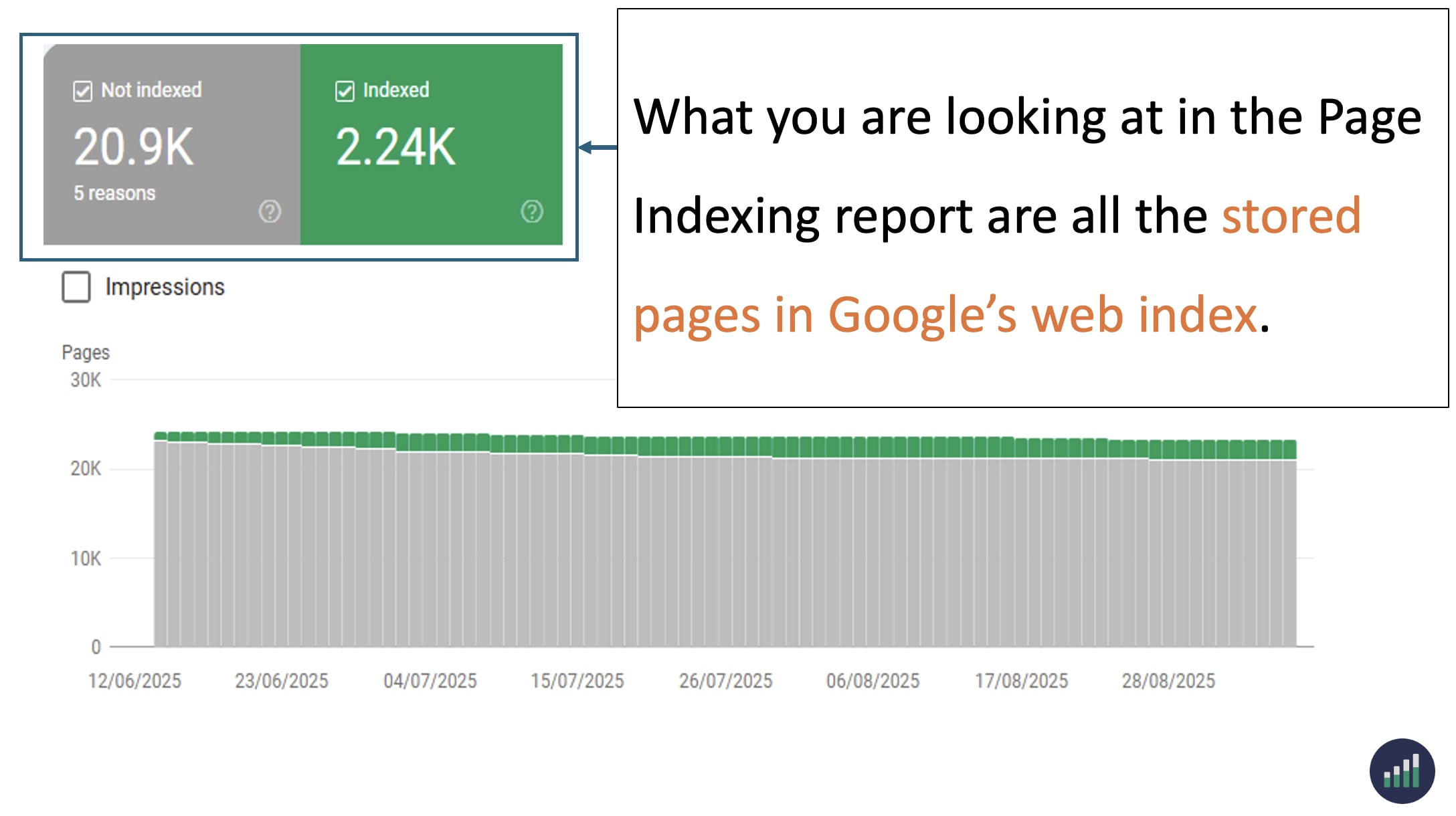
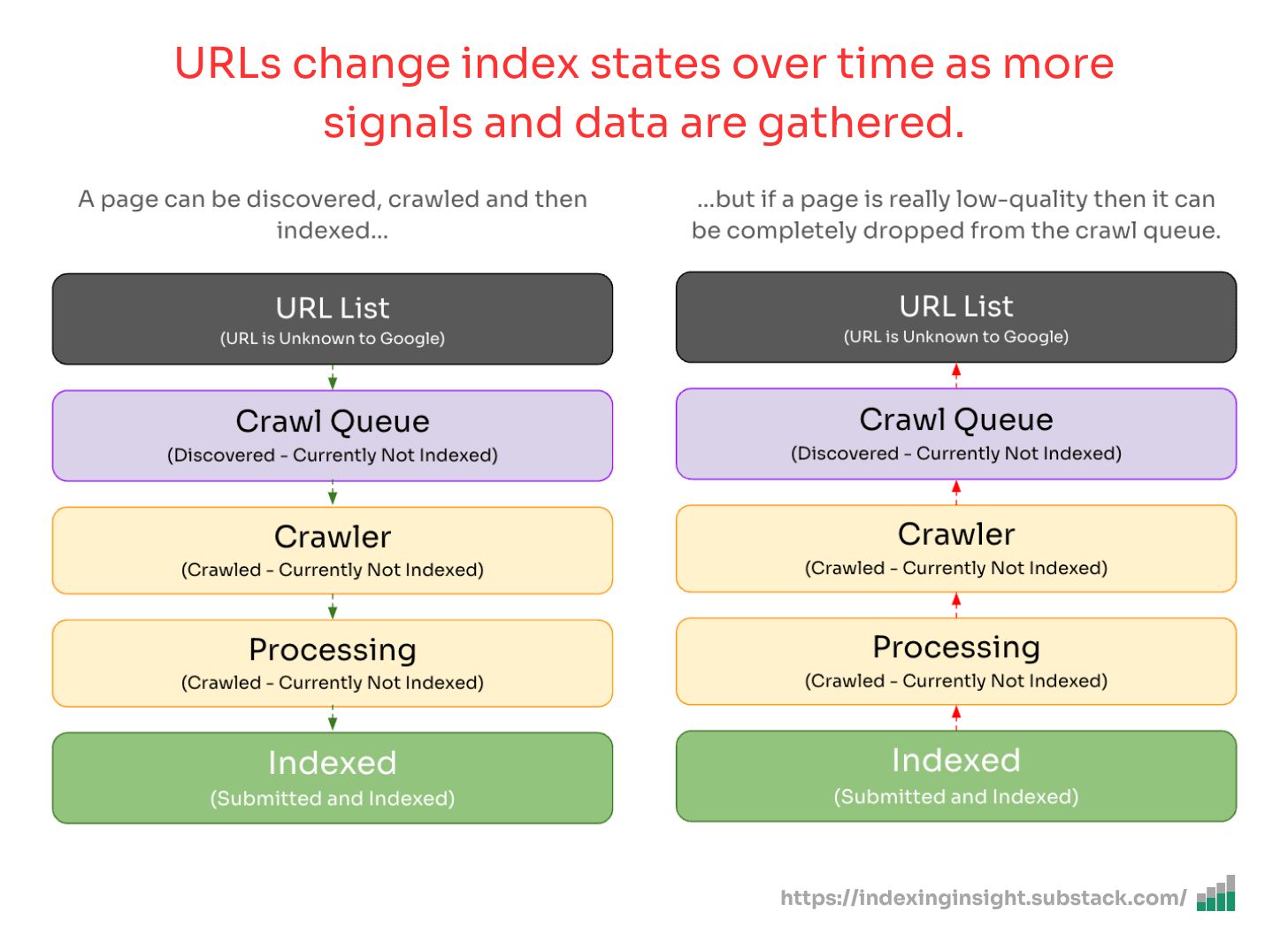
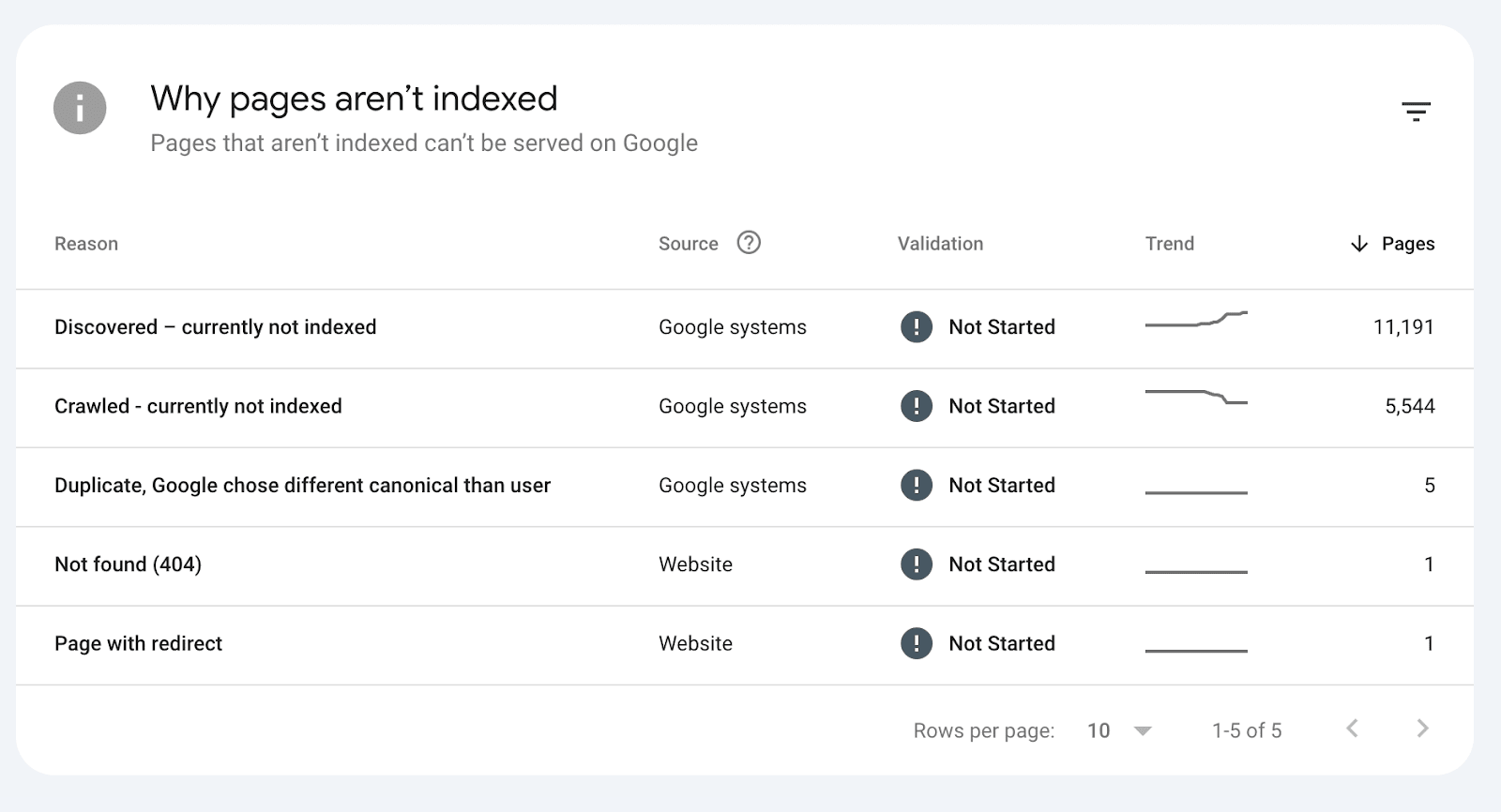
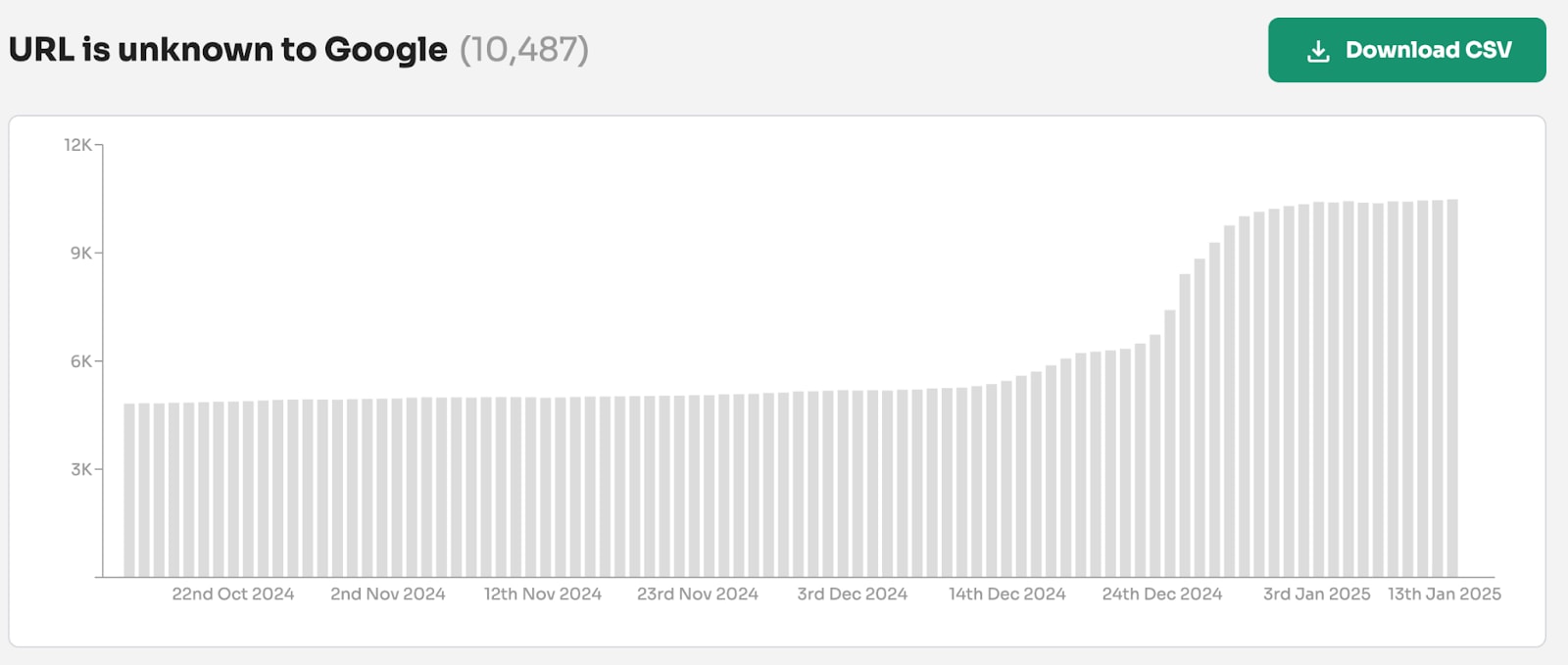
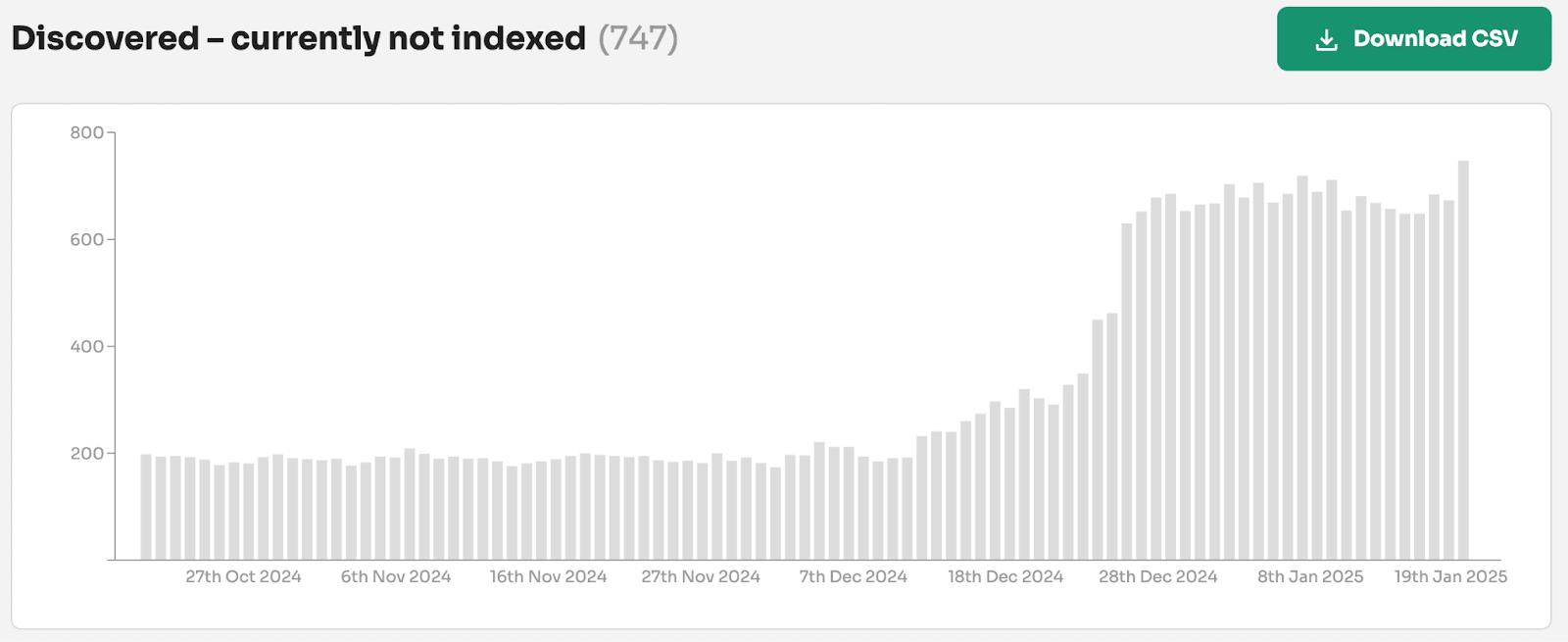
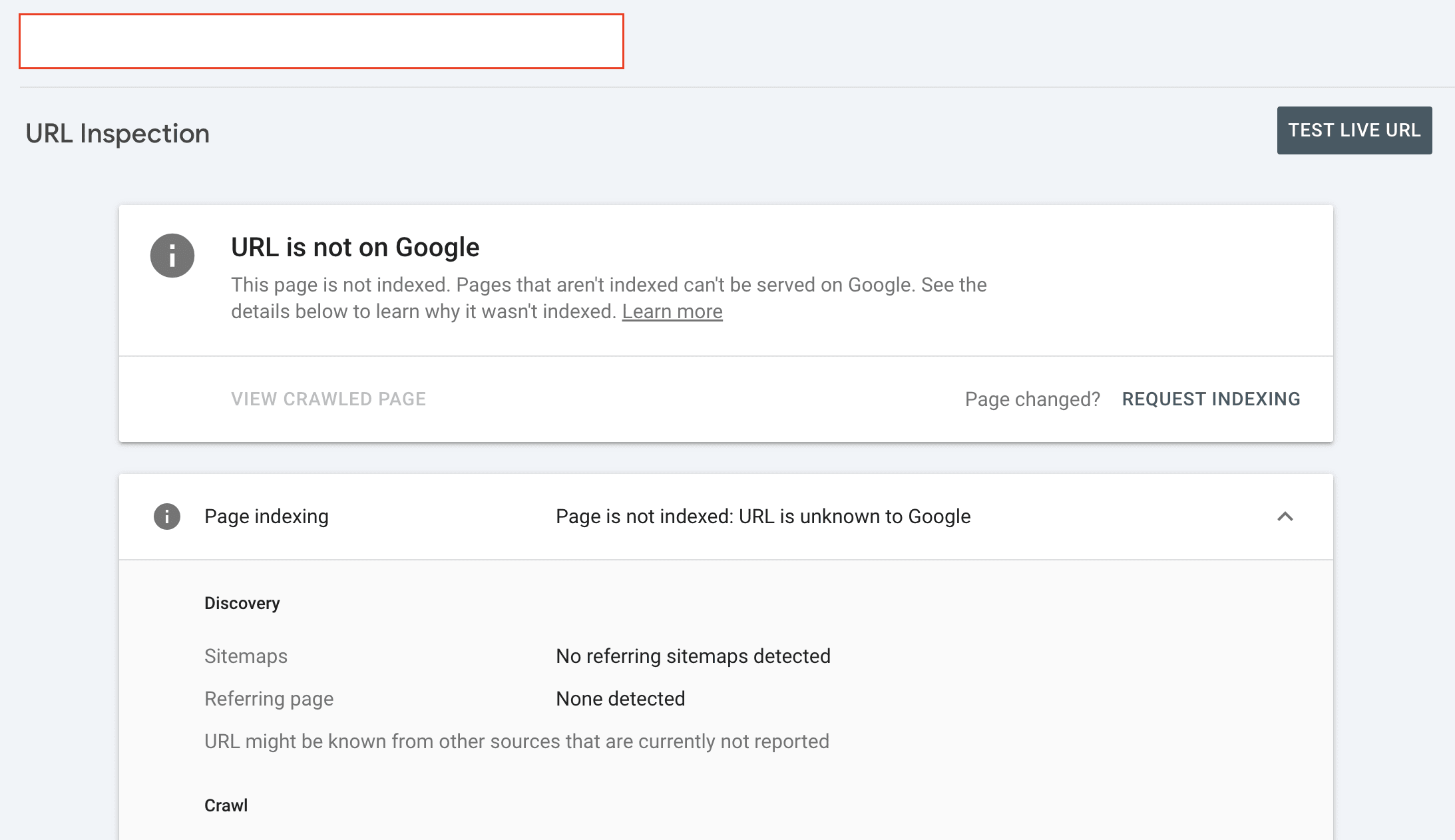
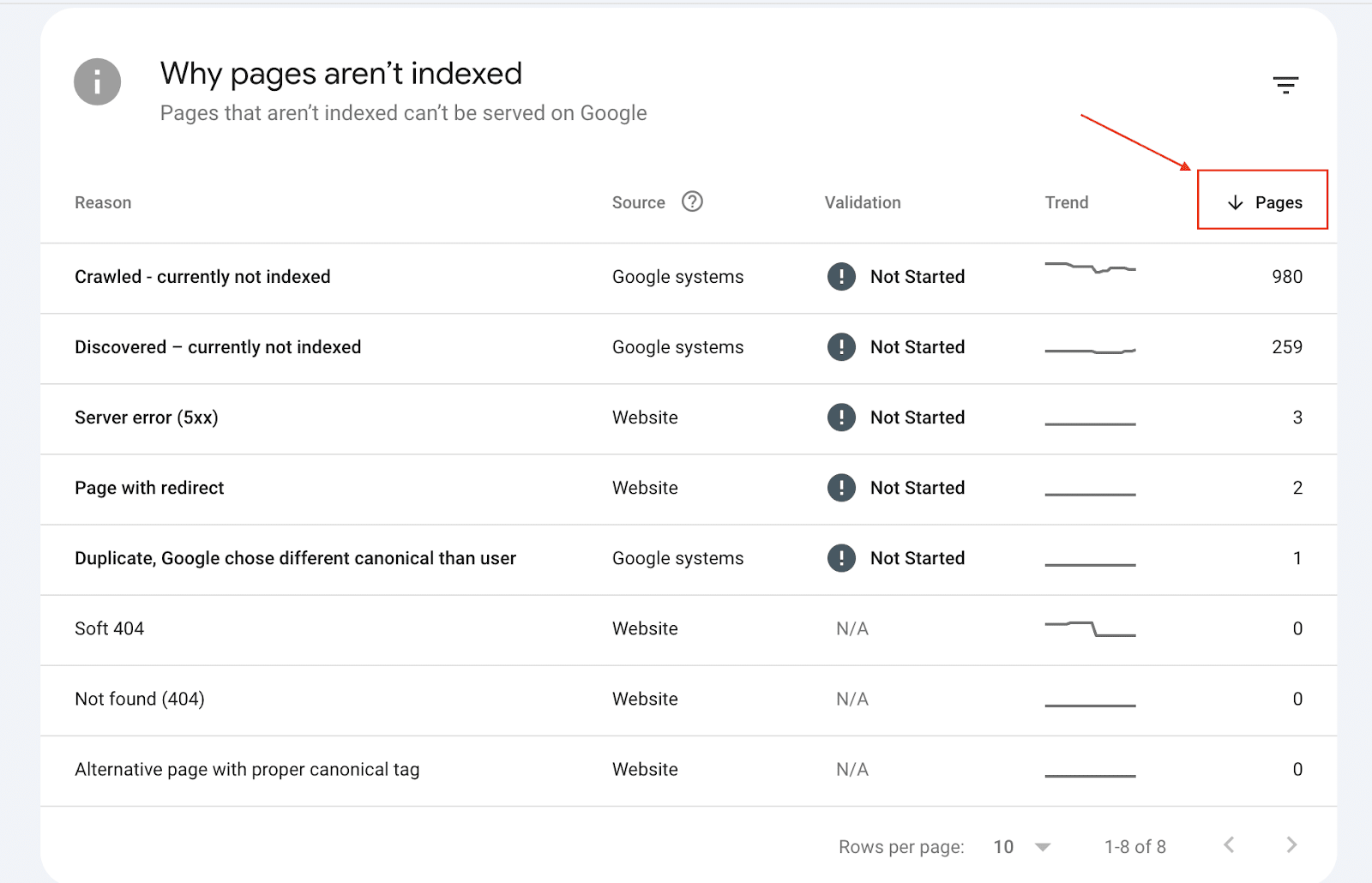
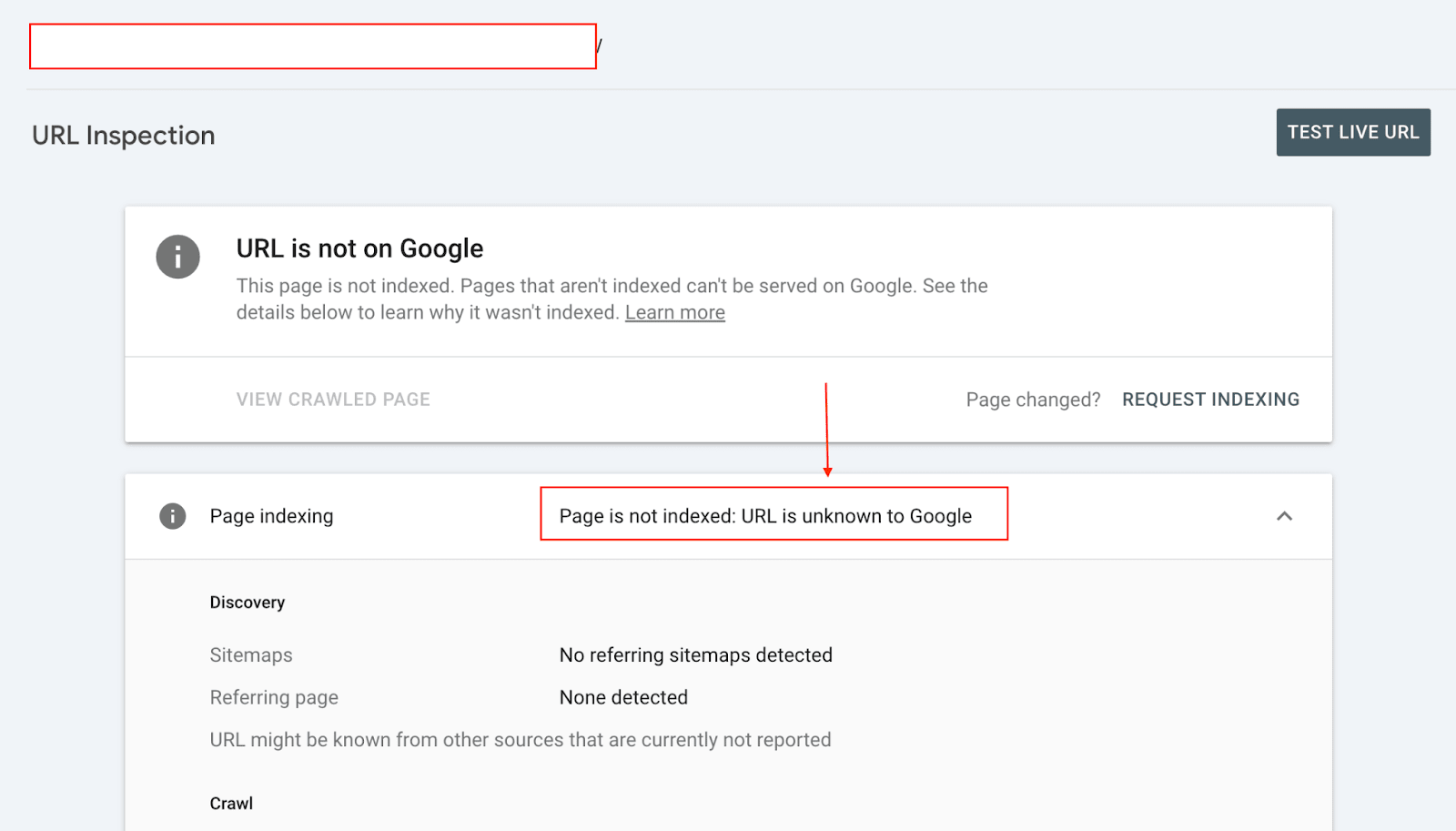
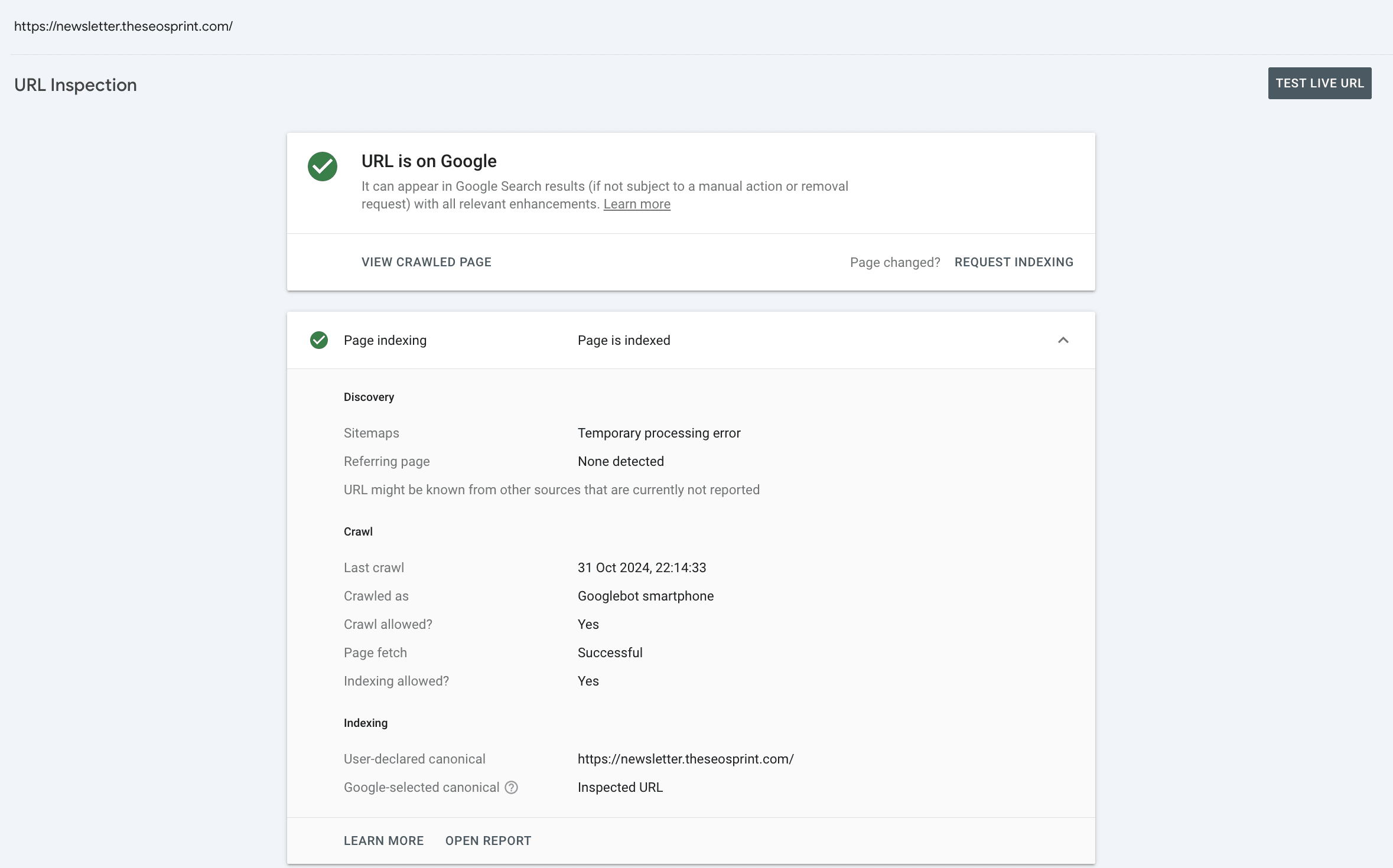
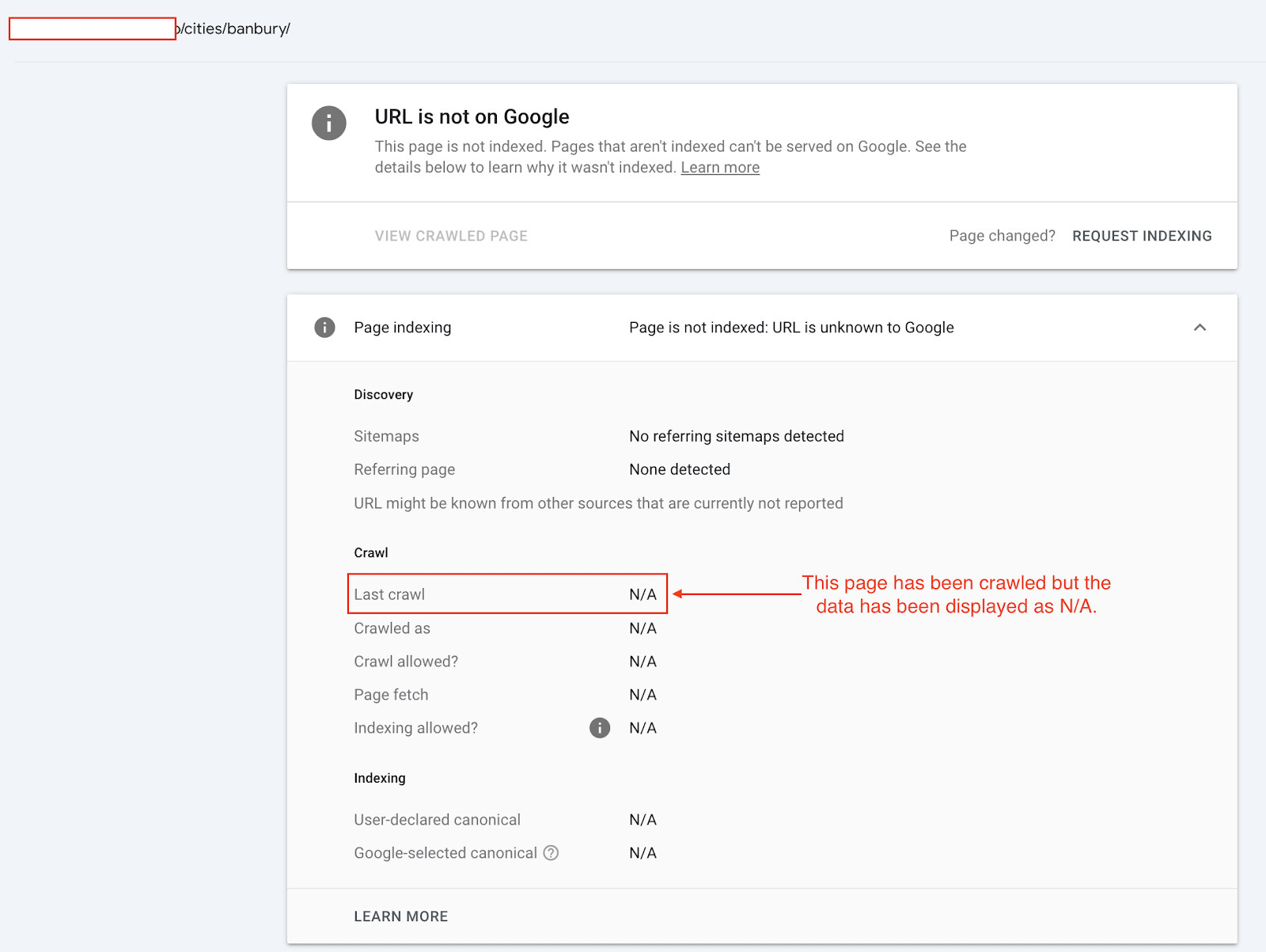
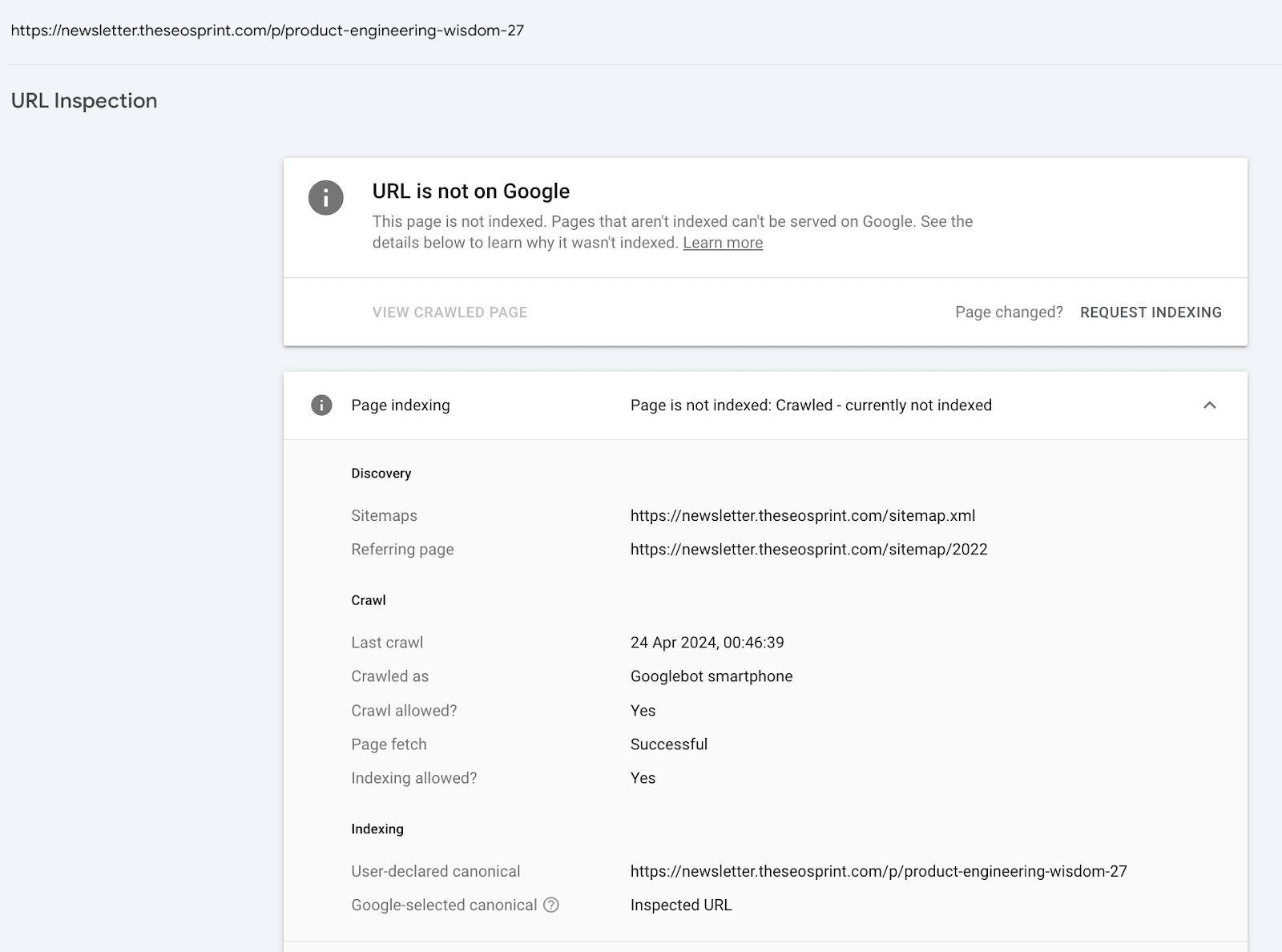
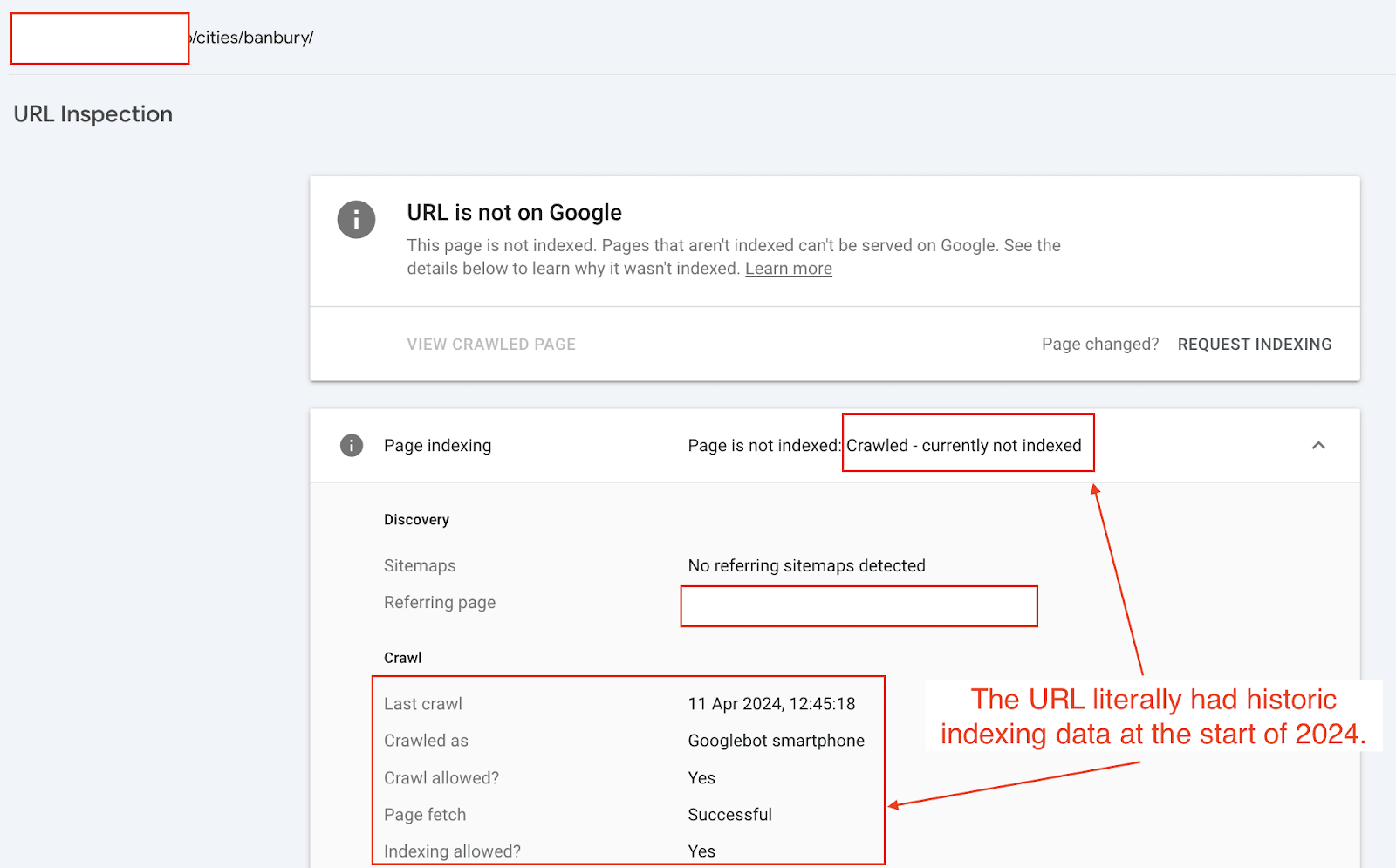
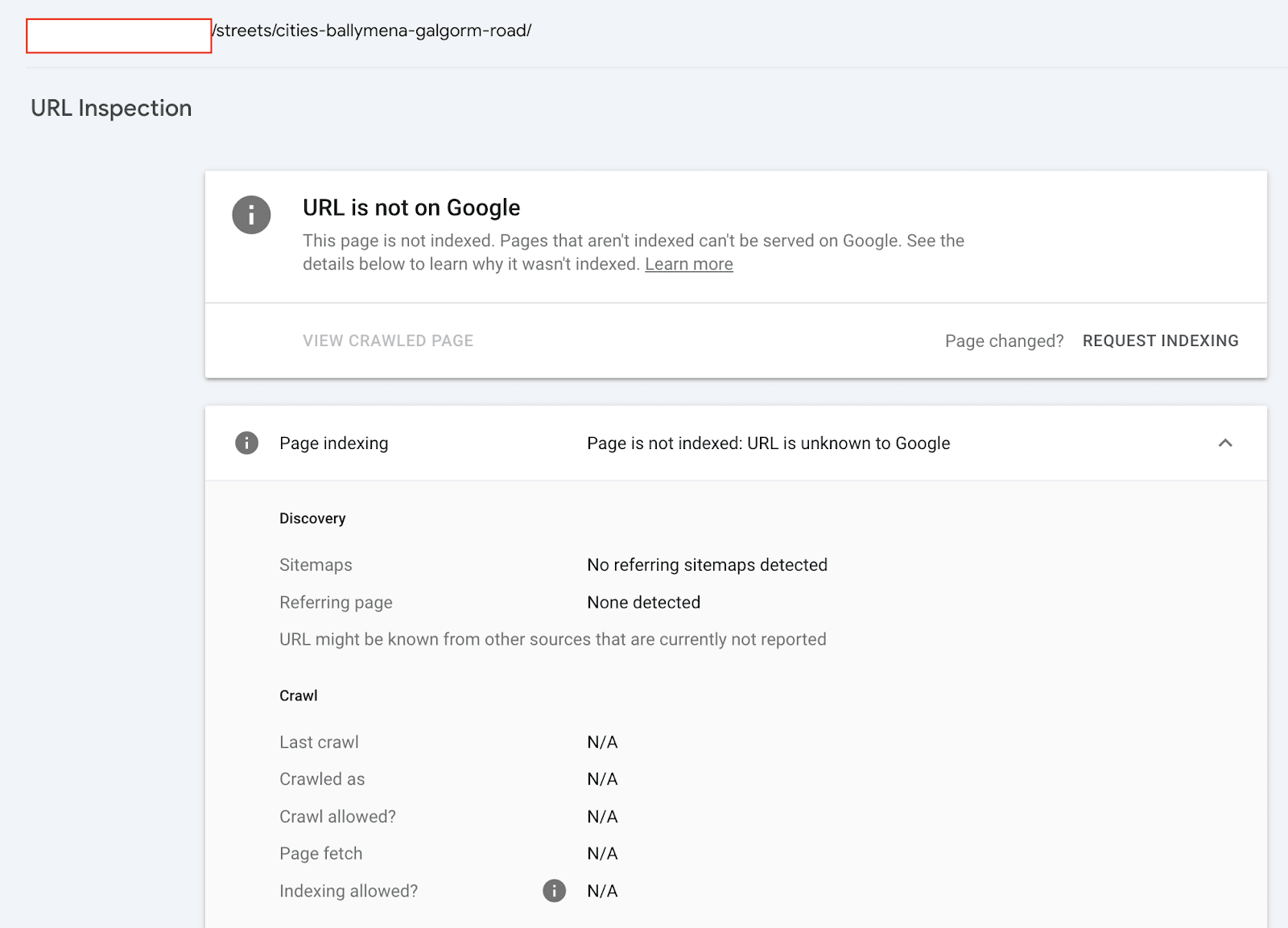
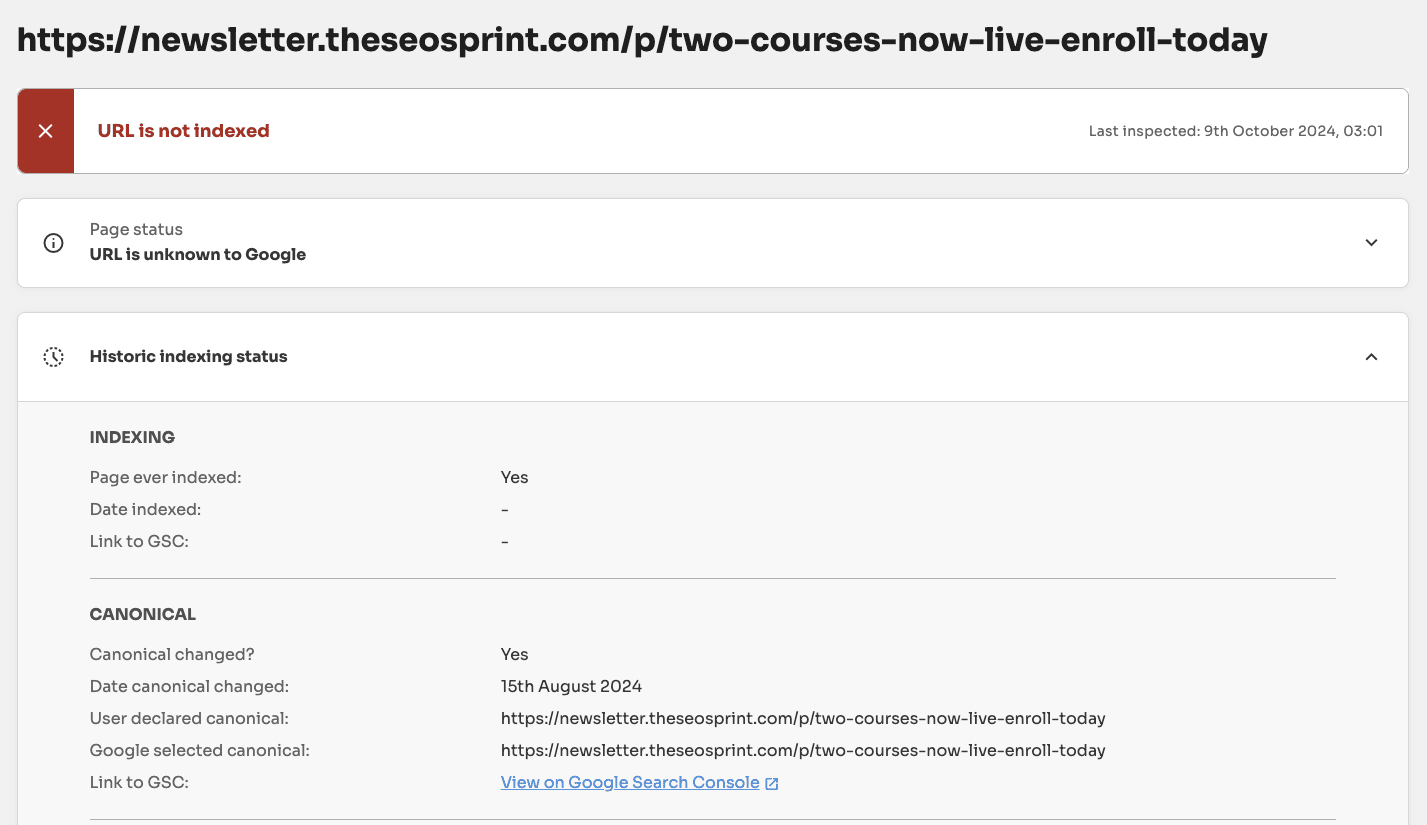
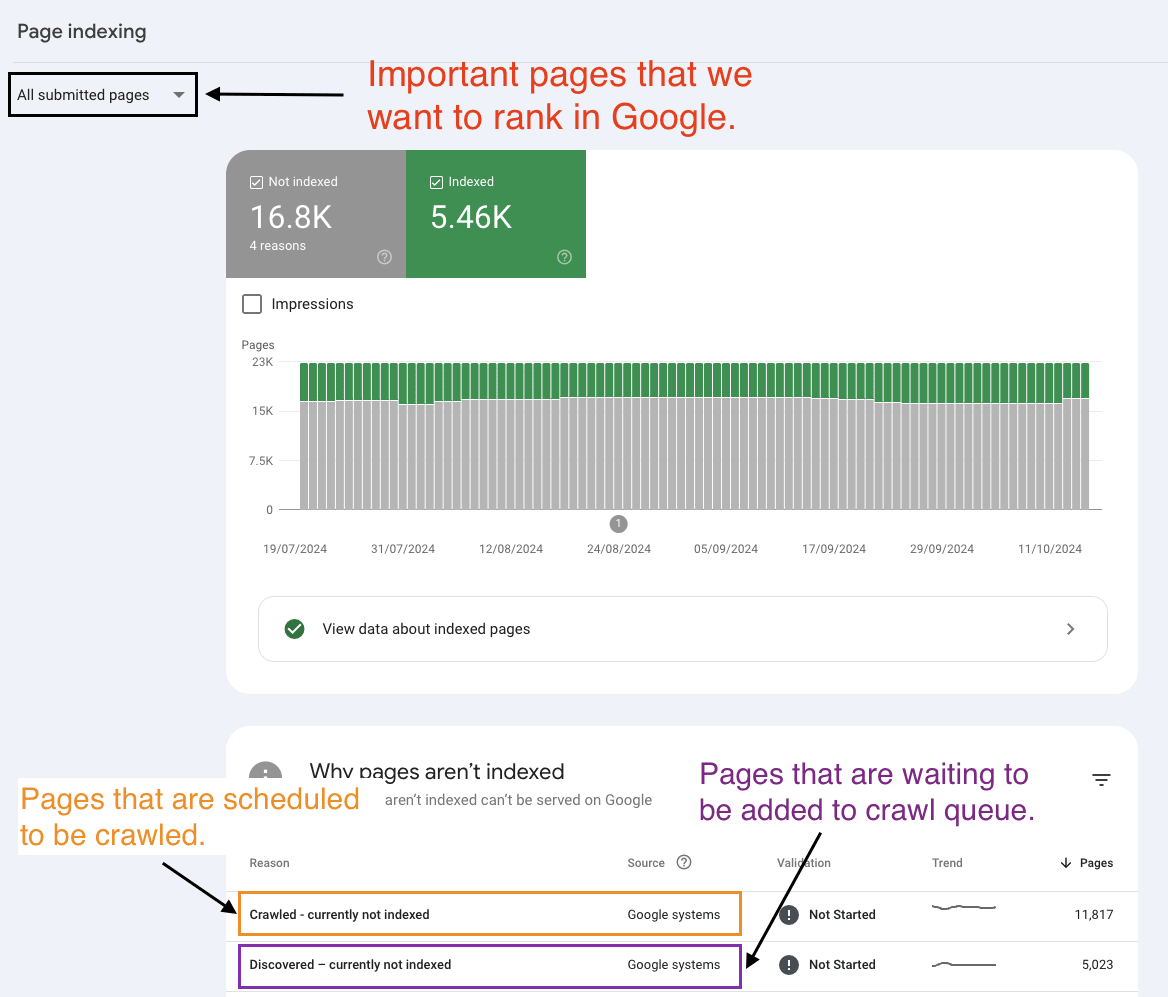
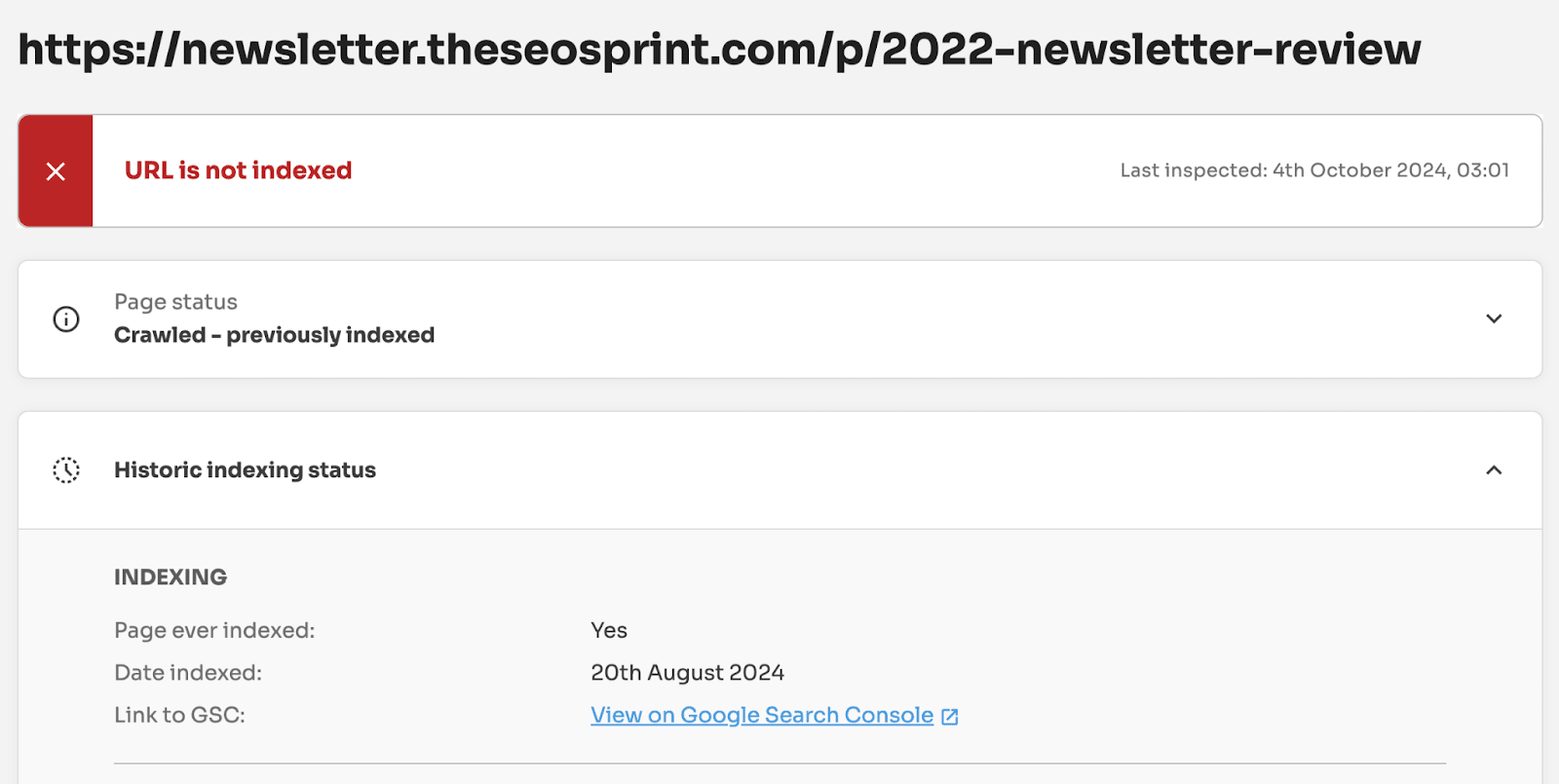
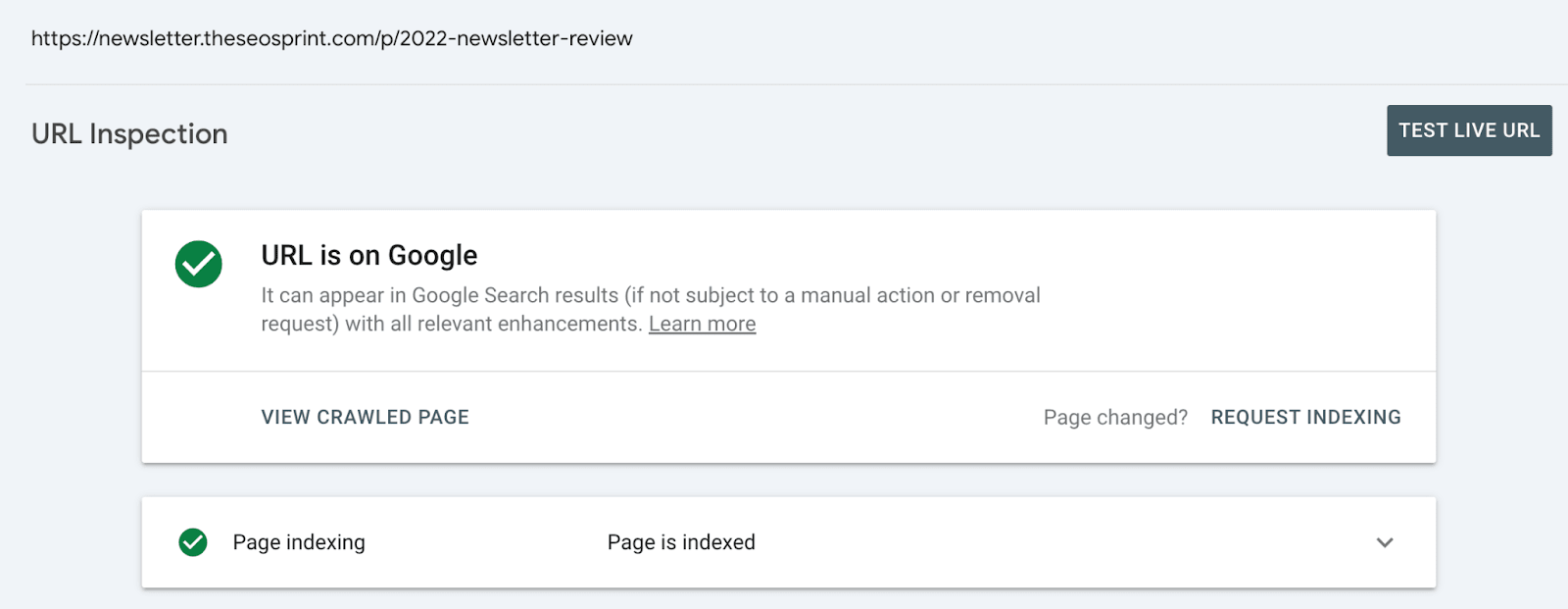
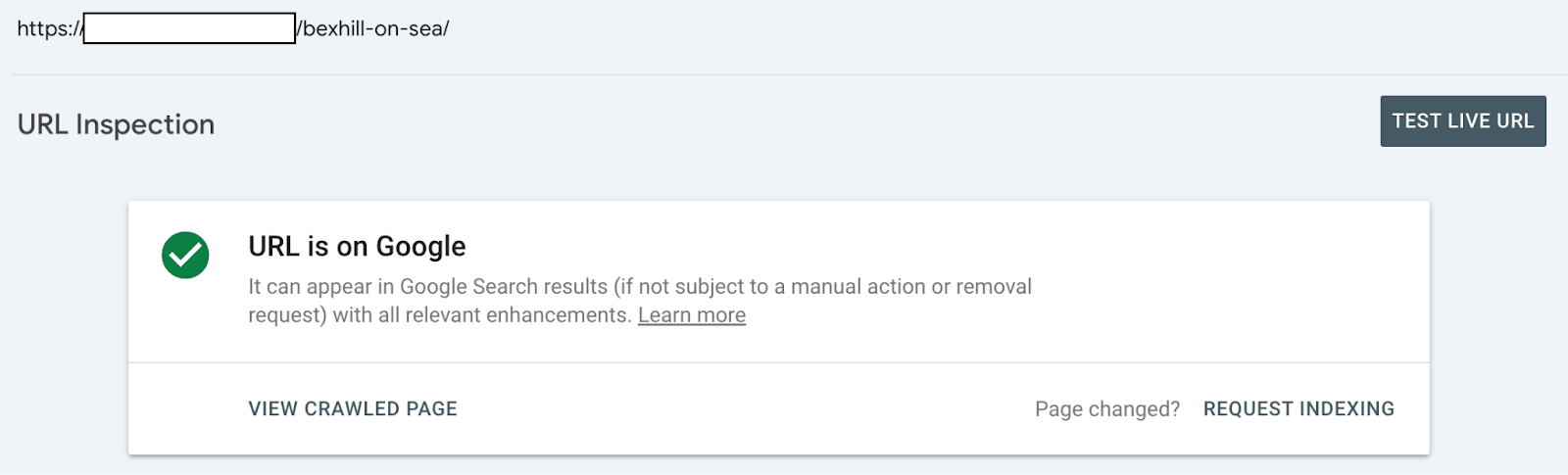
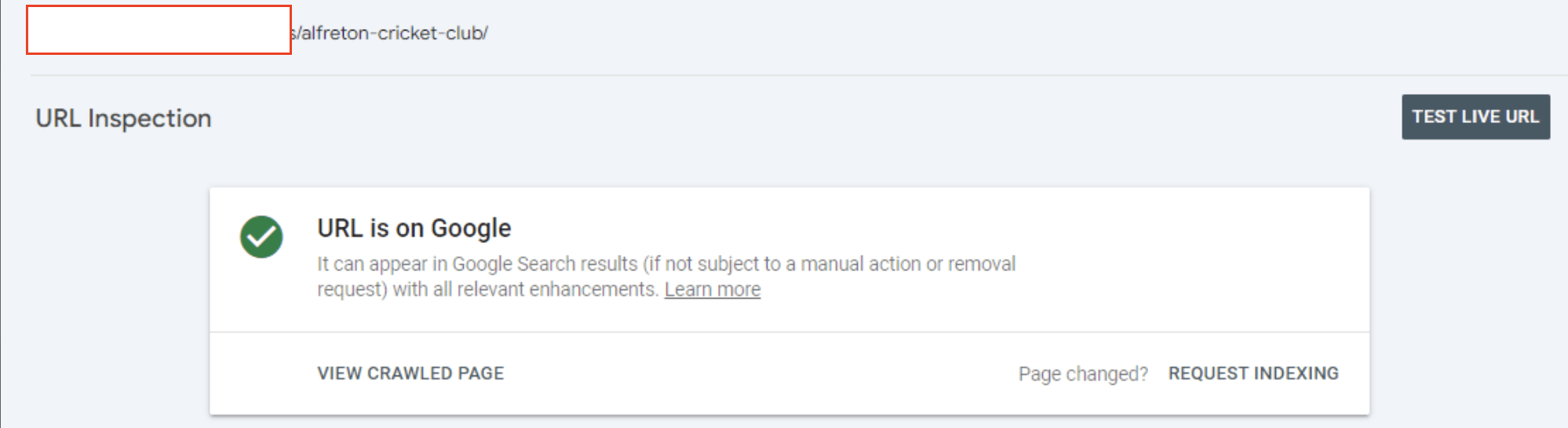
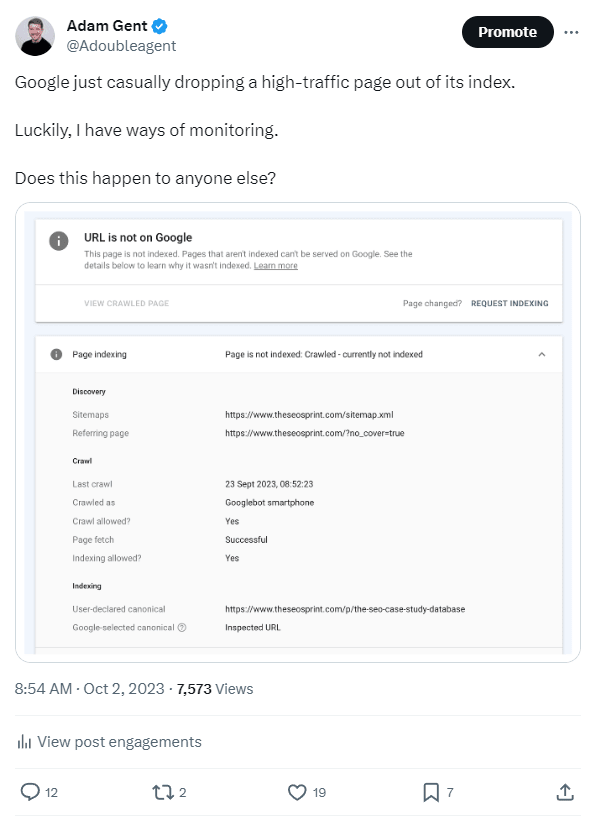
If a page is marked as NotIndexed it’s eligible to appear in Google’s search results.
This means that the content and page URL will not be served to users in Google’s search engine results. And you can see the reasons why the processed pages are not eligable to appear in Google search engine results.
Summary
The Page Indexing report in Google Search Console is widely misunderstood by SEO professionals and business teams.
Many think it shows pages stored in Google’s index and not stored in the index.
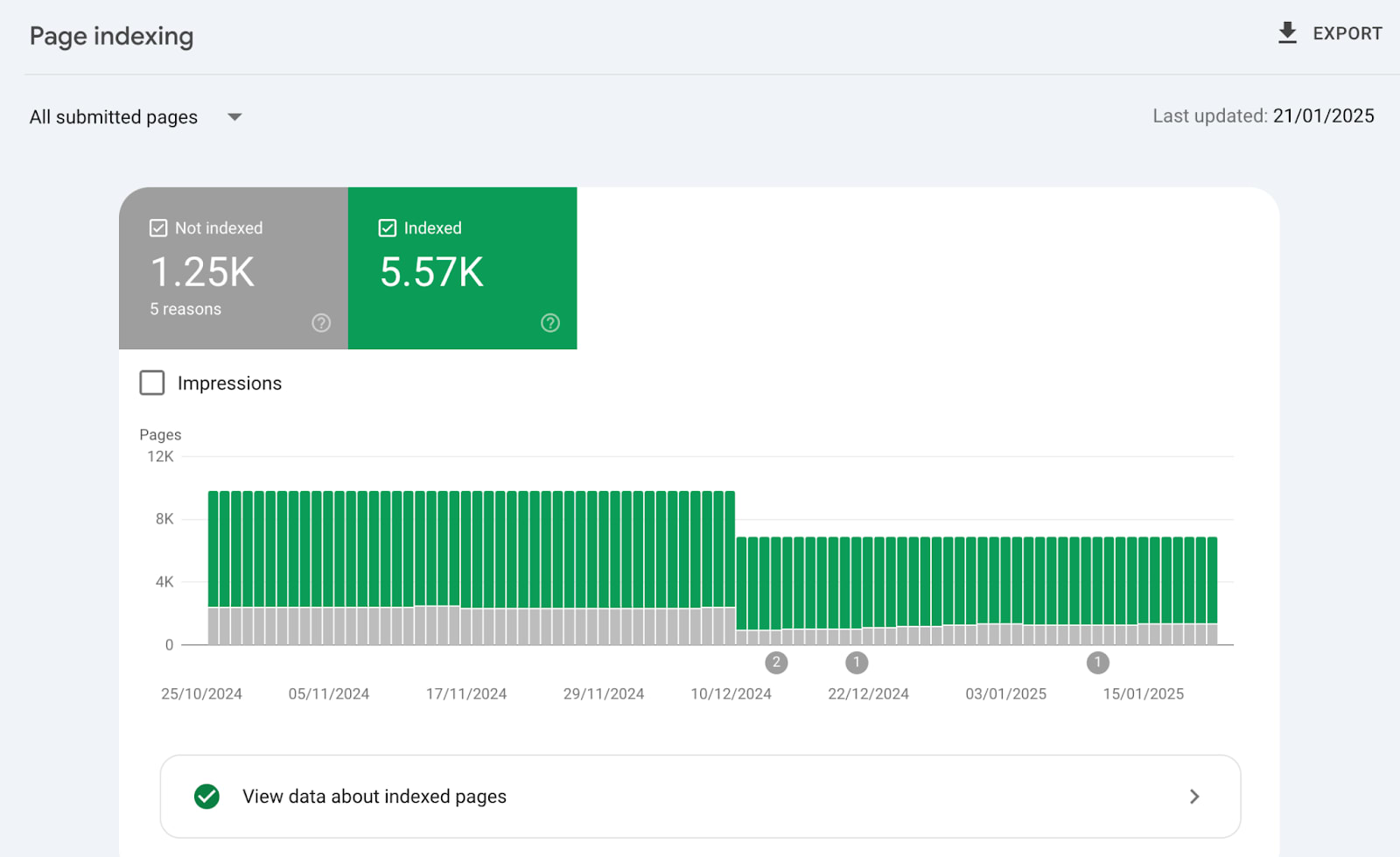
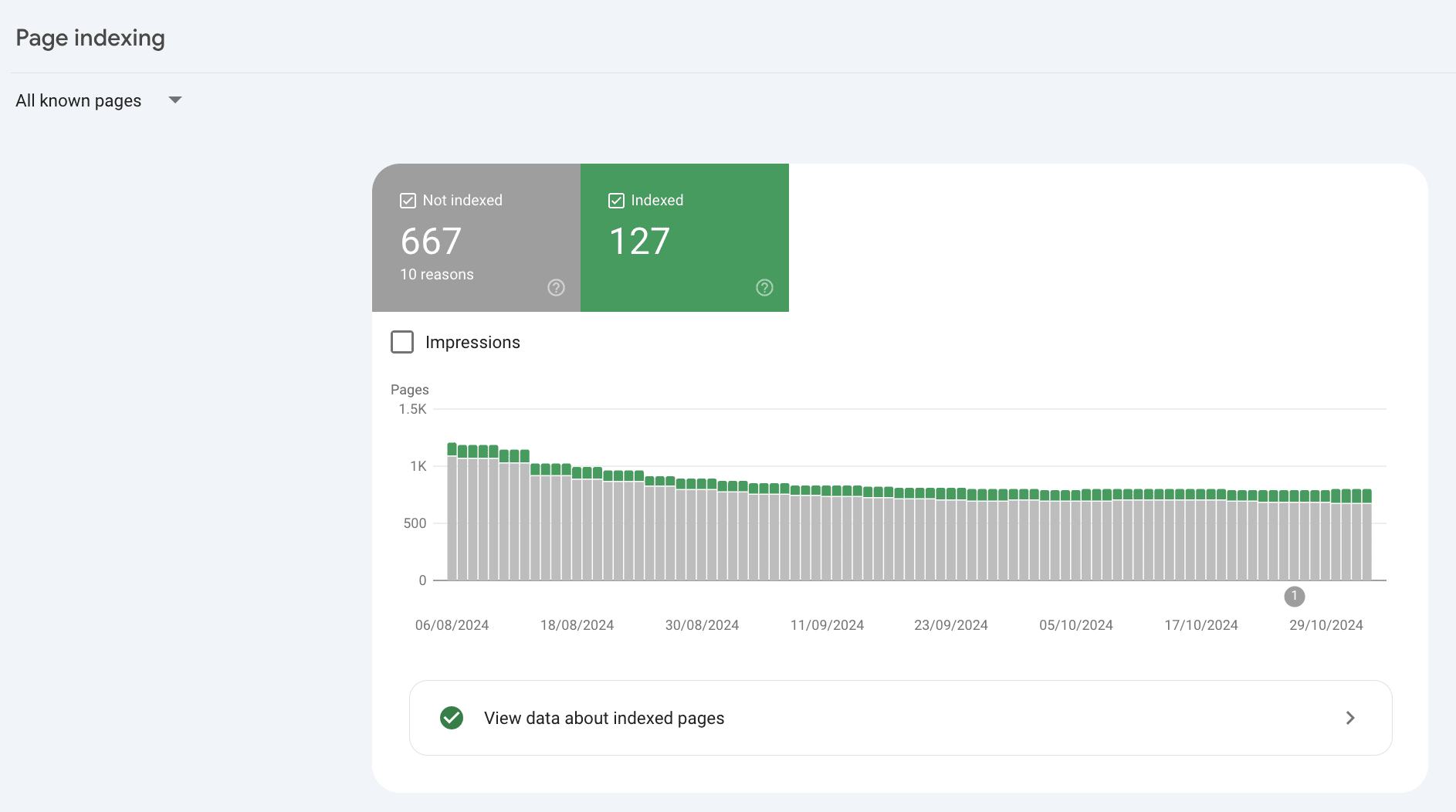
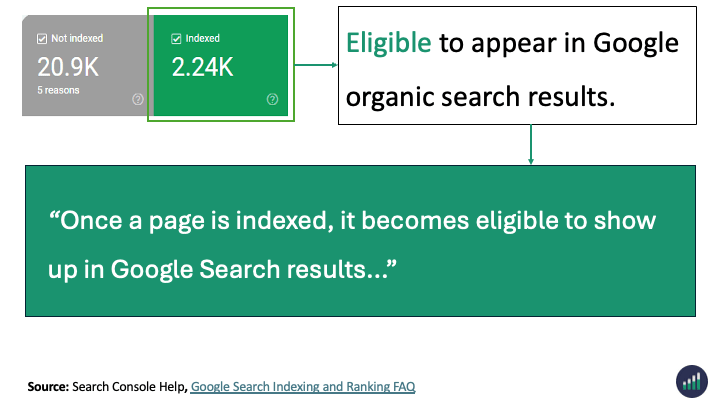
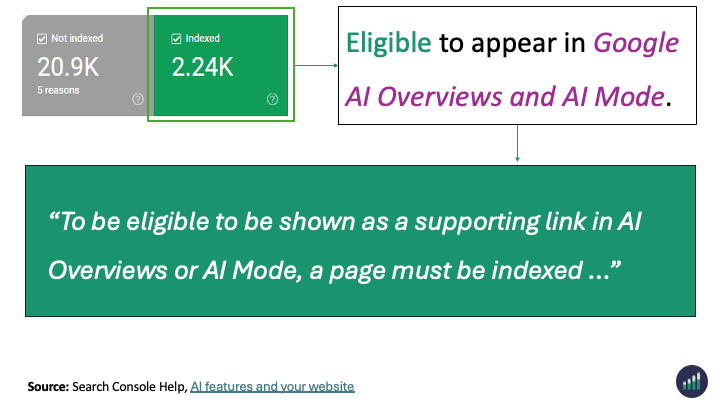
In reality the Page Indexing Report shows all the processed pages in Google’s Search index about a website. Not just the indexed pages.
The difference between Indexed vs Not Indexed is:
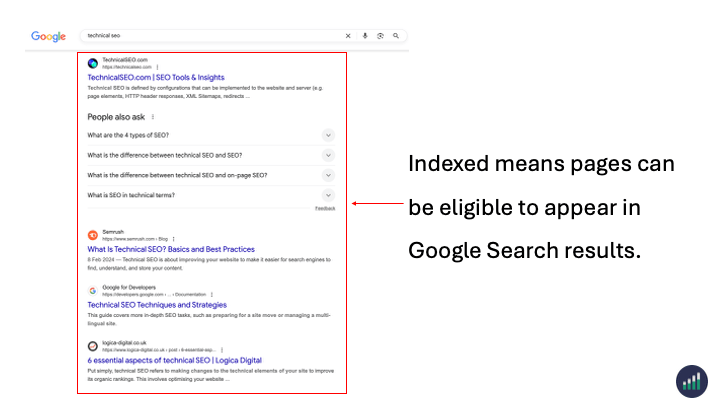
Indexed - Eligible to appear in Google’s search results.
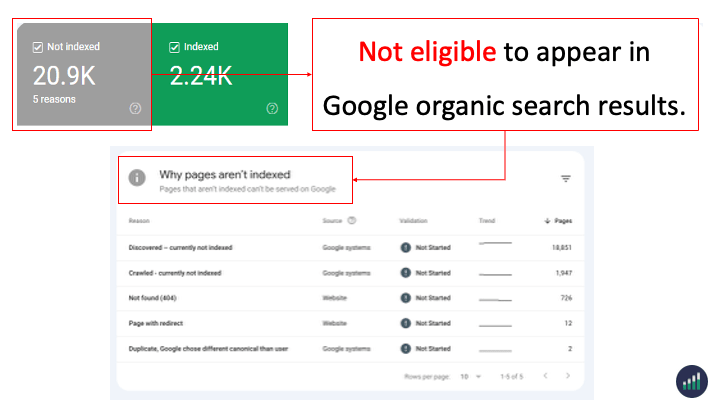
Not Indexed - Not Eligible to appear in Google’s search results.
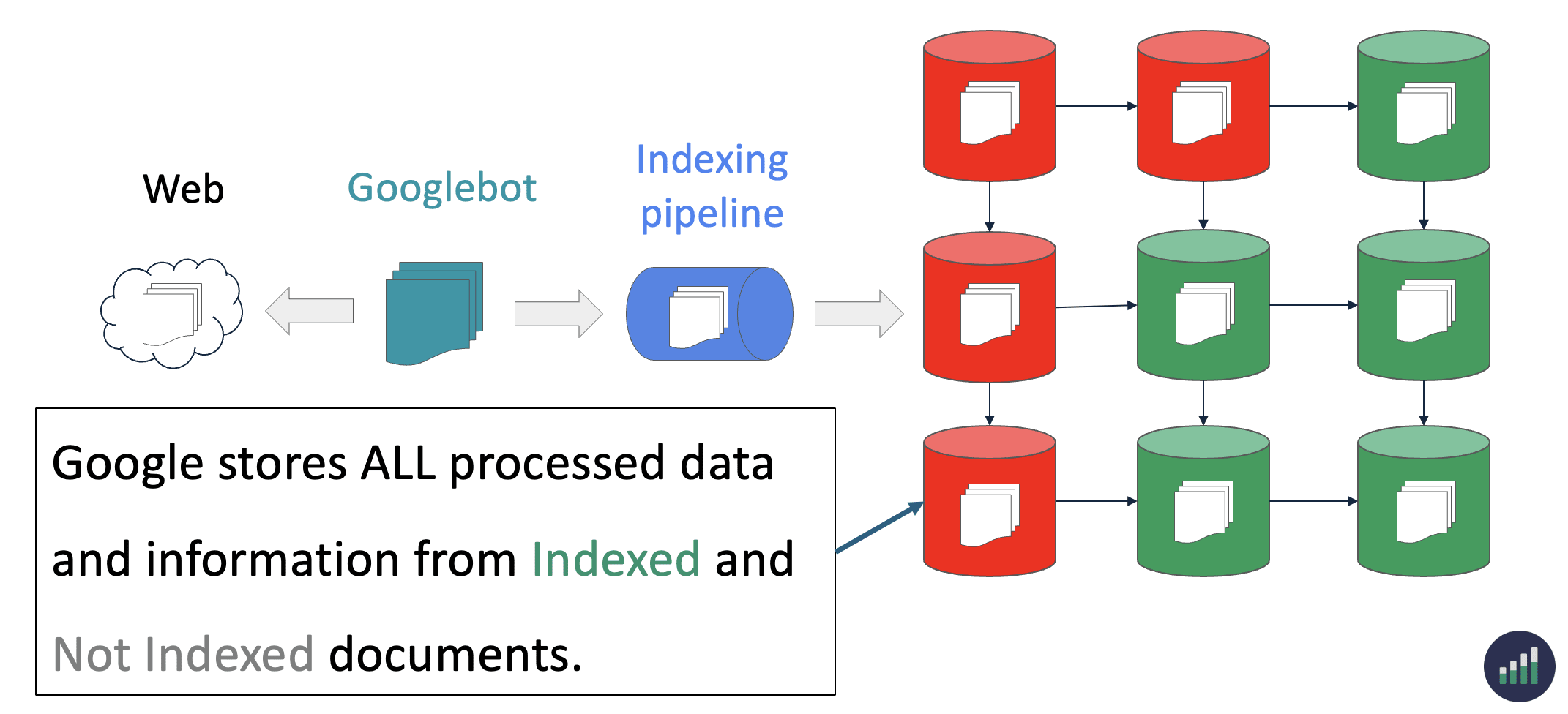
Everything in the Page Indexing report is processed and stored in Google’s index.
What you’re looking at are pages that have the potential to be shown to users in search results and pages that Google has decided NOT to show to users.
Do you want to monitor Google indexing and crawling at scale?
Indexing Insight is a Google indexing intelligence tool for SEO teams who want to identify, prioritise and fix indexing issues at scale.
At Indexing Insight, we noticed a HUGE number of pages being actively removed from Google's search results at the end of May 2025.
This indexing purge was so large it caused many SEO professionals to notice that entire websites were being actively removed from Google's search index.
However, the current understanding of this purge is incomplete.
In this newsletter, I'll explain what really happened during the May 2025 index purge and why Google's official explanation doesn't tell the whole story.
I'll show evidence that this wasn't just "normal fluctuation" but one of the largest content purge we've ever tracked.
So, let's dive in.
Search Index Update Findings
I’ve broken down the findings and analysis into 5 parts:
Google indexing purge
25% of monitored pages were actively removed
Google broke the 130-Day Indexing rule
15% - 75% of indexed pages removed
Why Google removed the pages
🔥 Google indexing purge
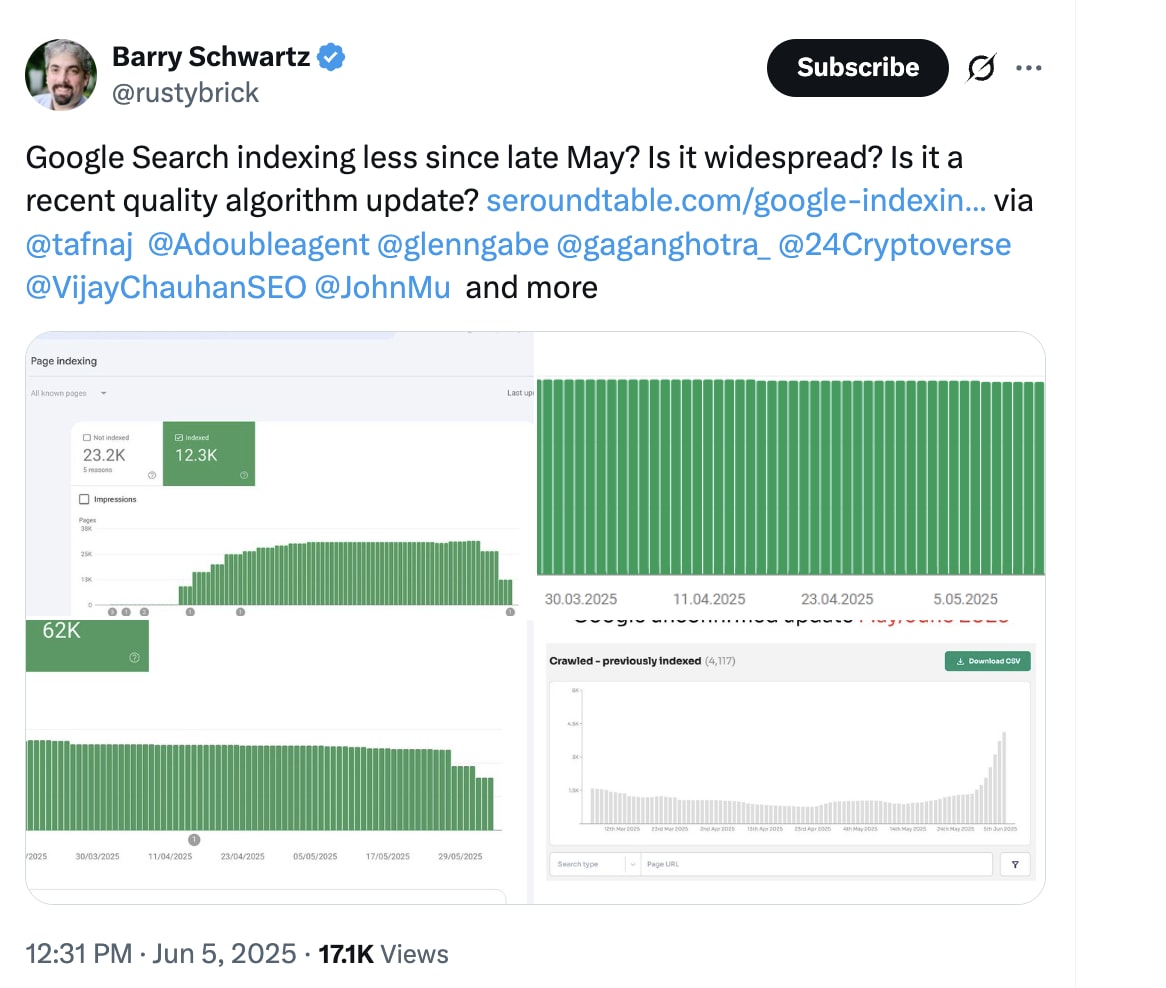
At the end of May 2025, we noticed a massive increase in the number of pages that were being actively removed by Google’s Search index.
The reaction to the quick post on LinkedIn, and on Twitter, was massive.
Many people reached out to me and provided screenshots of their Page Indexing report in Google Search Console.
This story, and screenshots, were also picked up by Barry Schwartz on SEORoundtable.
Whatever Google did at the end of May 2025 it had a huge impact on a large portion of its index. And caused many websites to have their indexed pages to be removed from Google’s index.
But why were these pages removed? And is this different to any other Google core update?
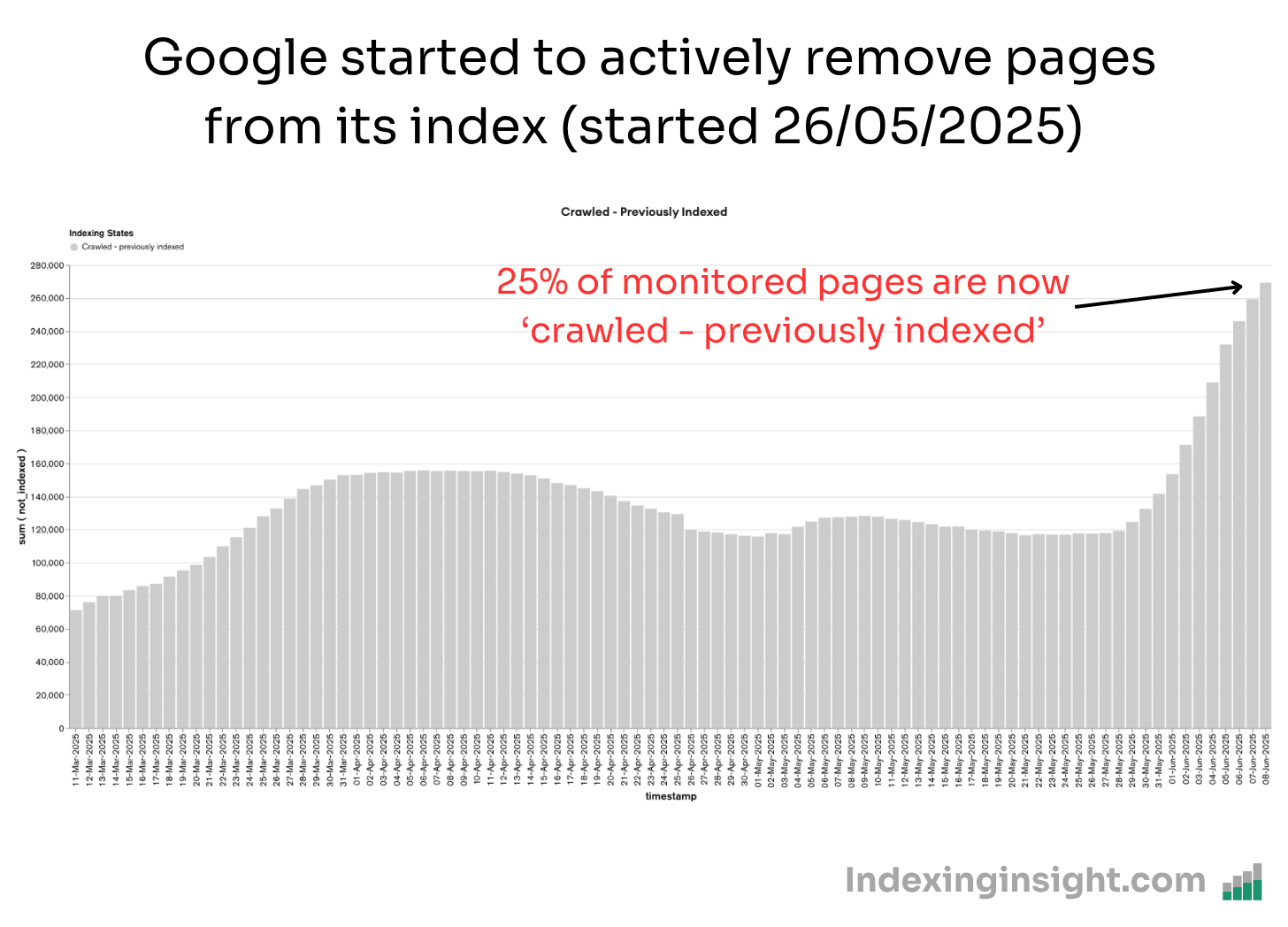
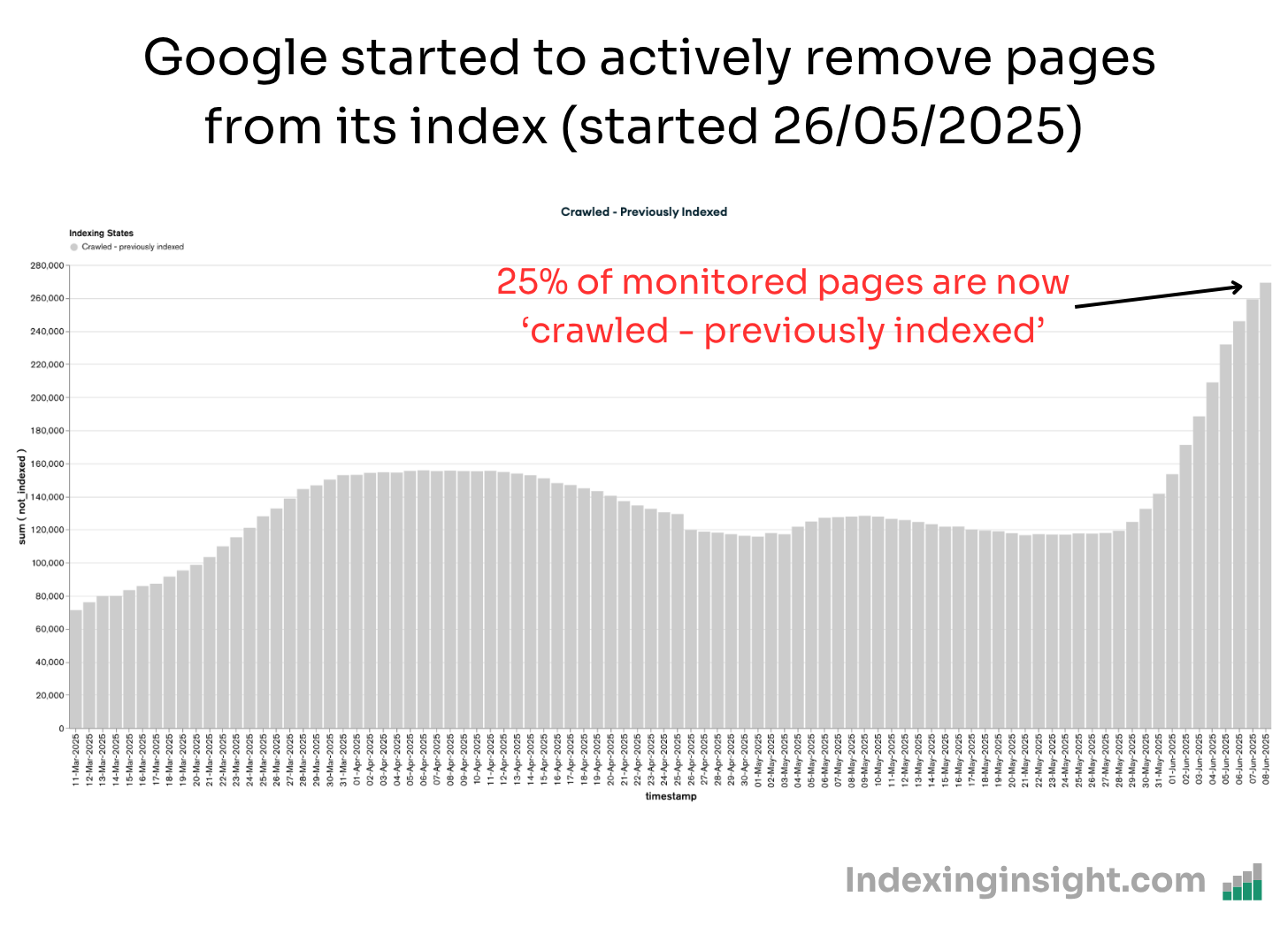
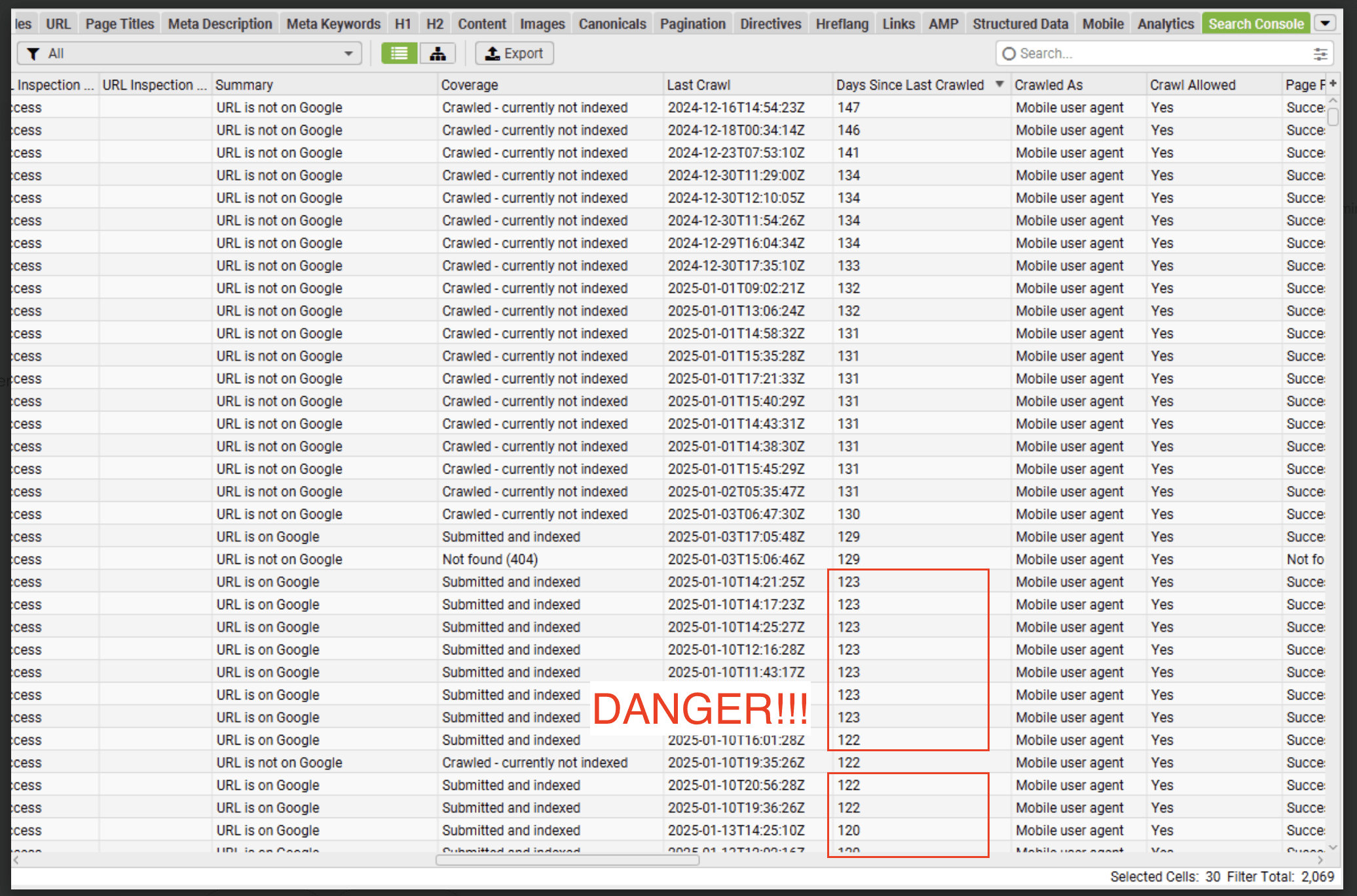
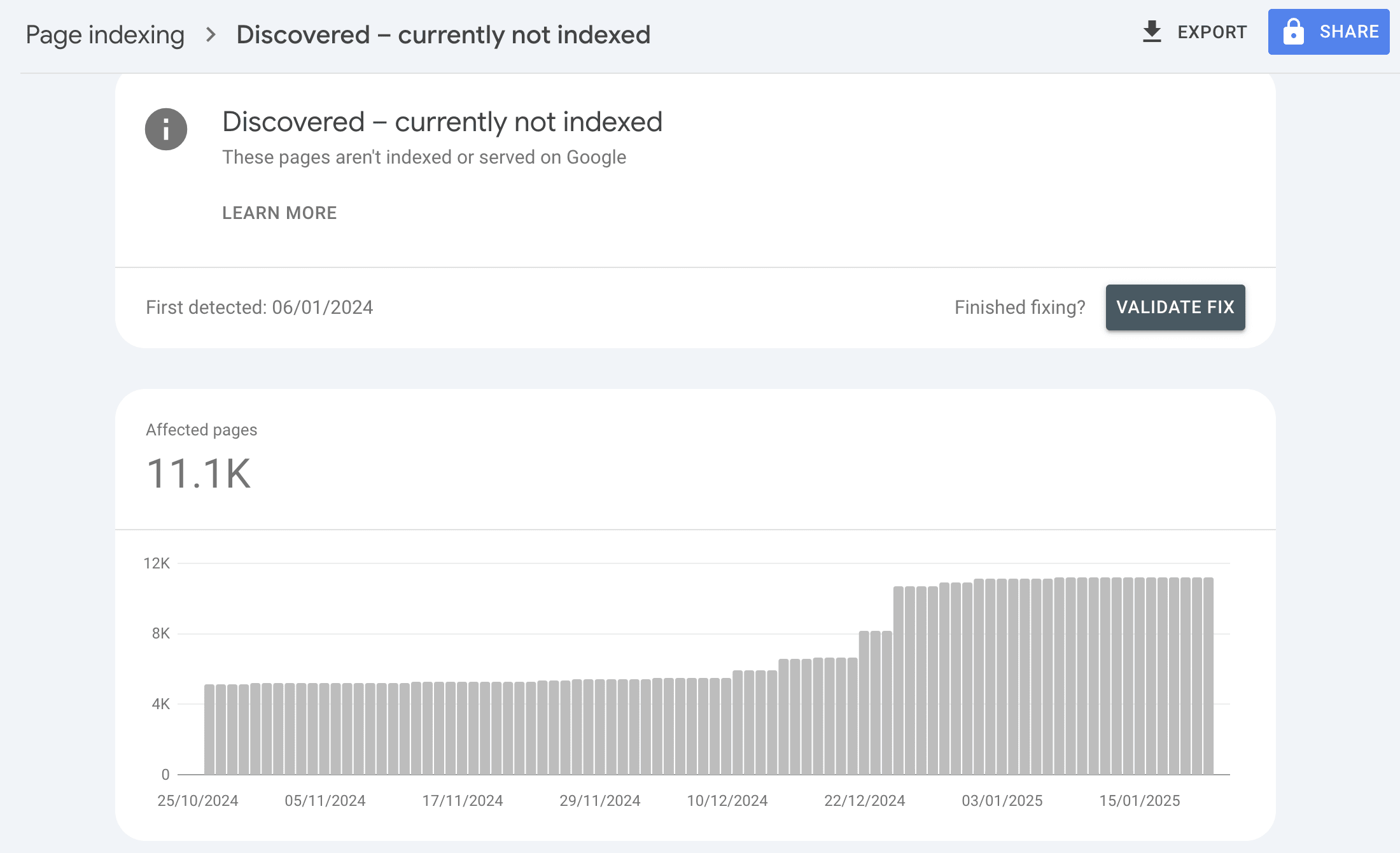
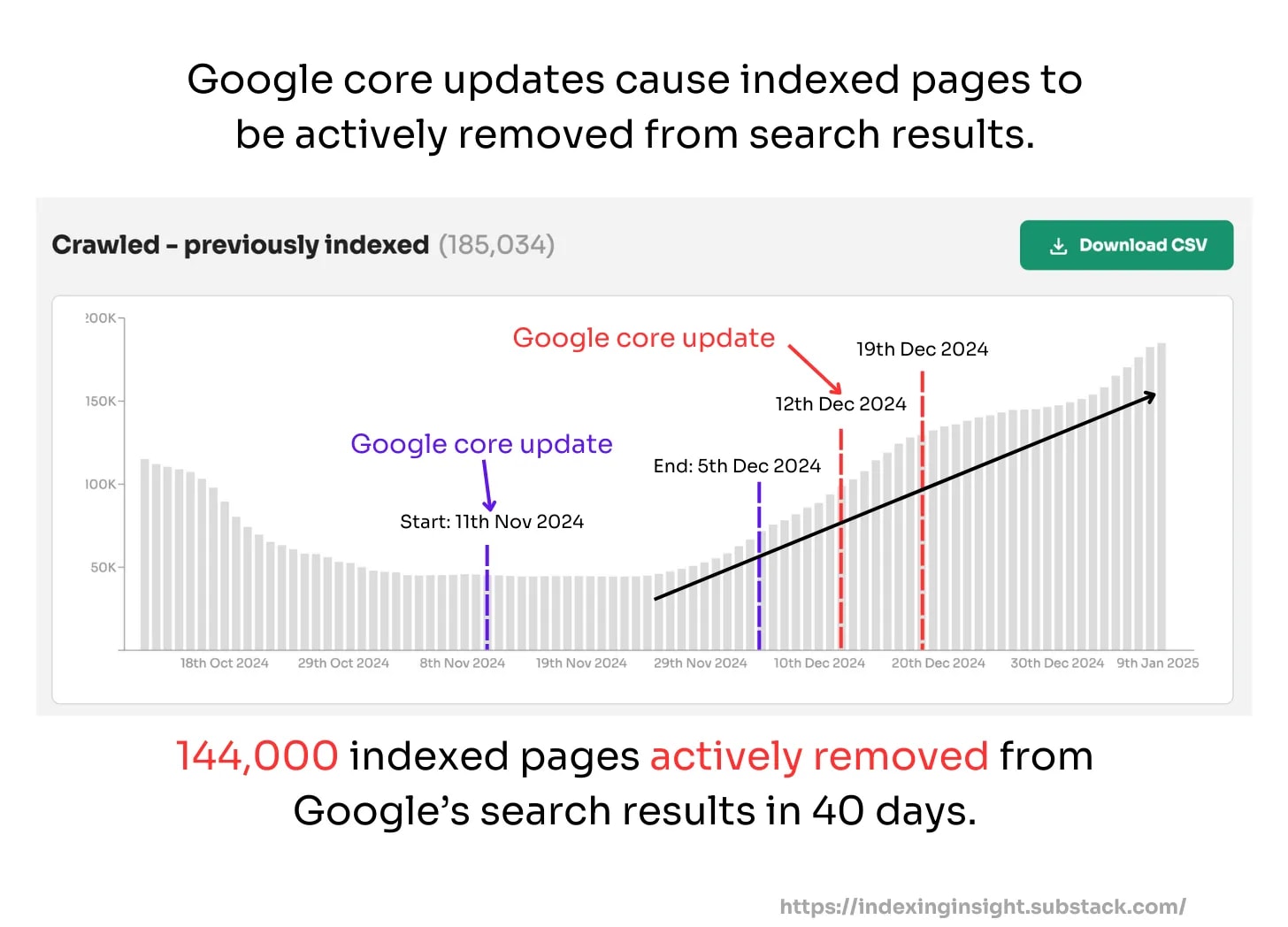
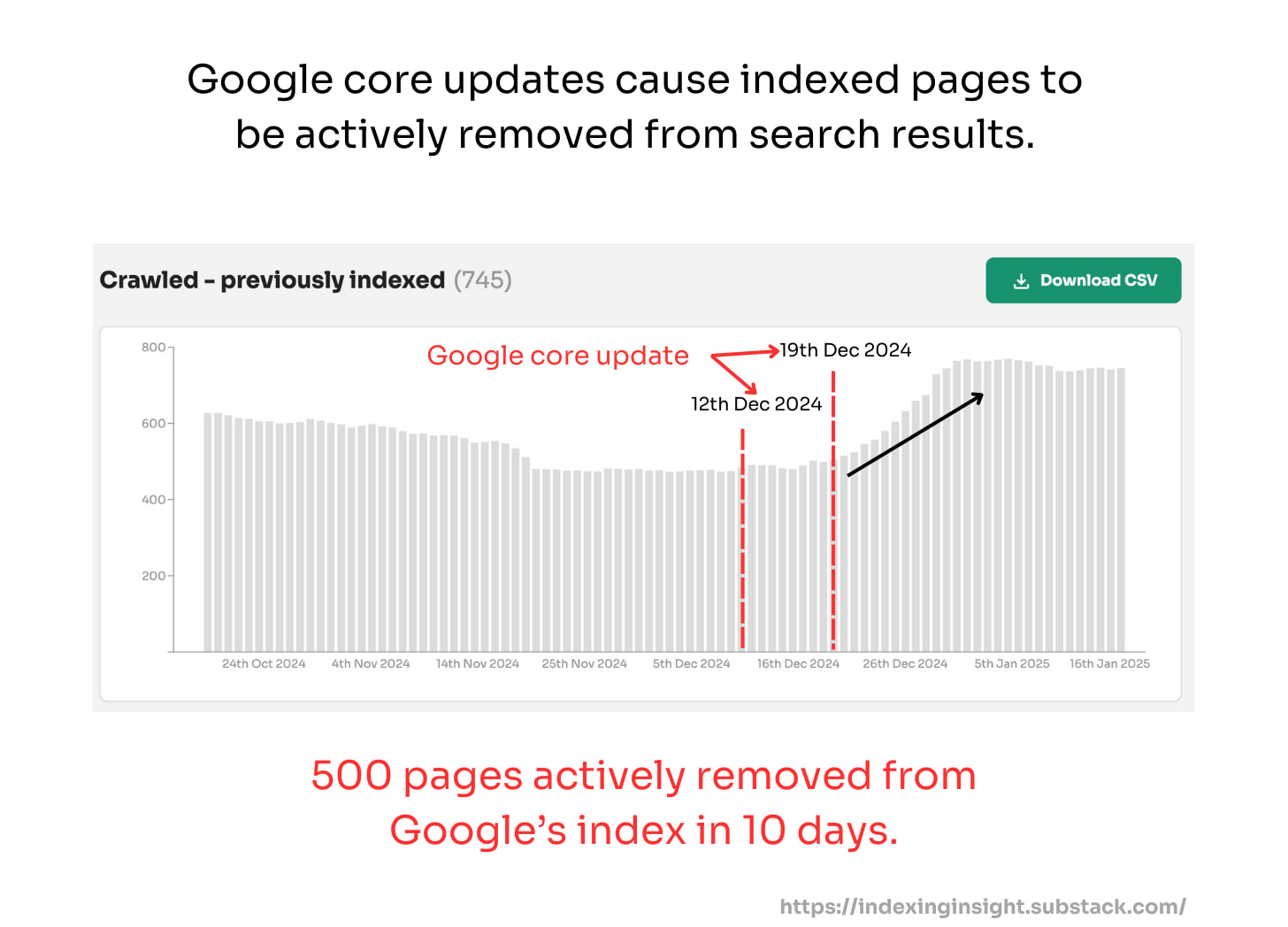
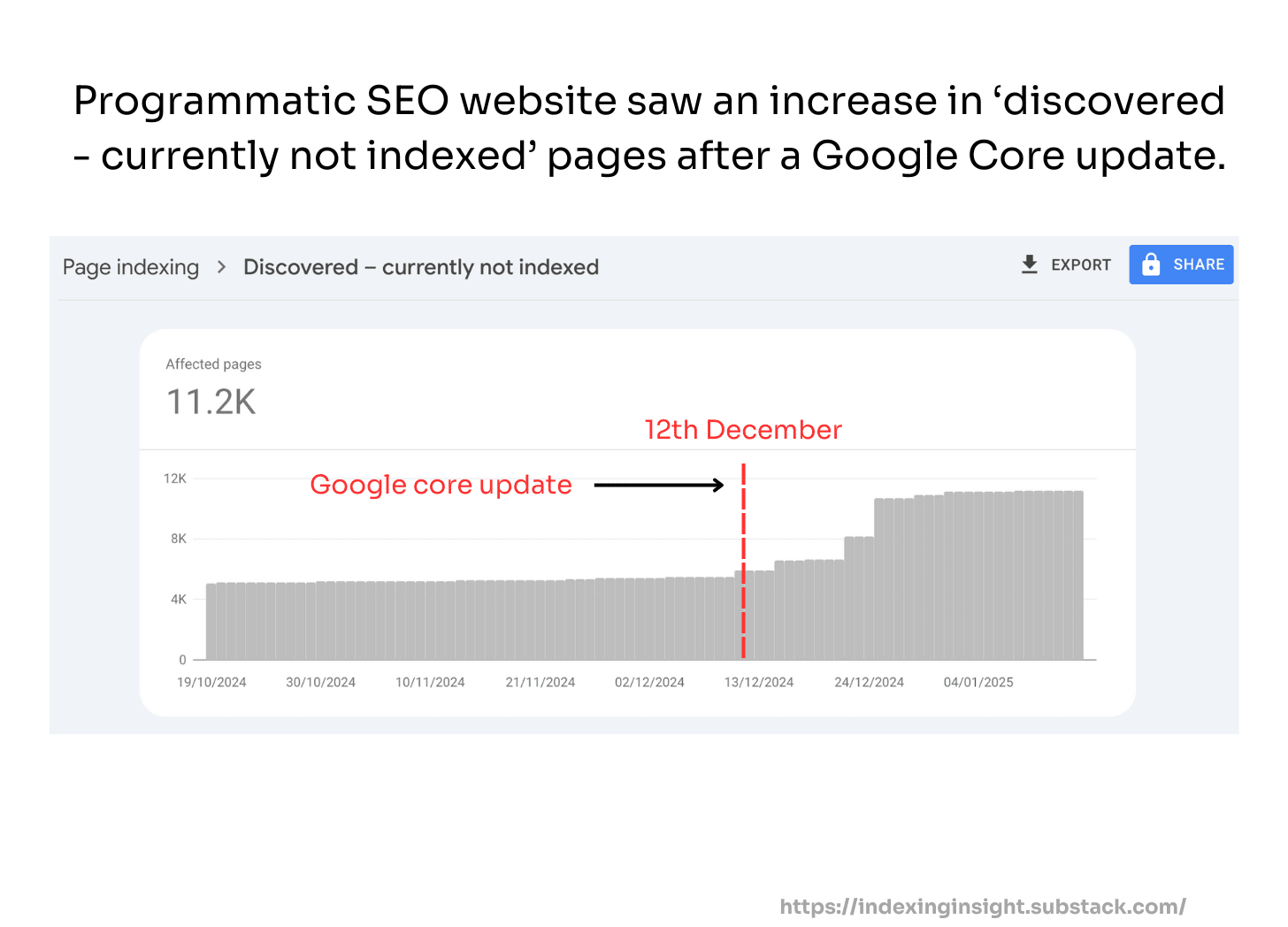
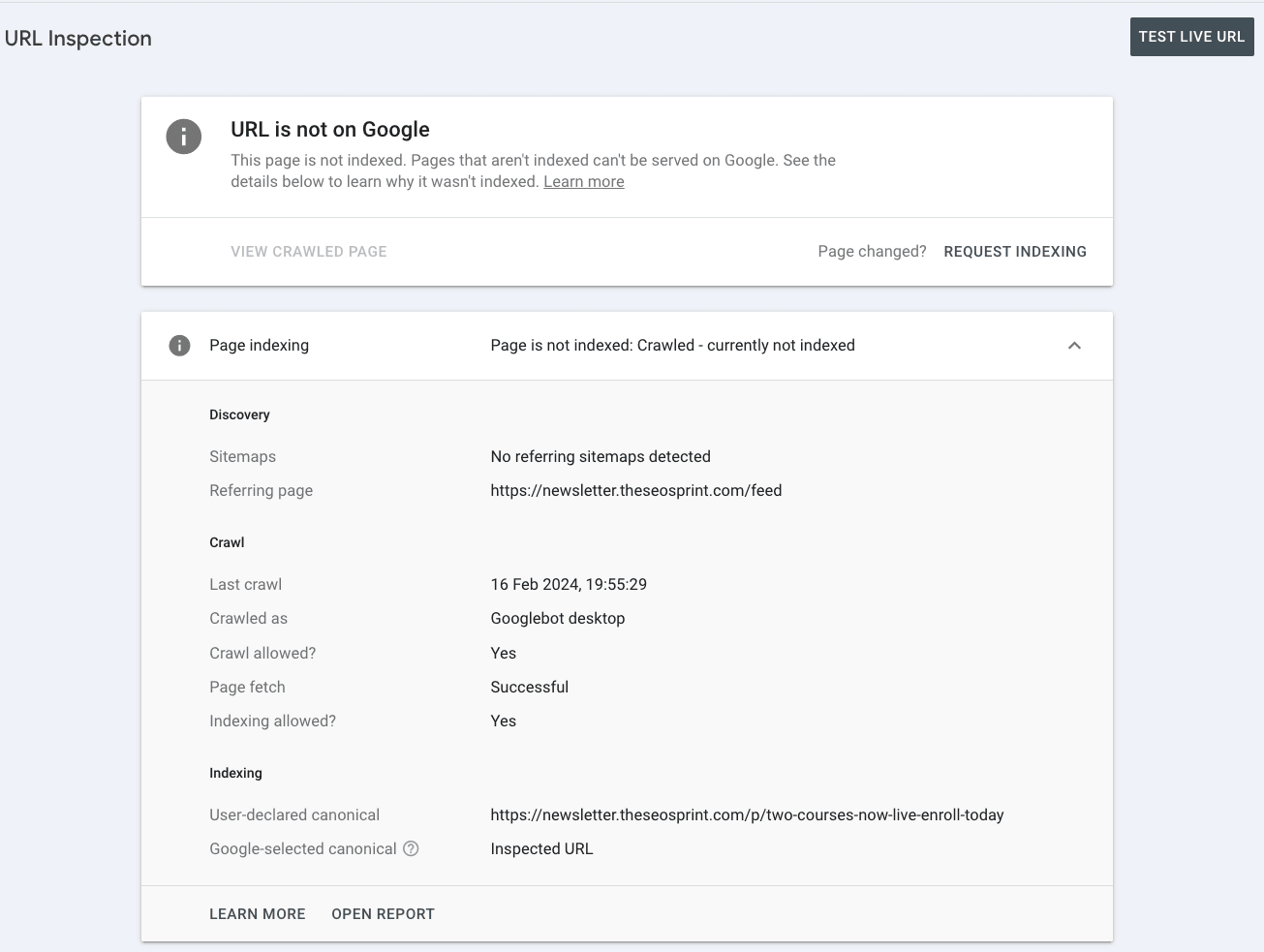
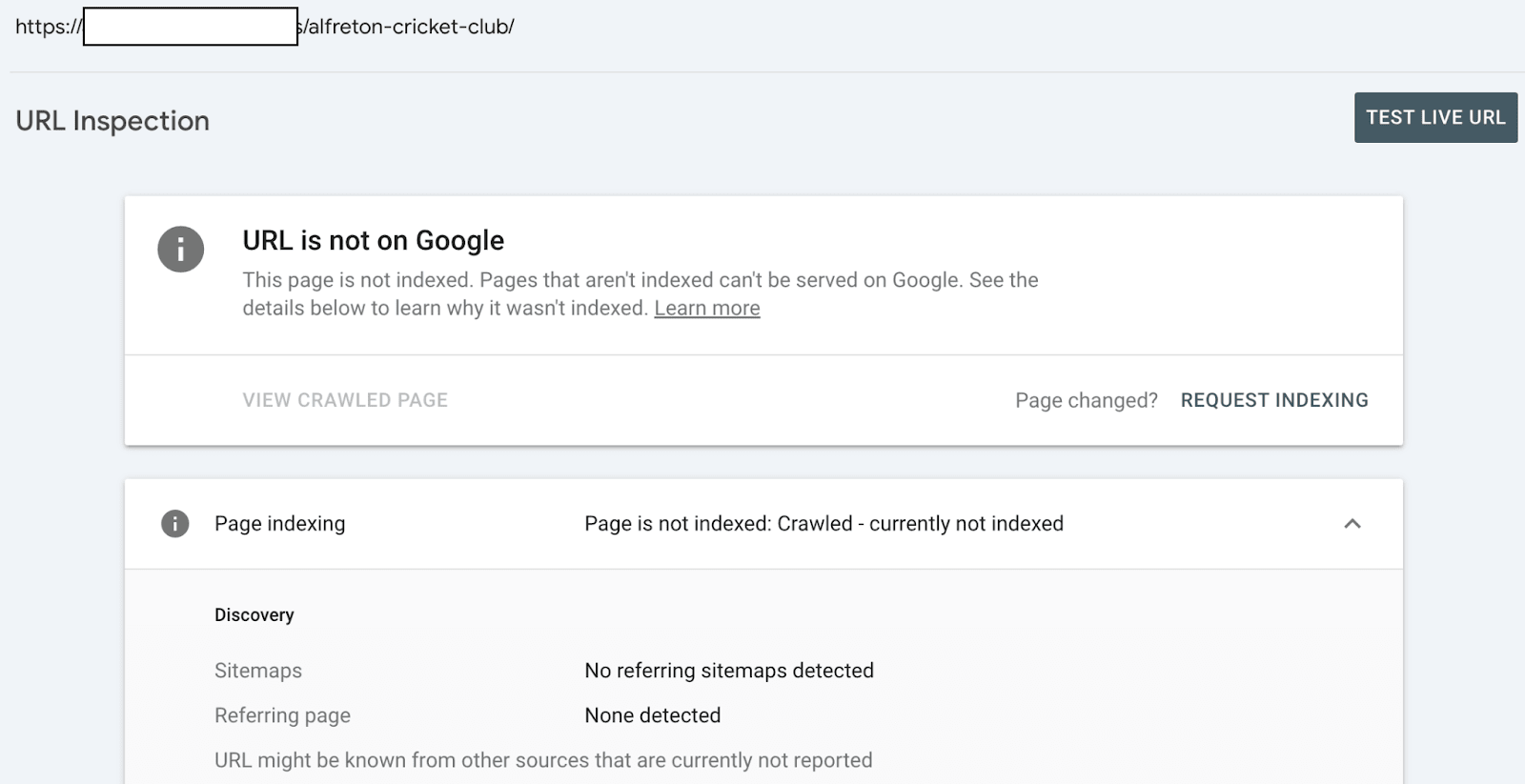
Since May 26th 2025 over 25% of monitored URLs have the indexing state ‘crawled - previously indexed’.
When an indexed page is actively removed from Google’s Search results the indexing state changes from ‘submitted and indexed’ to ‘crawled - currently not indexed’.
Since monitoring back in early 2024 we have not seen this level of active removal by Google across SO many websites.
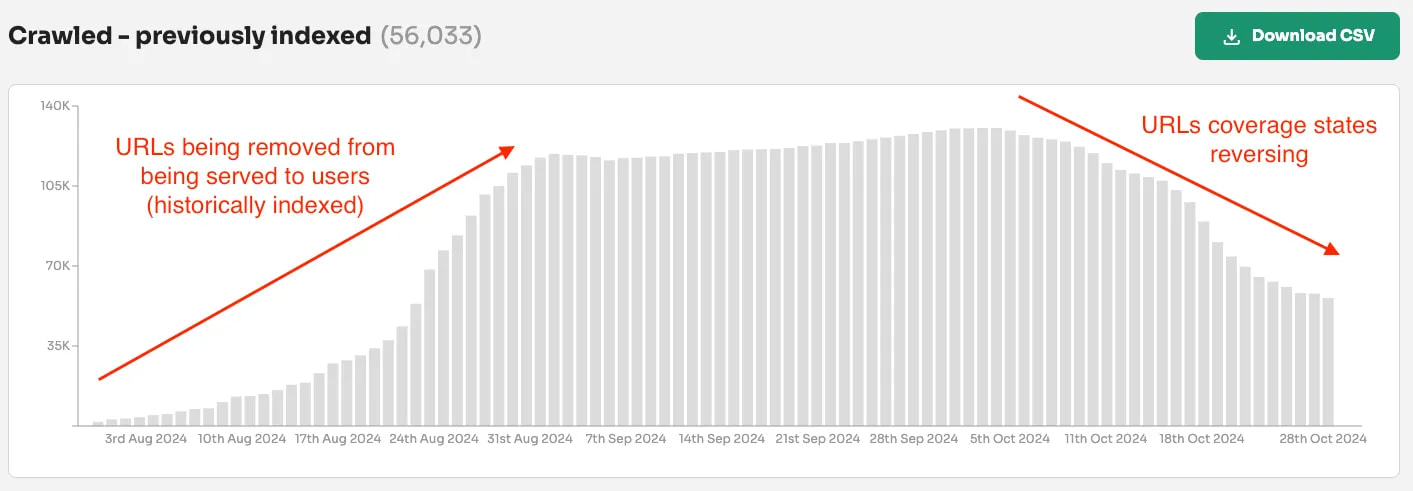
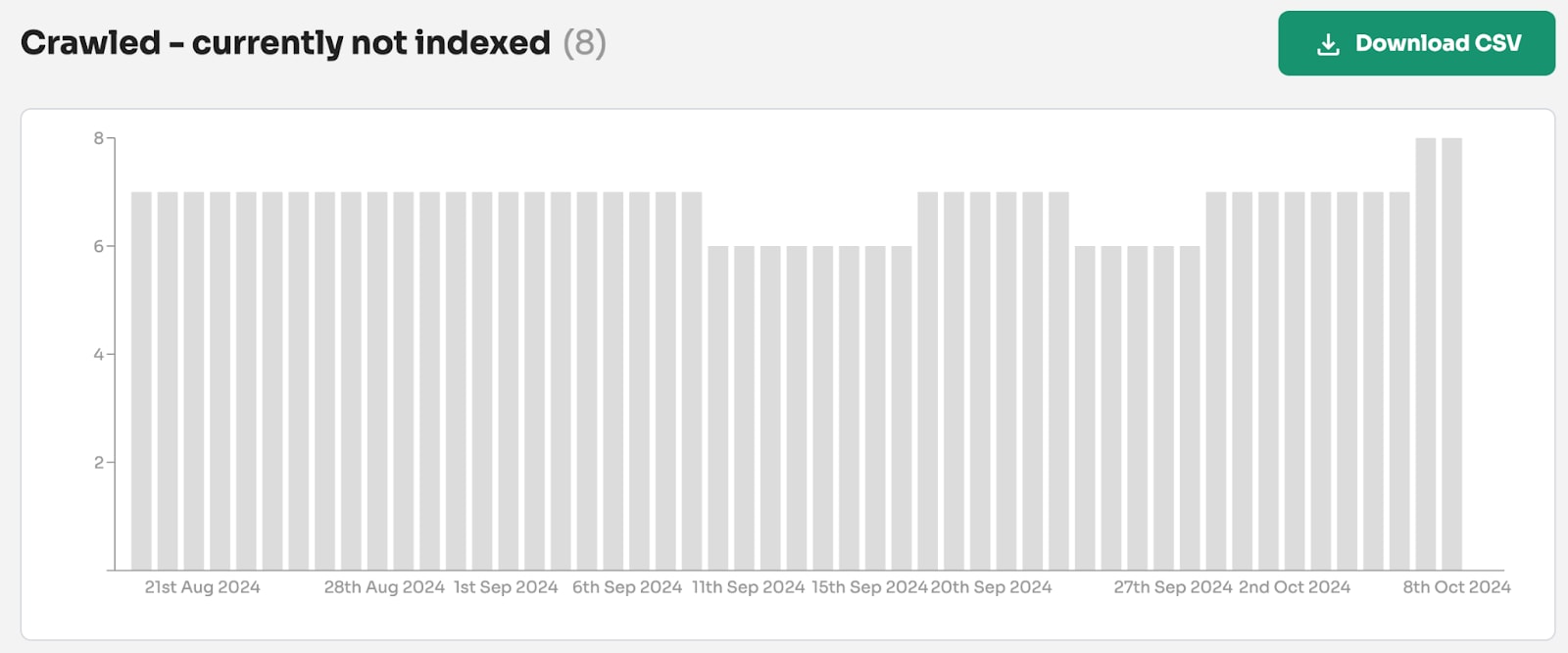
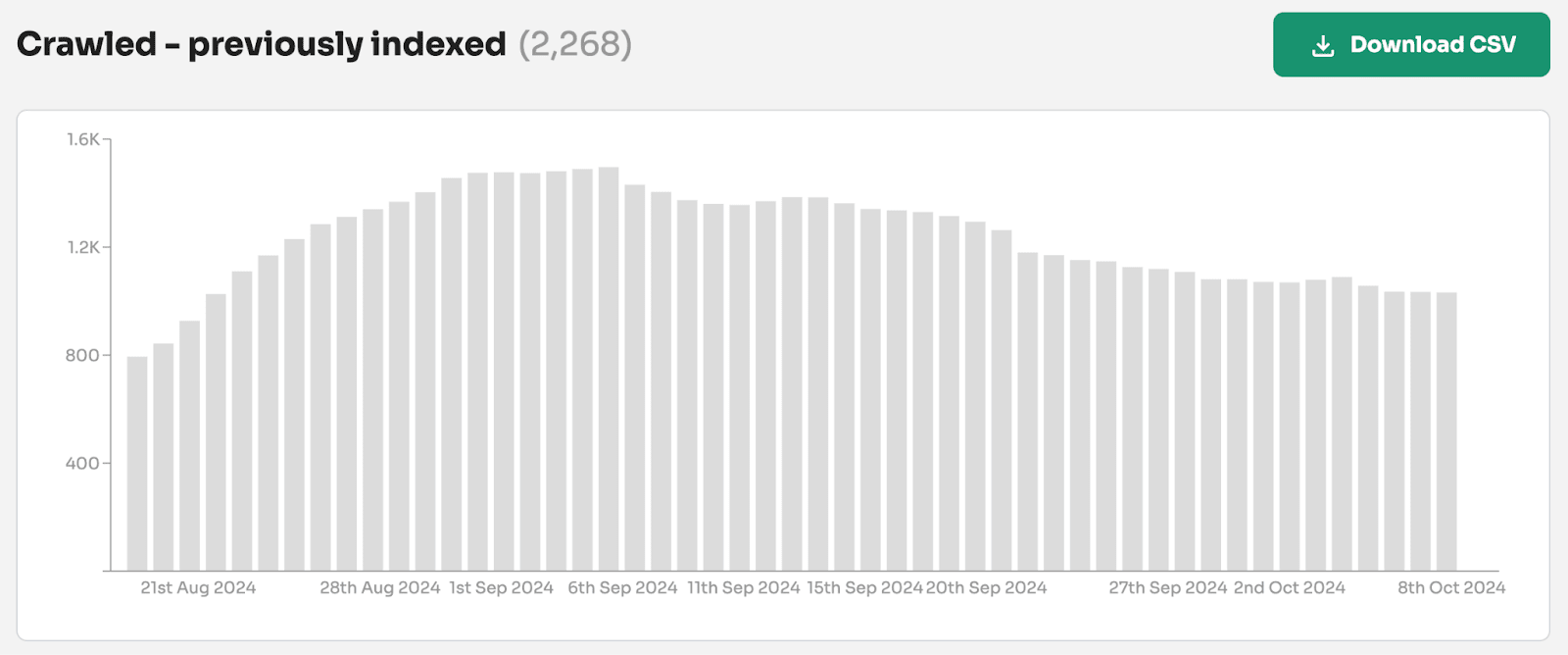
Note: At Indexing Insight we noticed this pattern over a year ago and we created a new report ‘crawled - previously indexed’.
This new report helps our customers to identify exactly which pages are being actively removed from Google’s search results. And it’s this data that can be aggregated together and be shown over the last 90 days.
♻️ Google broke the 130-Day Indexing Rule
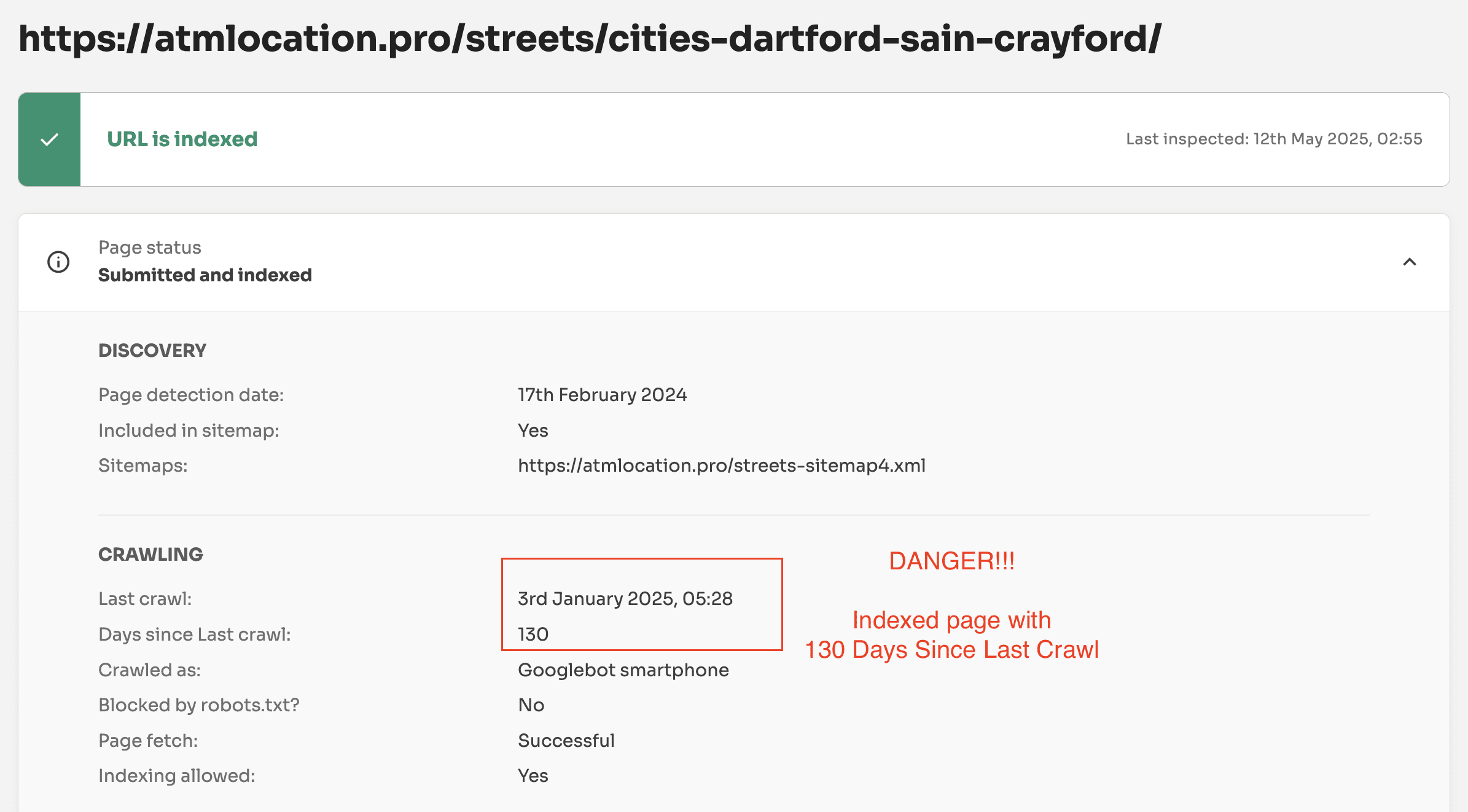
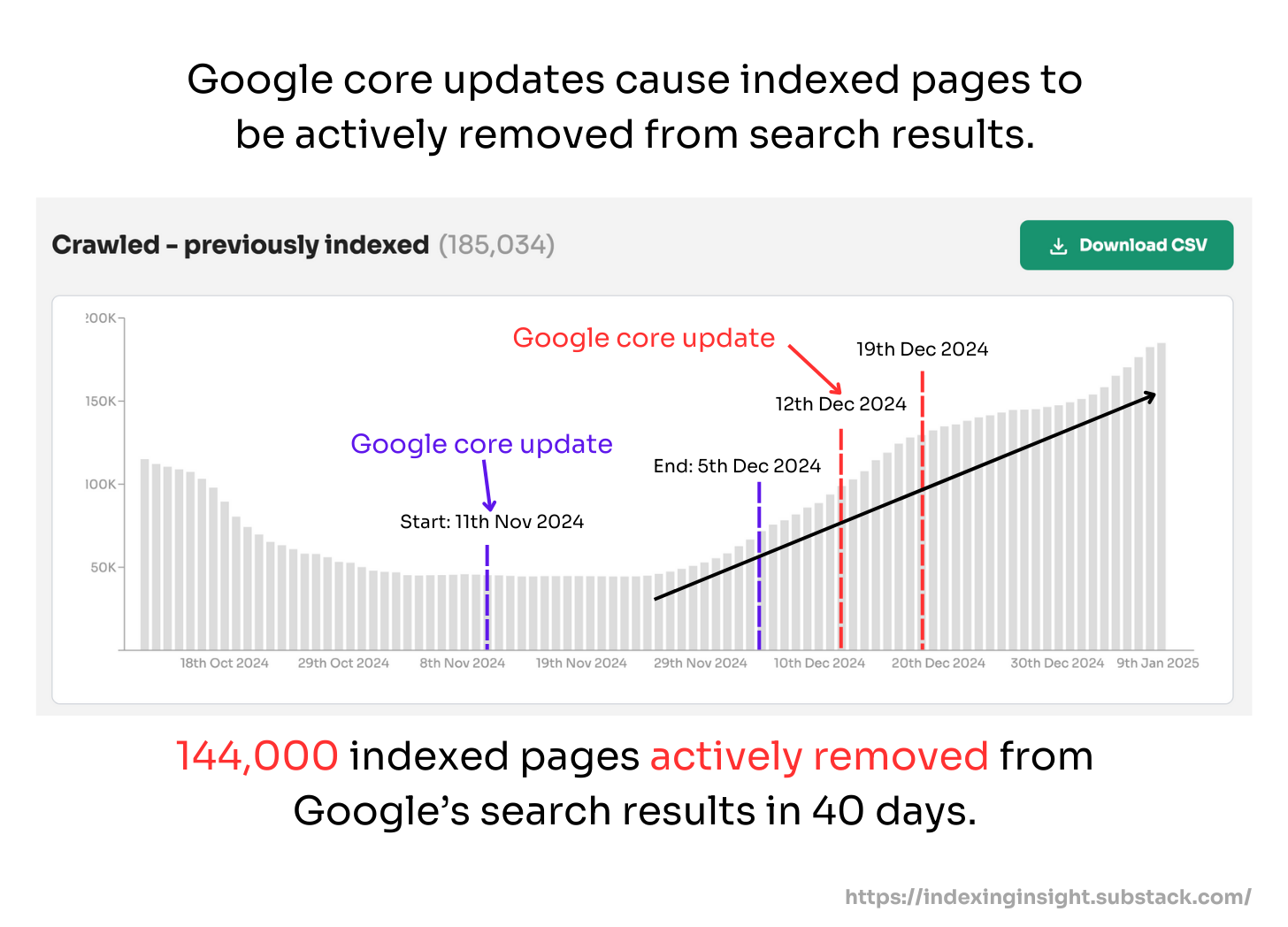
Google recrawled URLs in the last 90-130 days and then actively deindexed pages.
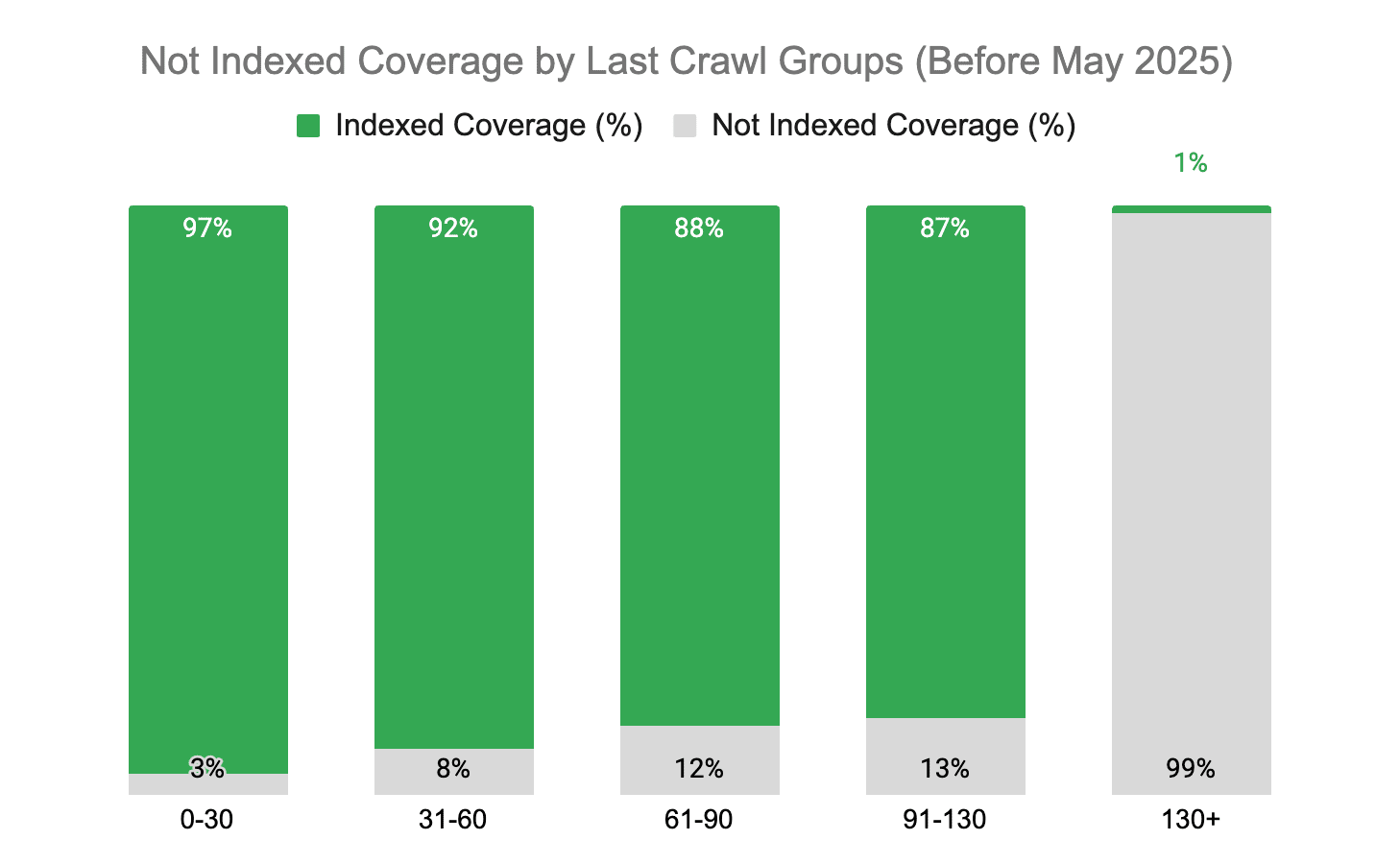
Previously, we (and others) have identified the 130-day indexing rule. The rule is simple: After 130 days of not being crawled a page is actively removed from Google’s search results (going from indexed to not indexed).
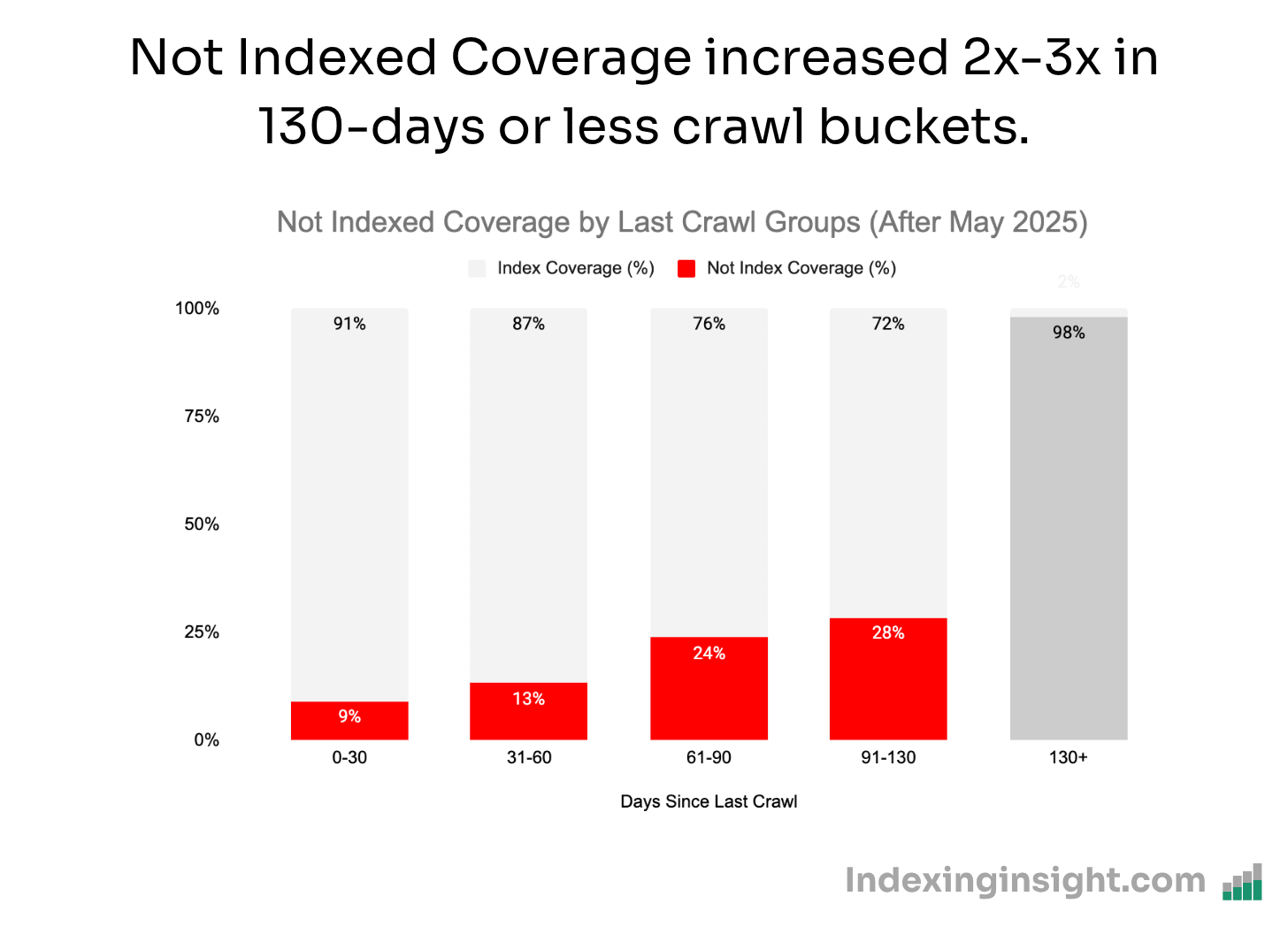
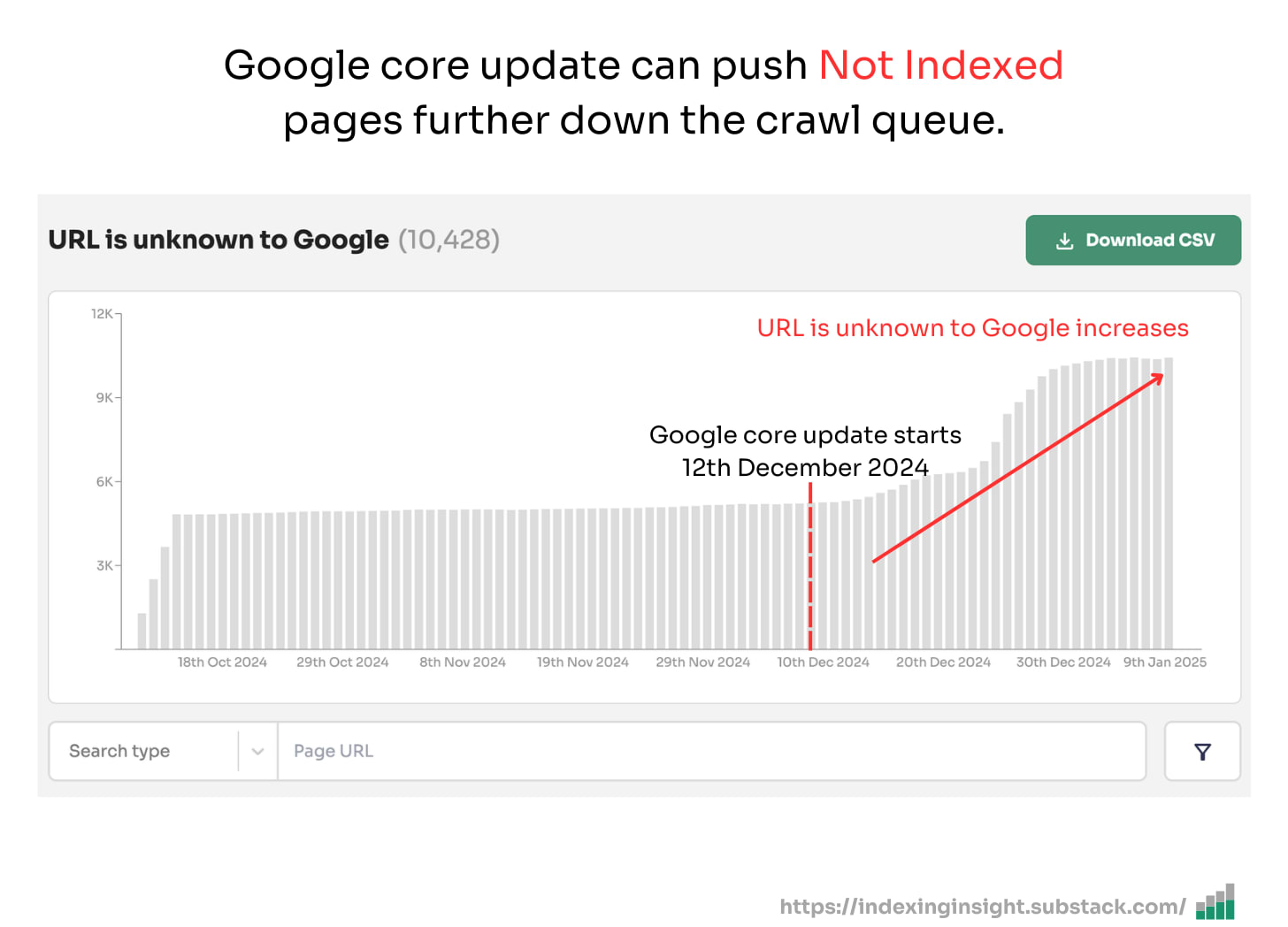
However, starting from May 26th this pattern reversed and it seems Google actively removed pages it had recrawled in 90-130 days.
In fact, comparing the days since last crawl time buckets before and after May 25 reveals that Not Indexed pages doubled or tripled.
What does this mean?
It means that Google didn’t wait the usual 130 days since last crawl to collect signals around these pages.
Instead, Google crawled or recrawled pages over the last 3 months and decided not to wait to deindex pages.
This can be seen in Google Search Console > Crawl Stats report.
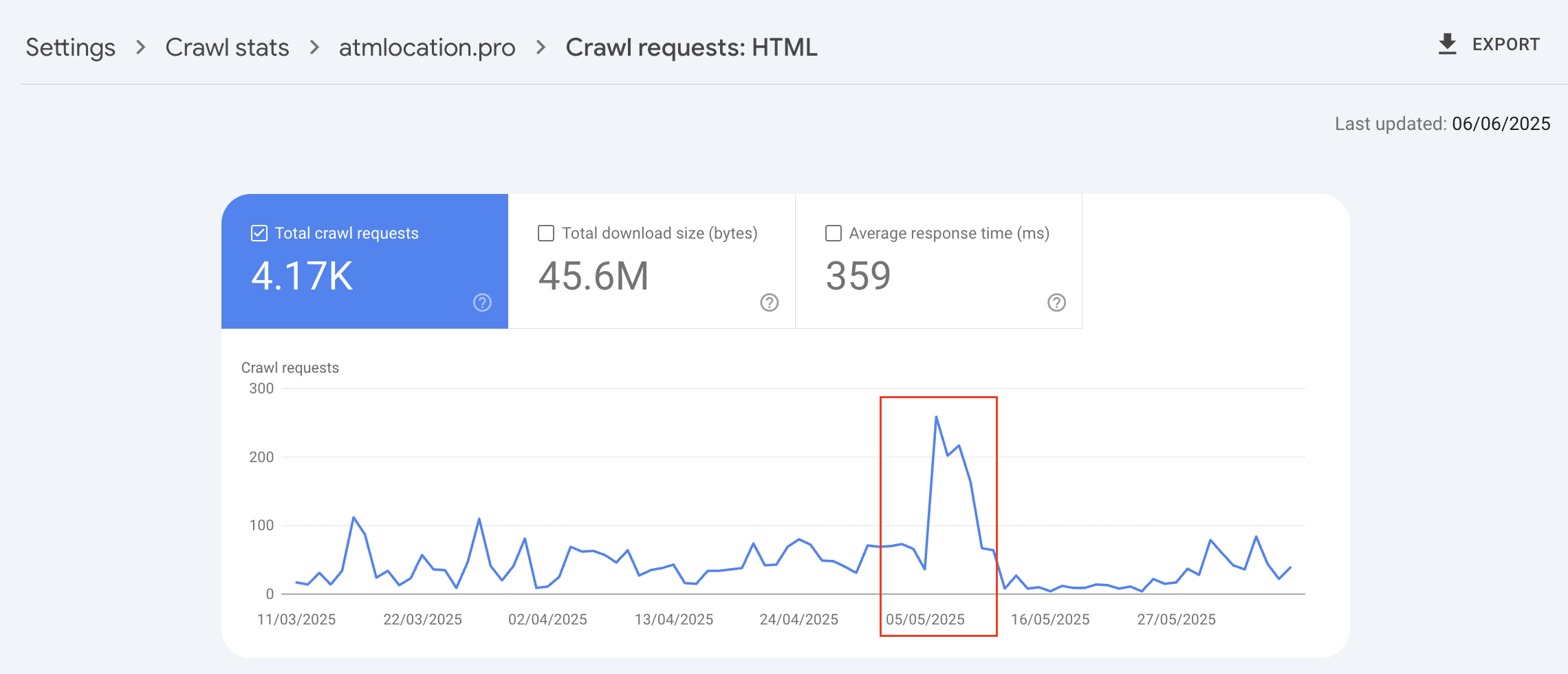
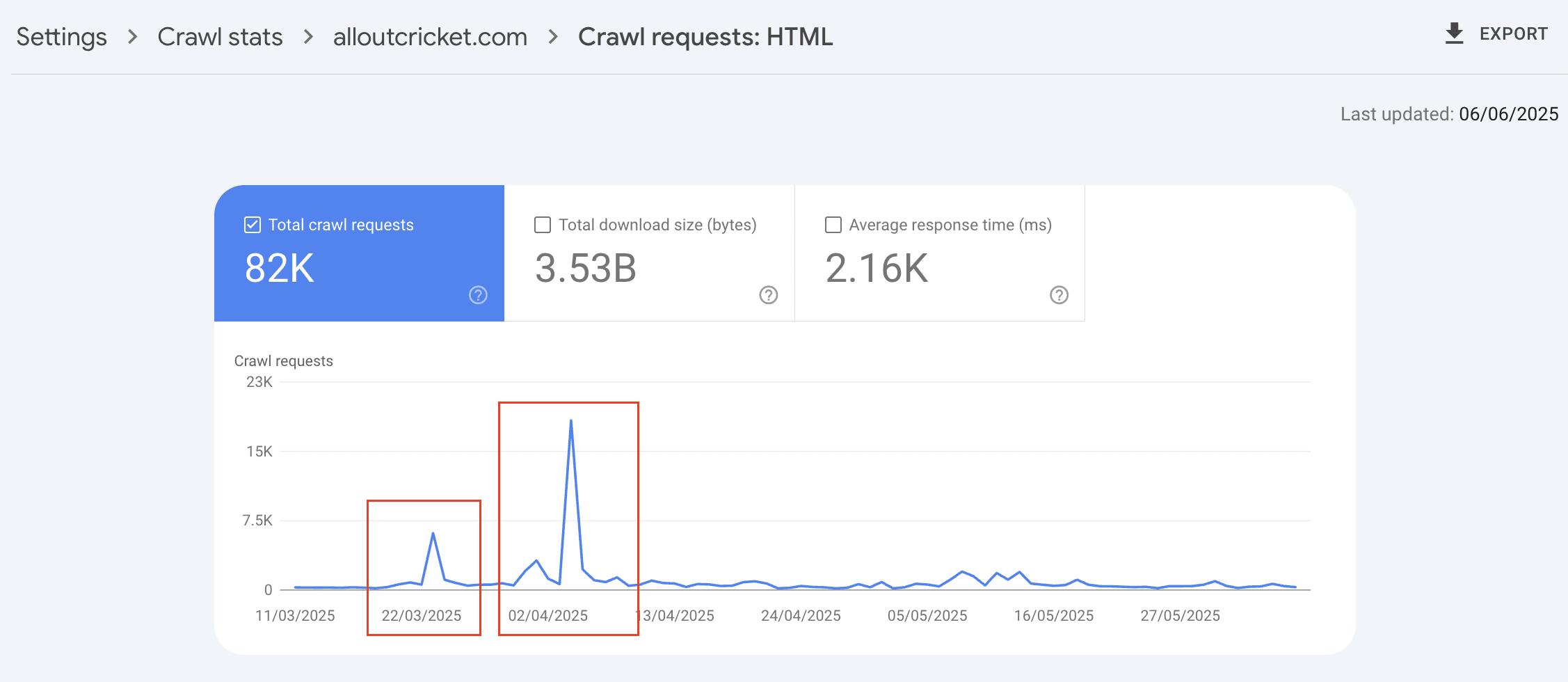
From the accounts we have access to that saw 50-75% pages deindexed we can see in Crawl Stat reports that Googlebot crawling spike between March…
Spike seen for HTML pages in early May-25 for a website which had 50% of its pages deindexed.
…and early May 2025.
Spike in Googlebot crawling for HTML pages between late March and early April 2025 for a website that had 75% of its pages deindexed.
Note: The spikes in crawling might be nothing to do with the indexing purge. As we’ve seen at Indexing Insight that crawling and deindexing aren’talways connected.
In fact the longer it takes for a live page to be crawled the greater the chance a page will be deindexed.
We don’t know if this 90-day indexing rule is here to stay or if this is just a one-off by Google to purge its index of low-quality content.
Here are some of my theories:
Threshold update - A test they are running to see the impact of tweaking the quality thresholds in its index to remove low-quality pages faster from search results.
Seasonalupdate - Google does “deindex” pages due to seasonal demands and they might be archiving indexed pages to make room for other more important pages.
Core update - Google may be getting ready to run a BIG core update and the index is just reacting to the new mini algorithms.
Your guess is as good as mine. But one thing we know is that somethingchanged.
🤯 15% - 75% of Indexed Pages Removed
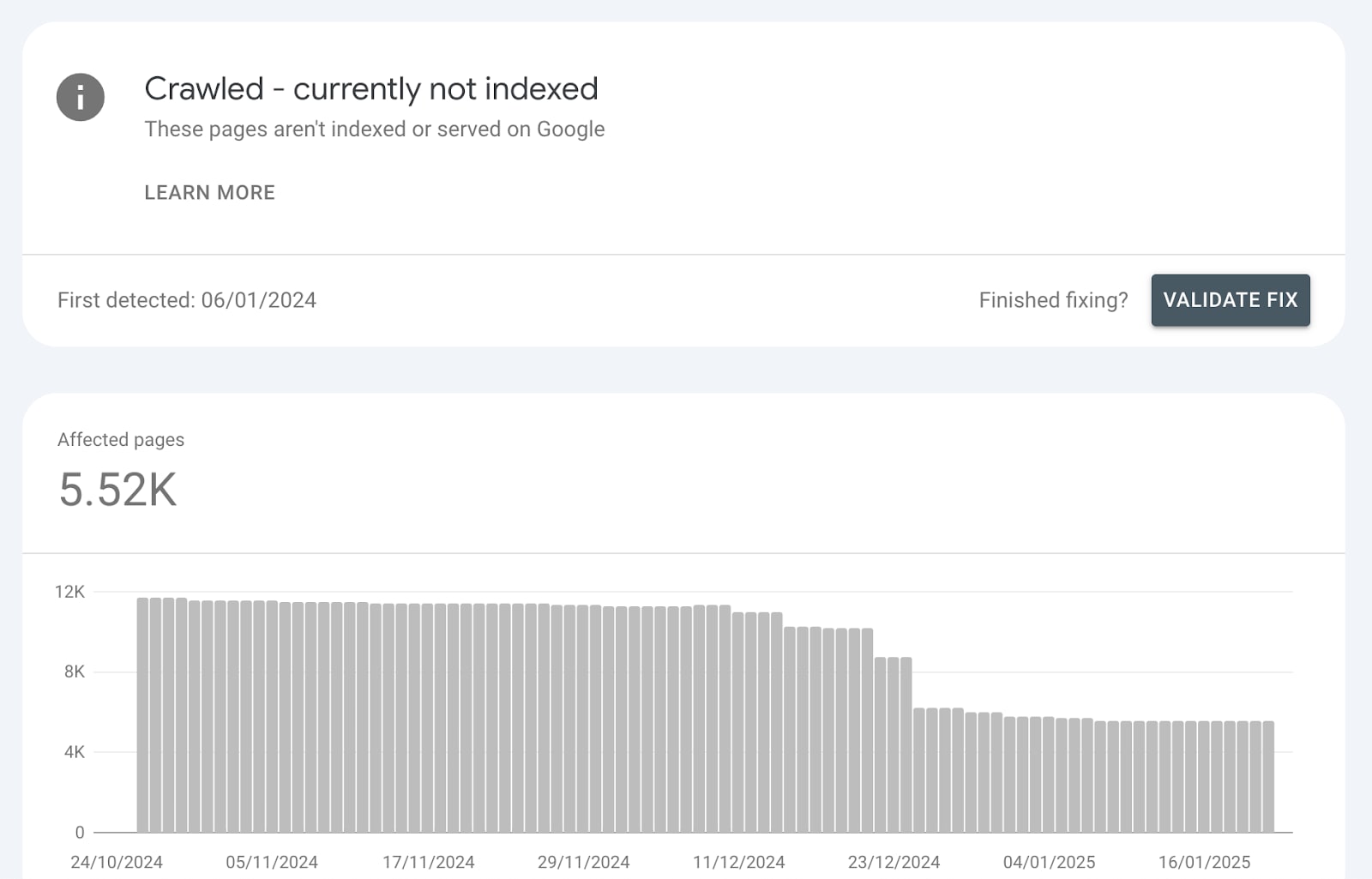
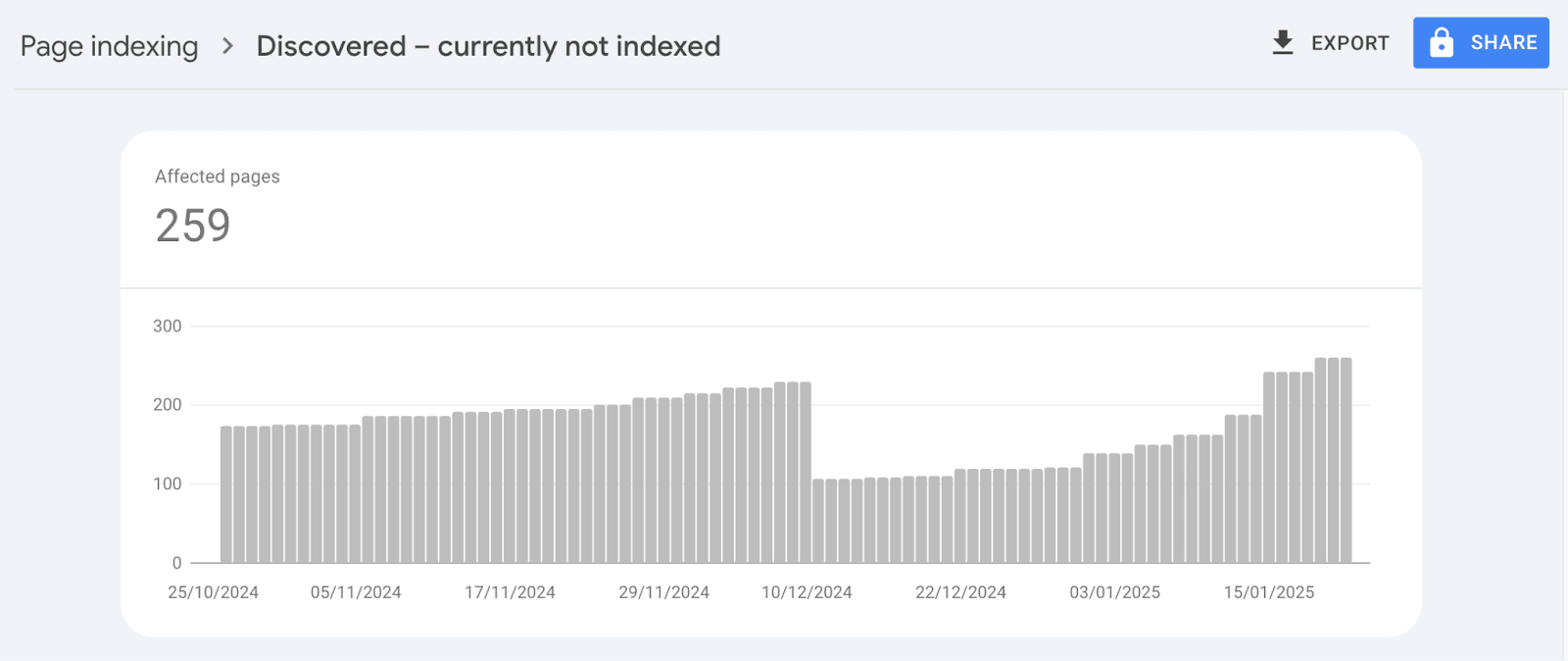
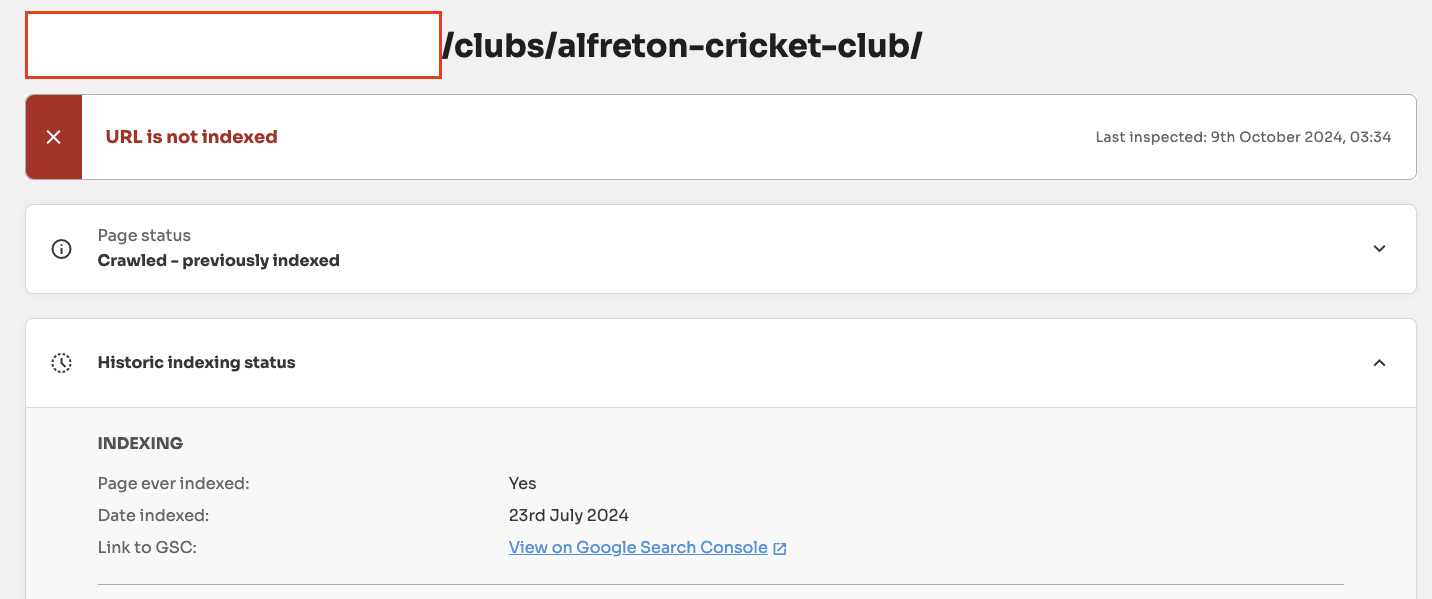
At Indexing Insight, we have a unique report called ‘crawled - previously indexed’.
This unique report tells us exactly which indexed pages have been actively deindexed by Google. This allows us to see exactly the impact of the May/June 2025 update.
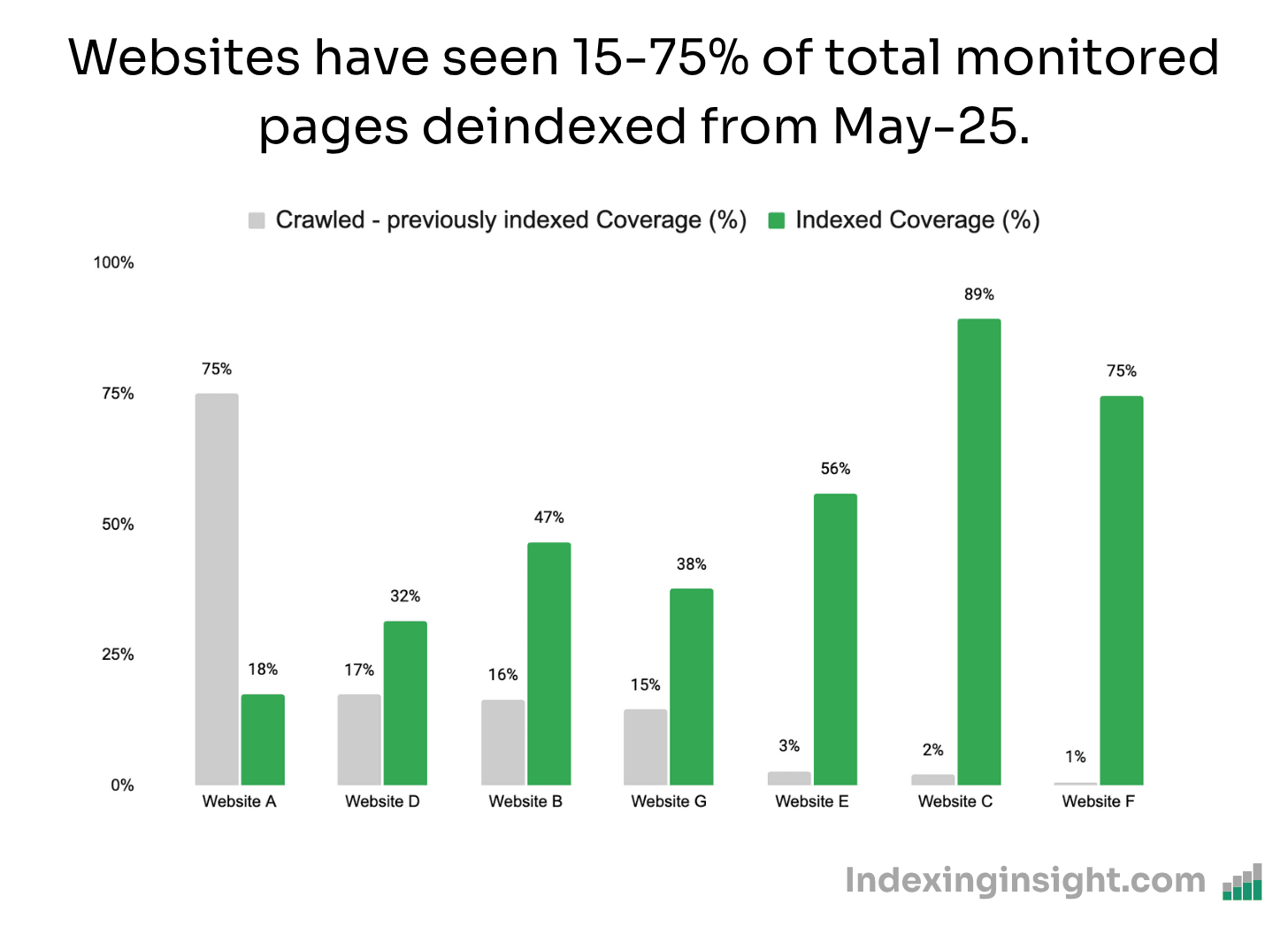
In May-25 we’ve seen websites get 15% - 75% of monitored pages moved into the ‘crawled - previously indexed’ report.
The interesting thing about monitoring different websites is the variation in data.
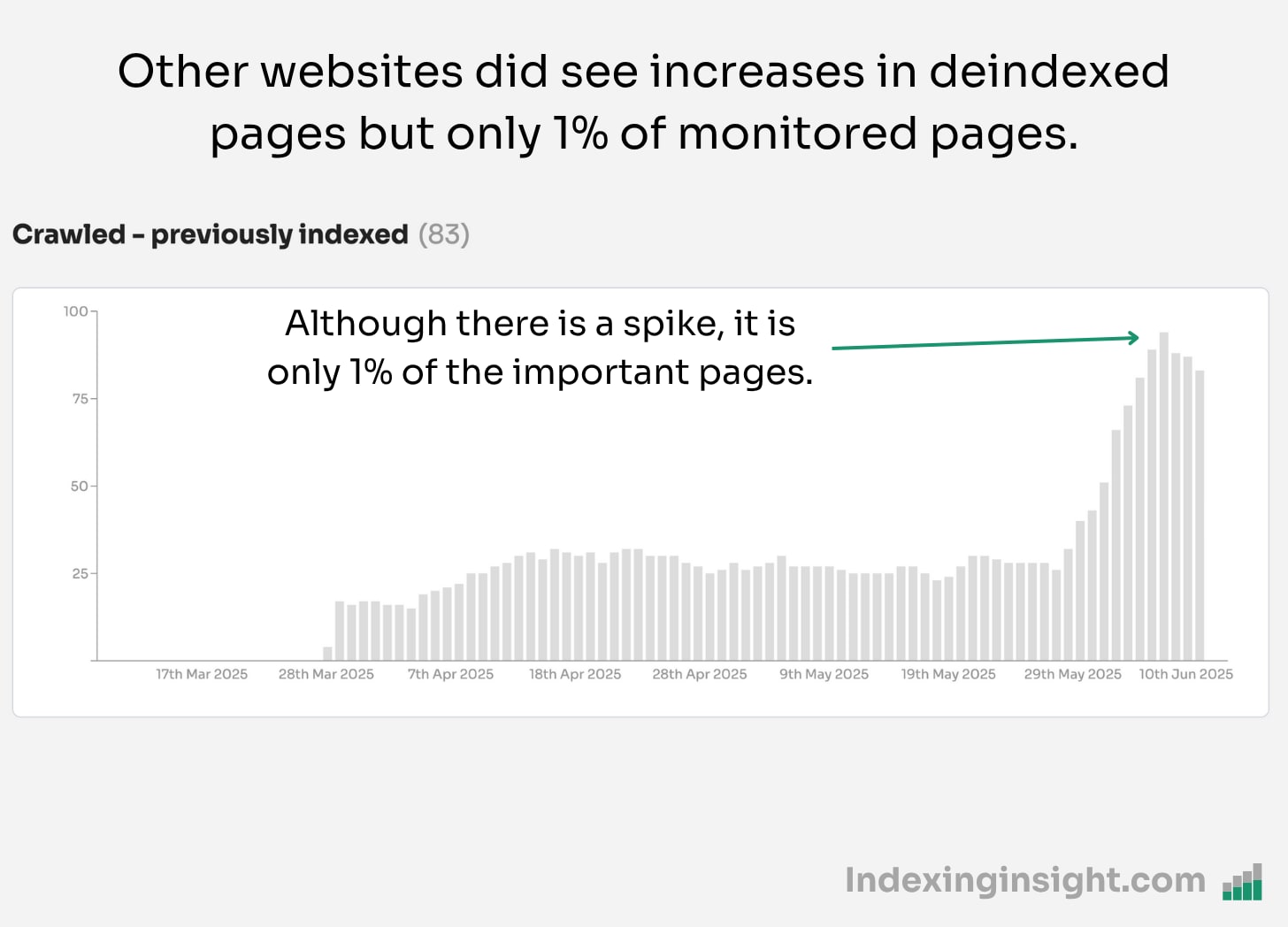
What was interesting about this update was that not all websites saw such a huge spike in indexed pages being actively removed from the index.
Although they saw an increase in ‘crawled - previously indexed’ this was still only 1% - 3% of all monitored pages.
What is interesting is that not all websites seem to impacted by this May-25 index update. Some were impacted more than others…
…they question is what is causing these pages to be deindexed?
That’s what I found out in the final part of this article.
0️⃣ Why Pages Have Been Deindexed
The reason pages are being actively removed is because of a lack of user engagement.
After analysing both the Search Analytics data we have access to AND reviewing the types of pages being actively removed, the pattern is clear.
Google actively purged a lot of “poor performing” pages from its index in May 2025.
There are two key reasons why this trend is clear when you review the data:
Zero or low-engagement pages
Zero impact on SEO performance
Zero or low-engagement pages
When reviewing the pages that we have Search Analytics data we noticed the same pattern: Pages actively deindexed by Google had low or zero SEO performance.
Let me show you some examples.
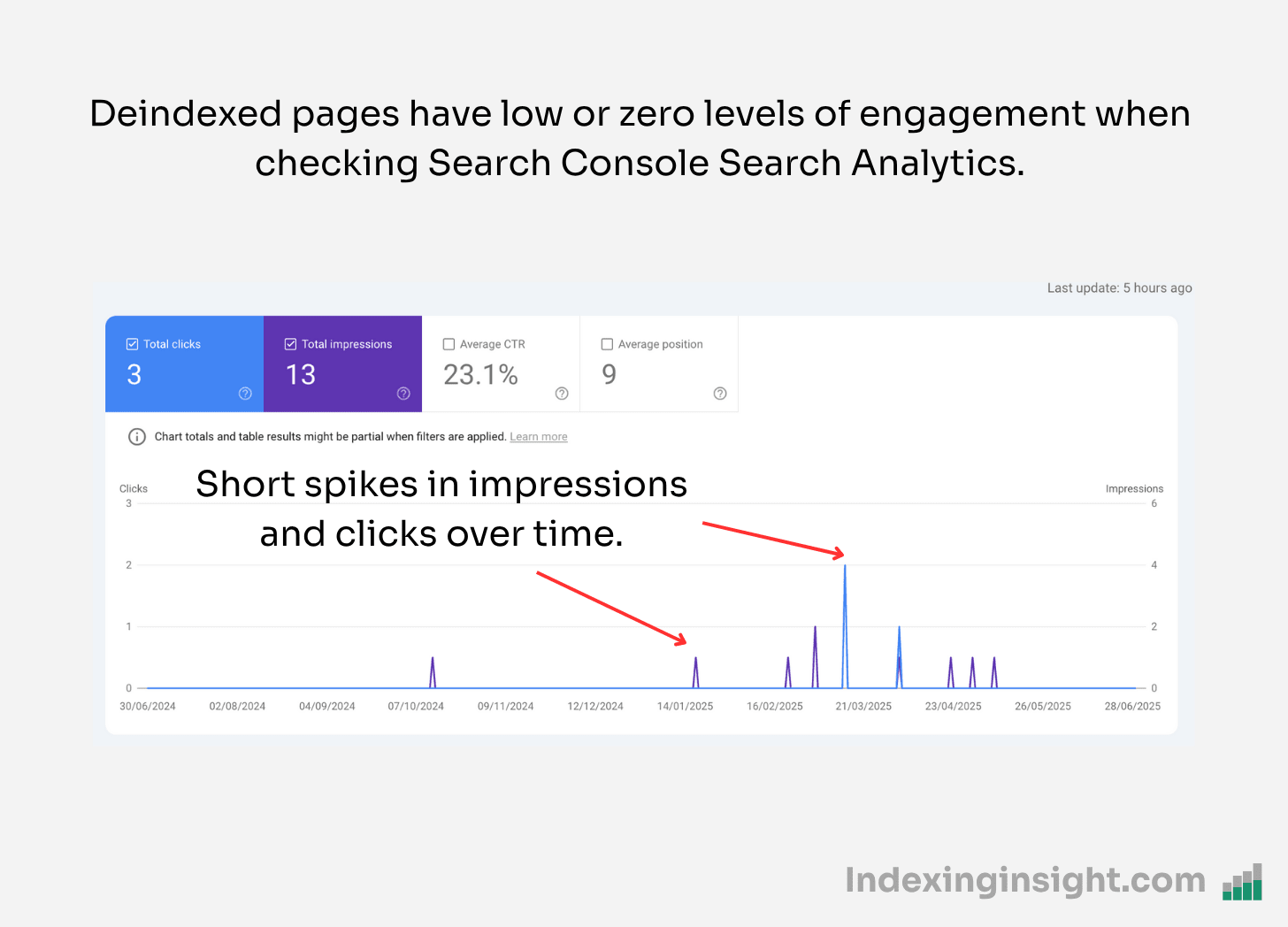
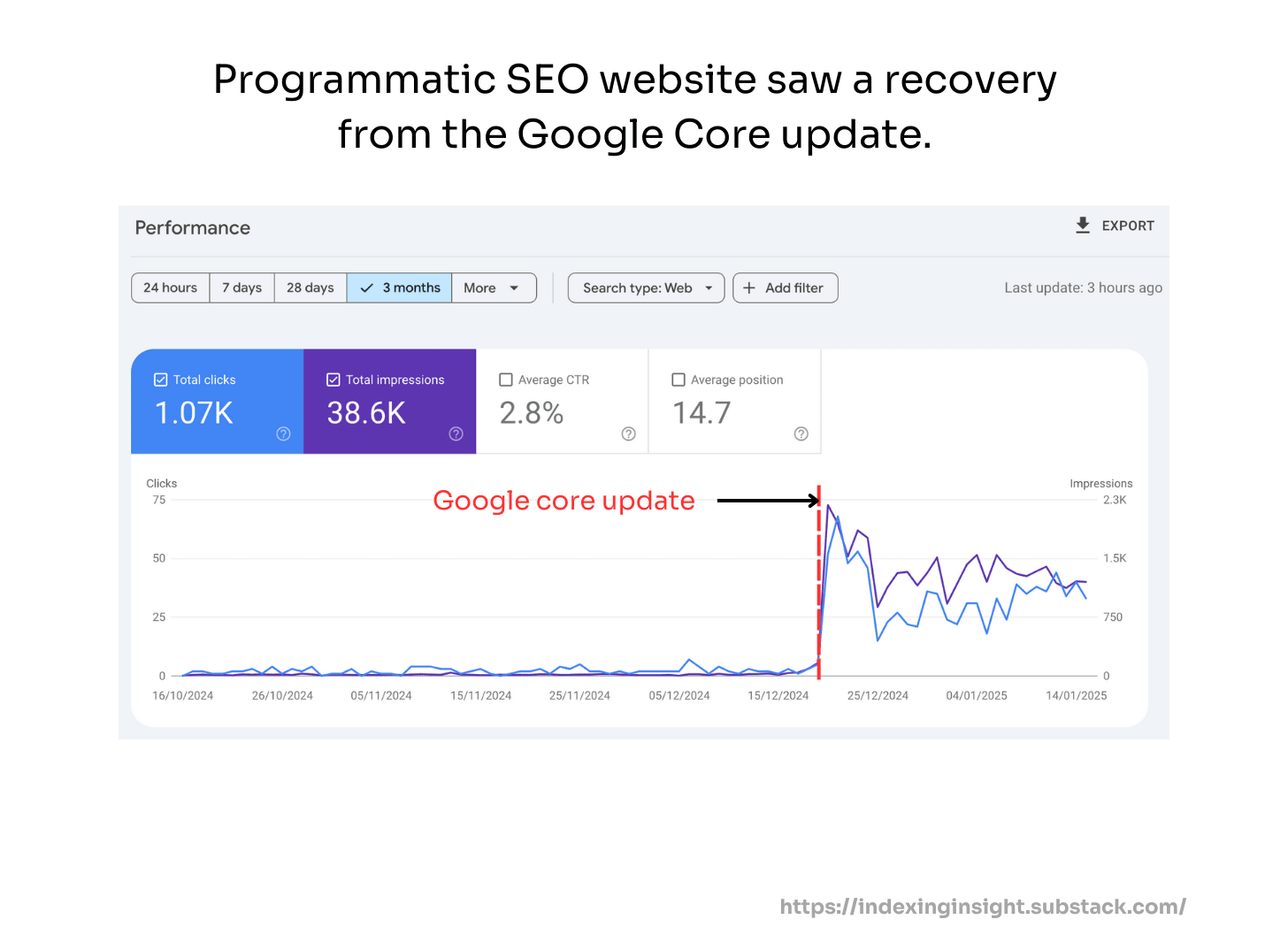
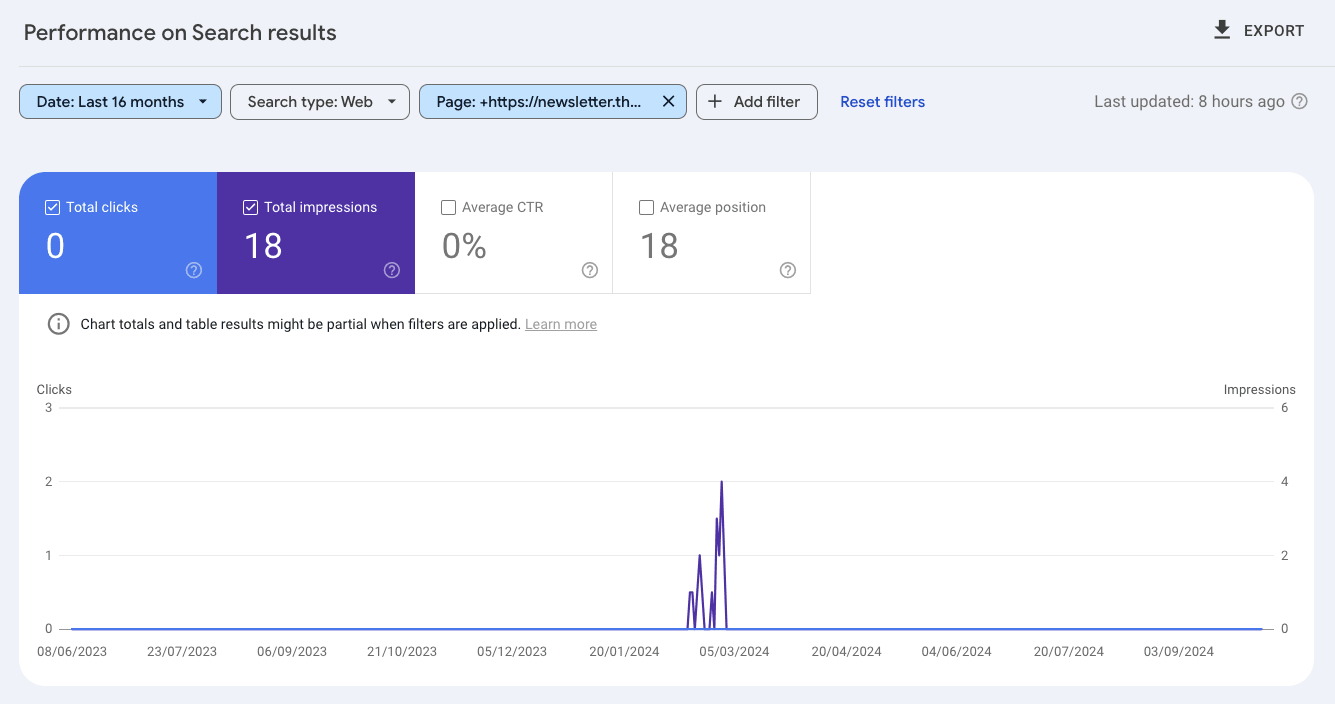
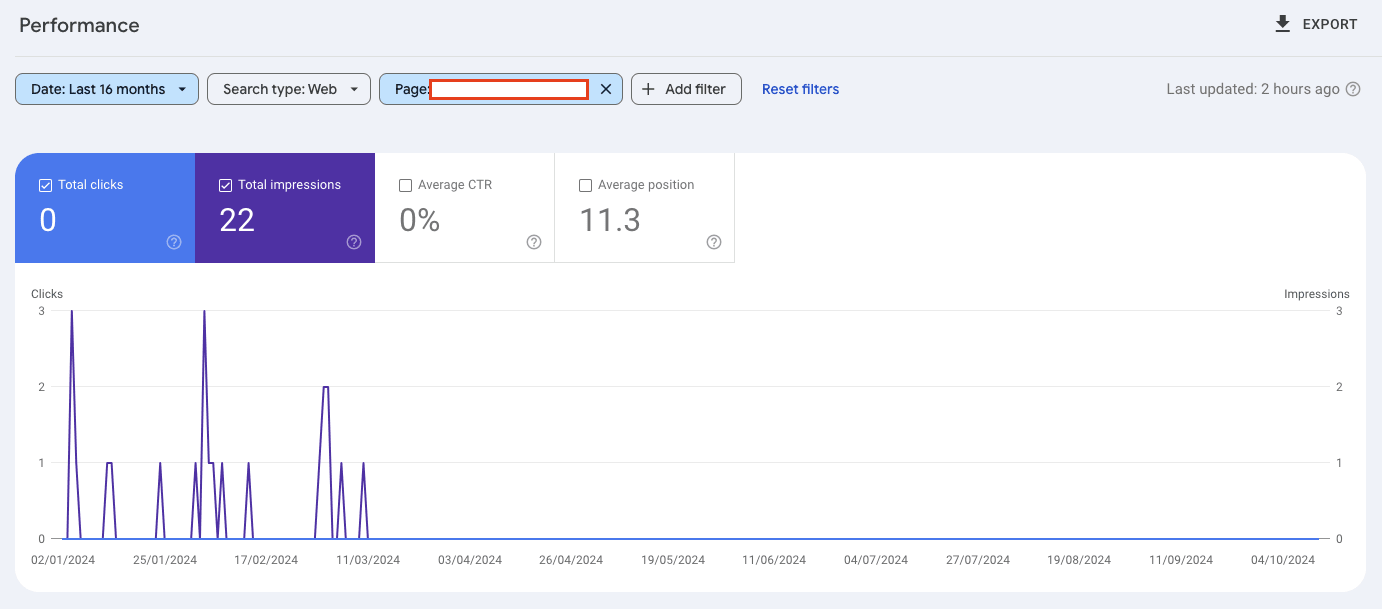
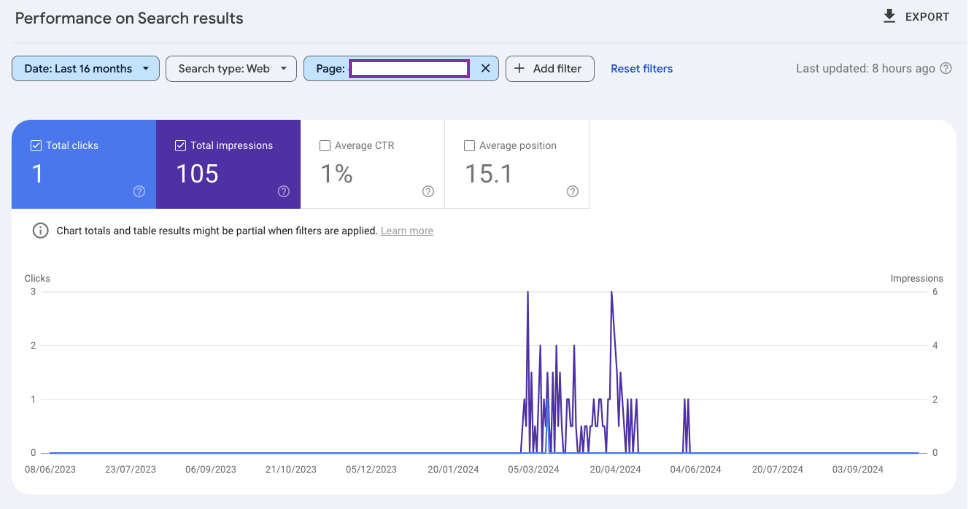
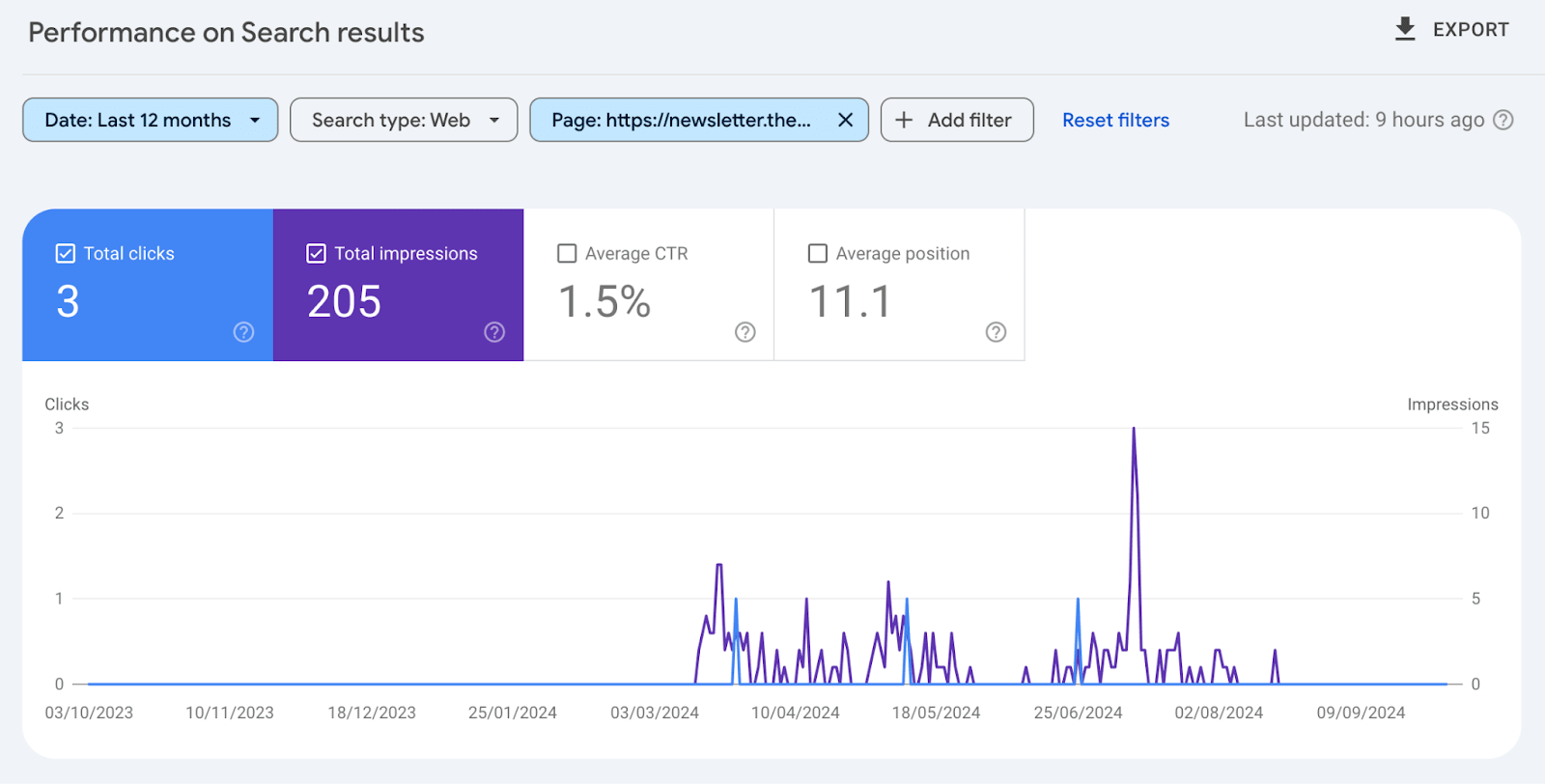
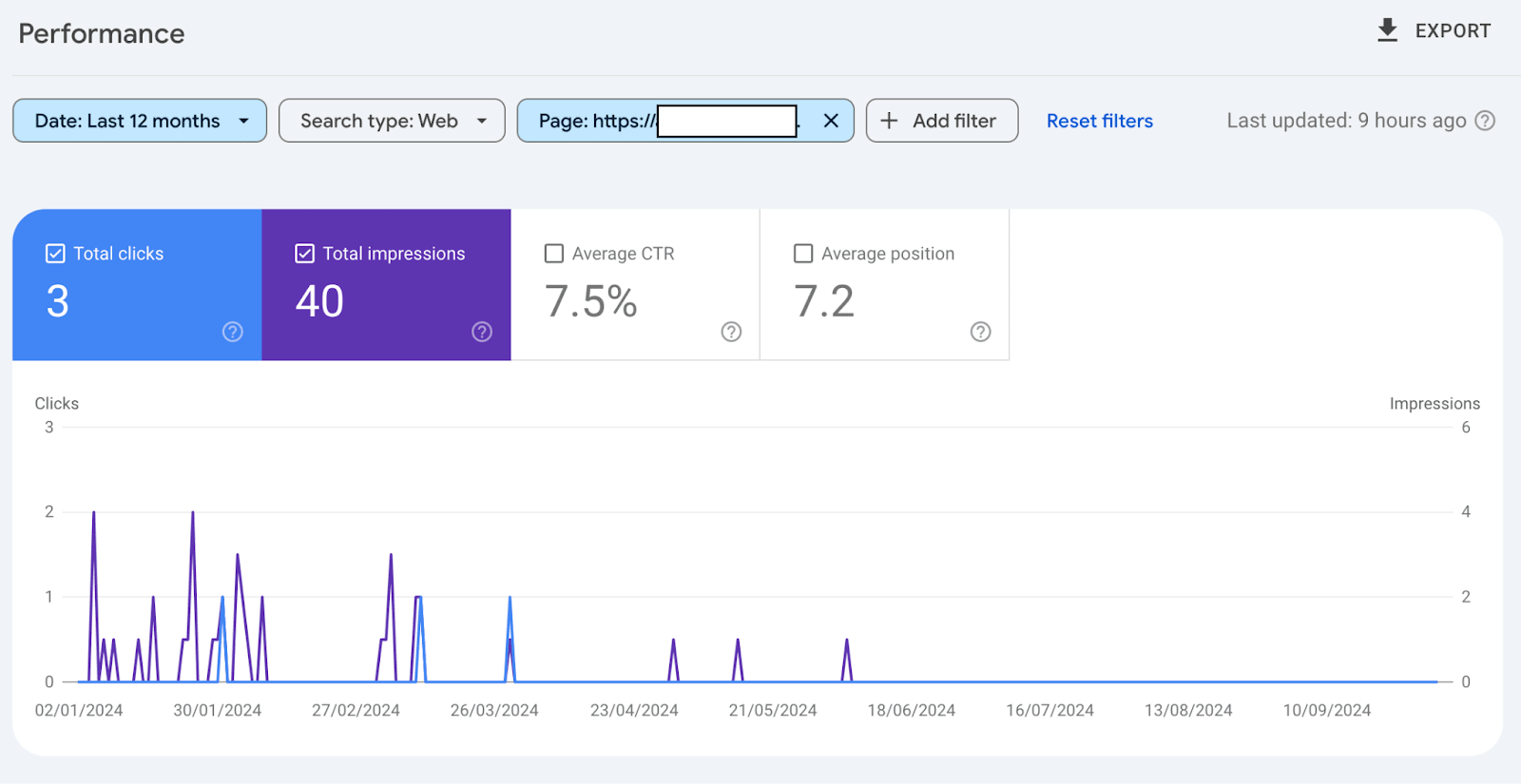
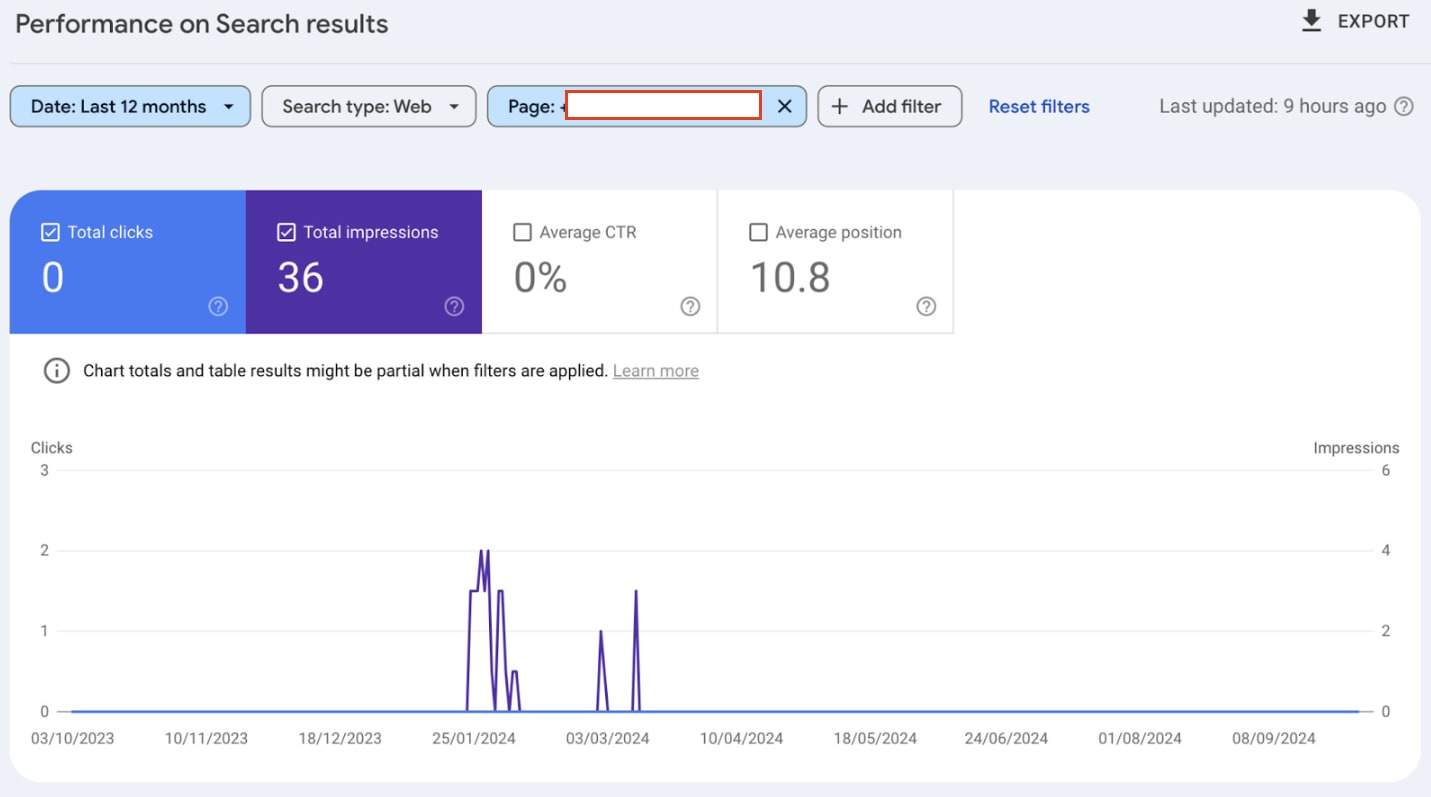
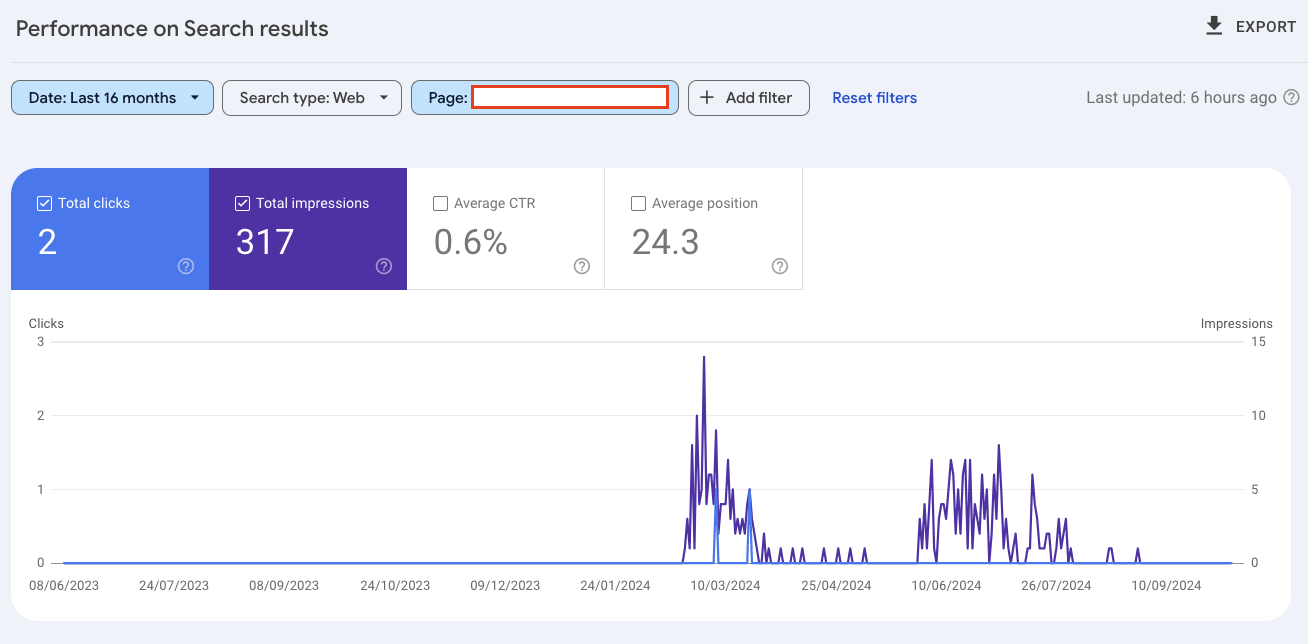
When checking the SEO performance of pages for atmlocation.pro you can see that the page did appear in Google Search. But barely had any clicks or impressions over the last 12 months.
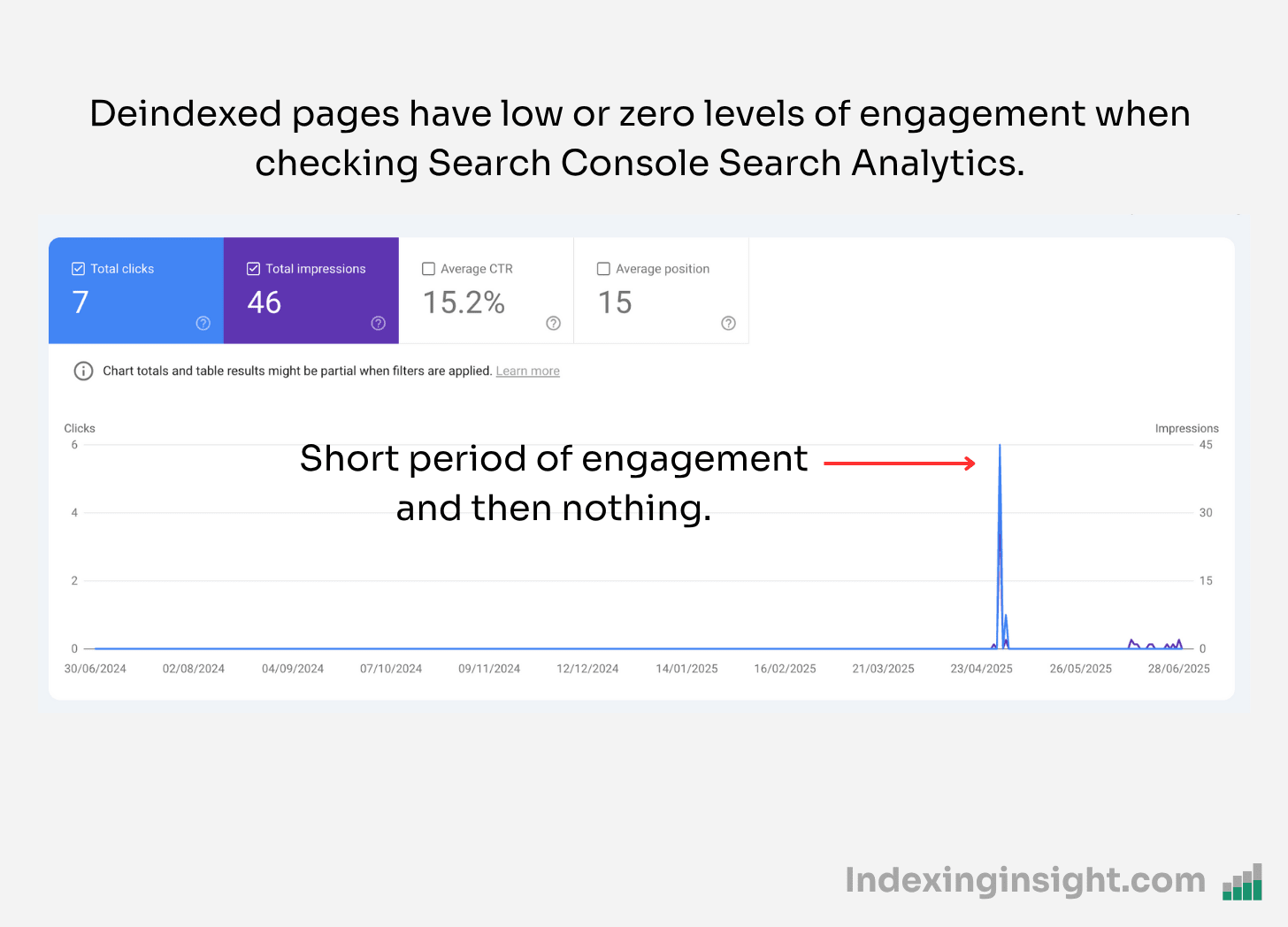
For another publishing website, you can see that the page had a large spike in engagement and then nothing.
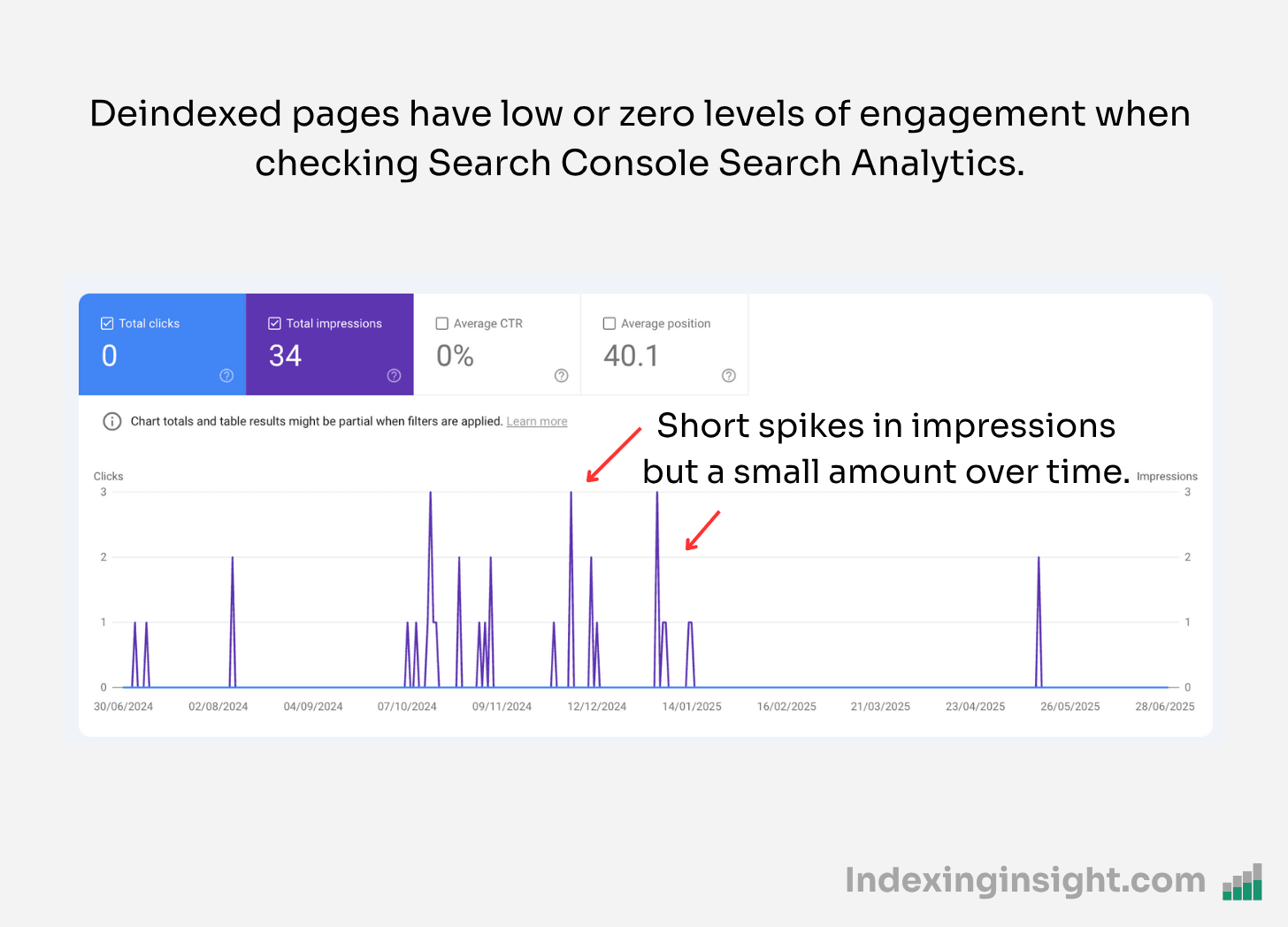
Finally, blog articles from a website with a lack of SEO performance (clicks and impressions) were actively deindexed by Google.
The same pattern is seen over and over again when reviewing pages that were actively deindexed in Google’s Search index.
Pages that had poor performance in Googe Search were actively purged.
Zero impact on SEO performance
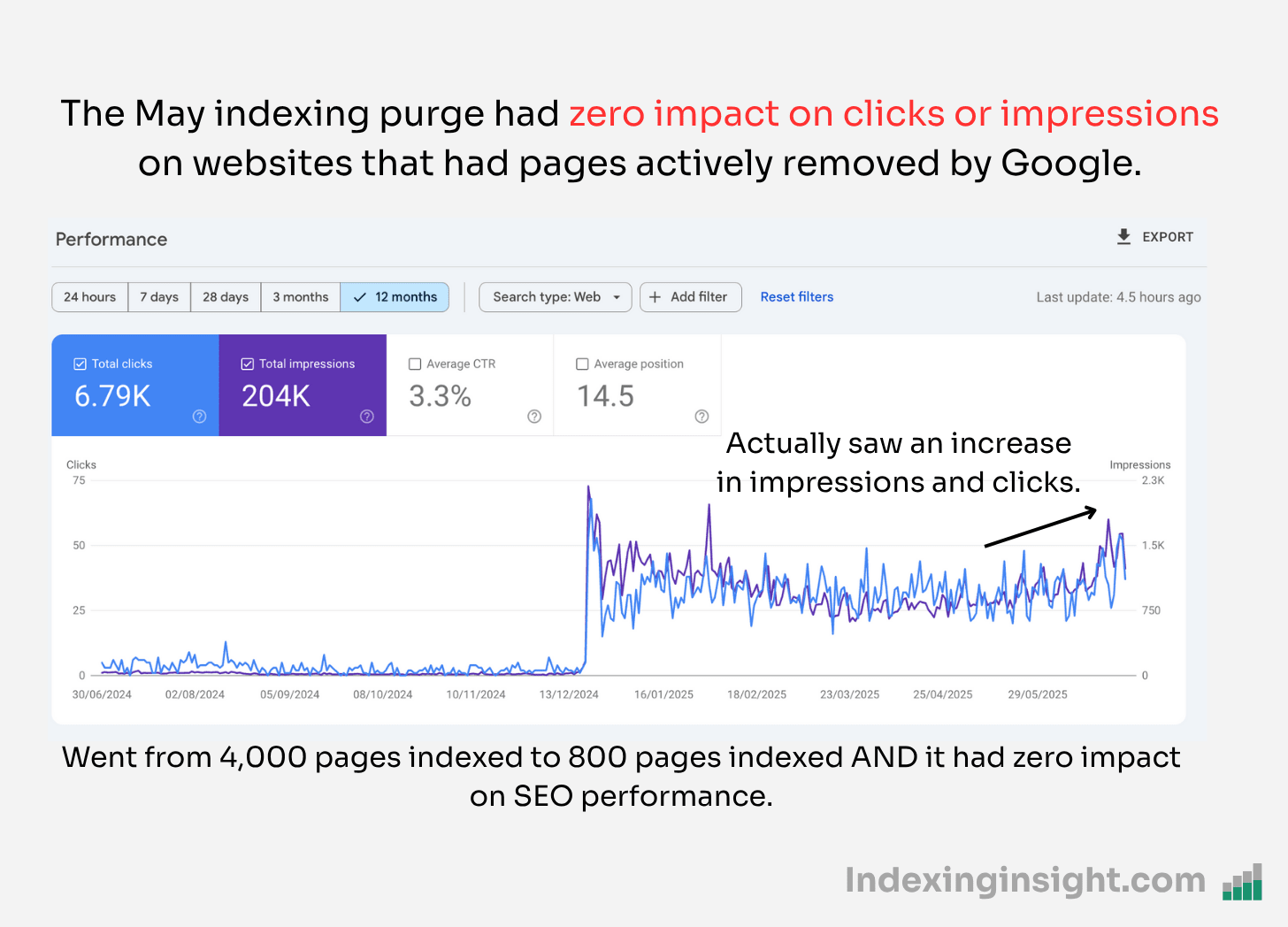
The indexing purge had zero impact on the SEO performance of websites.
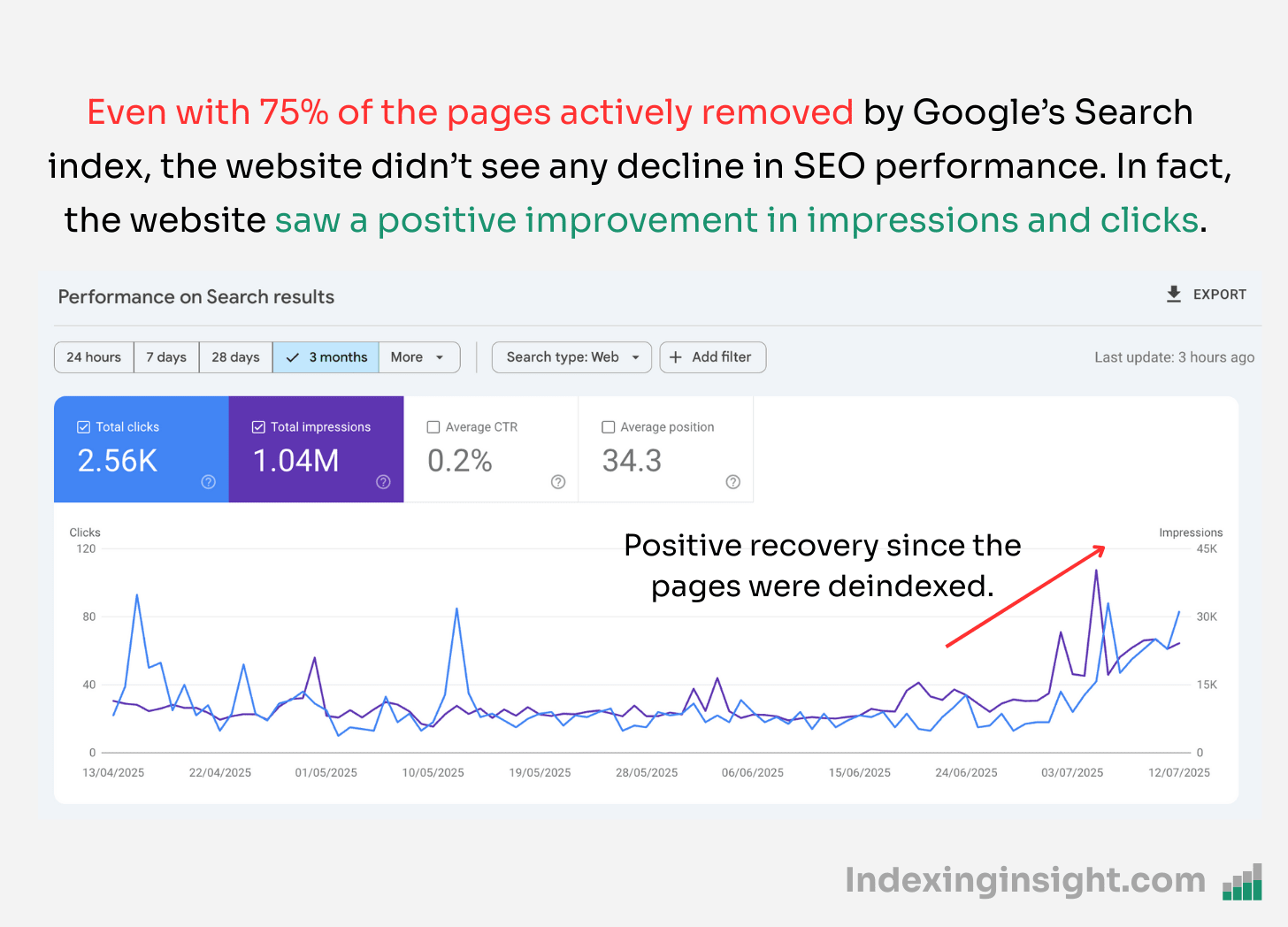
As you can see from the screenshot below, the removal of indexed pages has had zero impact on SEO clicks or impressions after late May-25 or early June-25.
This didn’t just happen to 1 website but other websites we had access to saw either no decline or a positive trend in clicks and impressions.
The screenshot below is of a website that had 75% of its important pages actively removed by Google’ Search index. However, it still saw a positive improvement in clicks and impressions during the June core update.
This further shows that Google actively removed a TONNE of inactive documents from its search index.
If thousands of pages get actively deindexed and it has zero impact on impressions or clicks…were those pages of use anyway?
Summary
Something happened in Google’s Search index at the end of May 2025.
And based on the reaction from the SEO community and website owners, the great purge impacted A LOT of websites. Of all shapes and sizes.
John Mueller, a Webmaster Trend Analyst at Google, replied to the comments of website owners on Bluesky (source) who saw massive drops in the number of indexed pages at the end of May-25:
“Thanks, everyone, for the sample URLs - very helpful. Based on these, I don't see a technical issue on our (or on any of the sites) side. Our systems make adjustments in what's crawled & indexed regularly. That's normal and expected. This is visible in any mid-sized+ website - you will see the graphs for indexing fluctuate over time. Sometimes the changes are smaller, bigger, up, or down. Our crawl budget docs talk about crawl capacity & crawl demand, they also play a role in indexing.” - John Mueller
The key thing to highlight here is that John mentioned that there was no “technical issues” on Google’s side. And there is a link between capacity/demand in indexing.
This lines up with what we’ve been seeing at Indexing Insight. However, we have NEVER seen such a large number of documents actively removed from Google’s index.
Our own customer data showed that 15-75% of indexed pages were actively deindexed by Google. These weren’t just small websites or brands. They were big, medium and small brands.
The common factor in why so many pages were deindexed?
Based on the available data, the most likely explanation was that Google purged a HUGE number of documents that didn’t drive any meaningful engagement (clicks, queries, swipes, impressions, etc.) from its search index.
The problem is that based on the data, Google’s index didn’t wait around the usual 1 - 130 days. Instead, the index seemed to purge content within days of being recrawled.
Why?
No idea. But we can make an educated guess. Here are a few ideas:
Seasonal search demand: Google needed to make more room within its index for a growing demand for more content within a topic/niche.
Core update: Google made updates to its system to get ready for its core update (which happened in June 2025), and the quality threshold increased which caused inactive pages which did not meet this threshold to be deindexed.
Quality threshold update: Google updated its quality threshold, based on stored signals in the index, which means moving forward it will get harder to get pages indexed.
These are all just ideas. And they might all be right…but also all be completely wrong.
Whatever happened in May-25 it’s clear to those who are tracking Google indexing that SOMETHING happened. And those pages that were removed from the index had zero engagement or value to Google.
Do you want to monitor Google indexing and crawling at scale?
Indexing Insight is a Google indexing intelligence tool for SEO teams who want to identify, prioritise and fix indexing issues at scale.
At Indexing Insight, a study has uncovered a 190-Day Not Indexed rule.
After 190 days since last crawl, Googlebot "forgets" a Not Indexed page even exists. This rule is based on a study of 1.4 million pages across 18 different websites (see methodology for more details).
Our study focused on combing the Days Since Last Crawl (based on Last Crawl Time) and the index coverage states from the URL Inspection API.
In this newsletter, I'll explain the 190-day rule for page forgetting and how it affects your SEO strategy.
Let's dive in.
💽 Methodology
The indexing data pulled in this study is from Indexing Insight. Here are a few more things to keep in mind when looking at the results:
👥 Small study: The study is based on 18 websites that use Indexing Insight of various sizes, industry types and brand authority.
⛰️ 1.4 million pages monitored: The total number of pages used in this study is 1.4 million and aggregated into categories and analysed to identify trends.
🤑 Important pages: The websites using our tool are not always monitoring ALL their pages, but they monitor the most important traffic and revenue-driving pages.
📍 Submitted via XML sitemaps: The important pages are submitted to our tool via XML sitemaps and monitored daily.
🔎 URL Inspection API: The Days Since Last Crawl metric is calculated using the Last Crawl Time metric for each page is pulled using the URL Inspection API.
🗓️ Data pulled at the end of March: The indexing states for all pages were pulled on 6/05/2025.
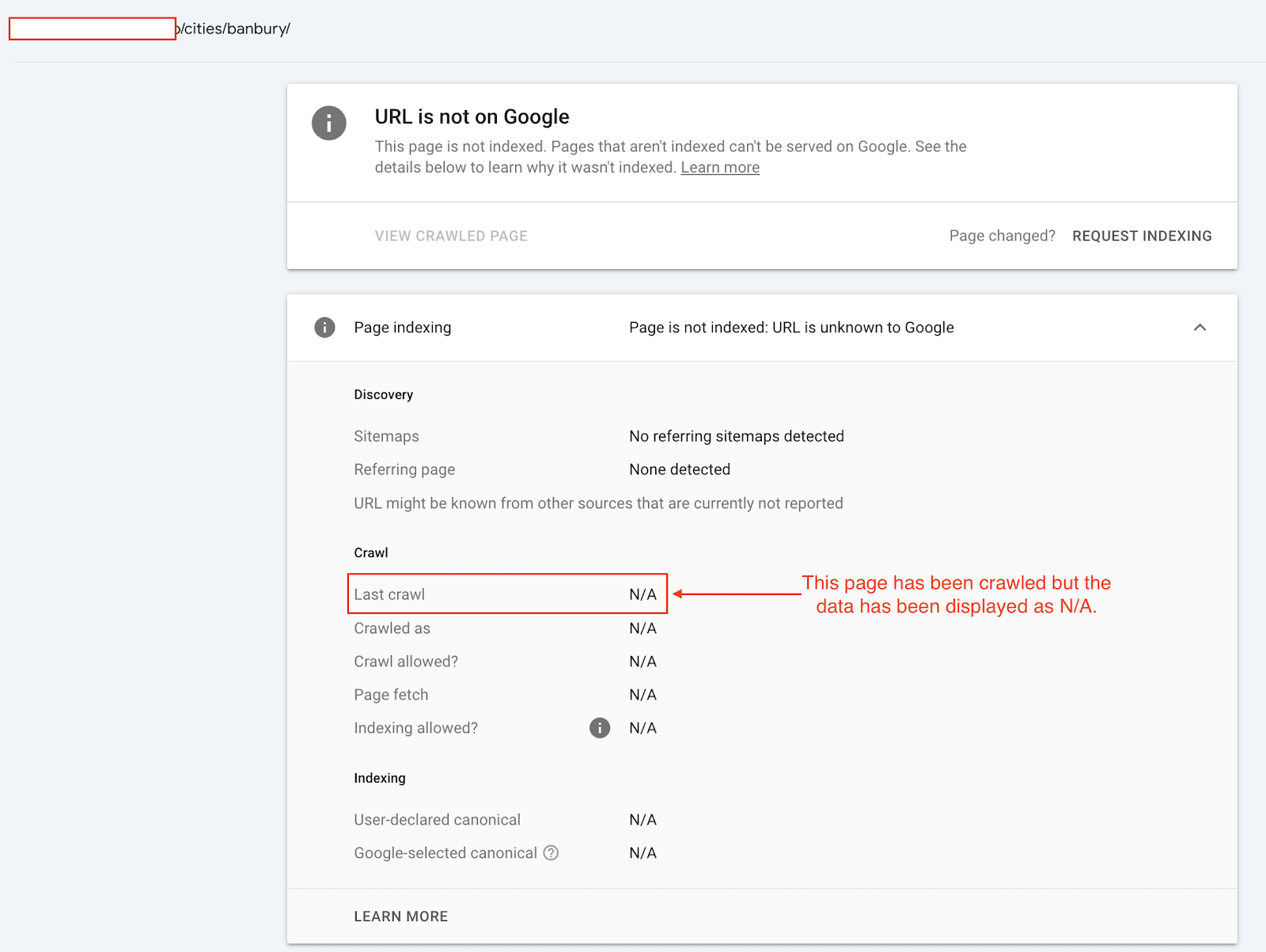
Only pages with last crawl time included: This study has included only pages that have a last crawl time from the URL Inspection API for both indexed or not indexed pages.
Quality type of indexing states: The data has been filtered to only look at the following quality indexing state types: ‘Submitted and indexed’, ‘Crawled - currently not indexed’, ‘Discovered - currently not indexed’ and ‘URL is unknown to Google’. We’ve filtered out any technical or duplication indexing errors.
🕵️ Findings
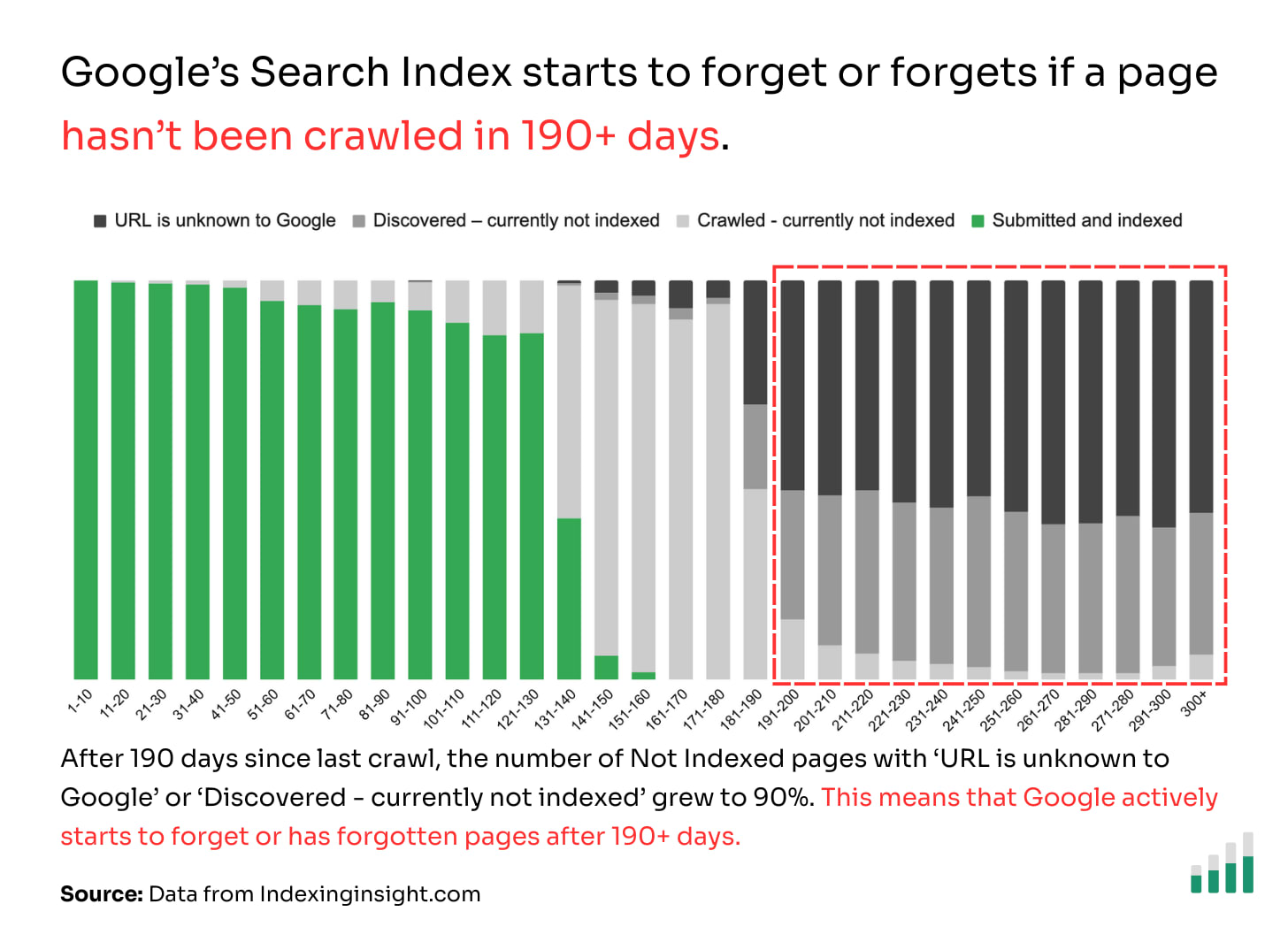
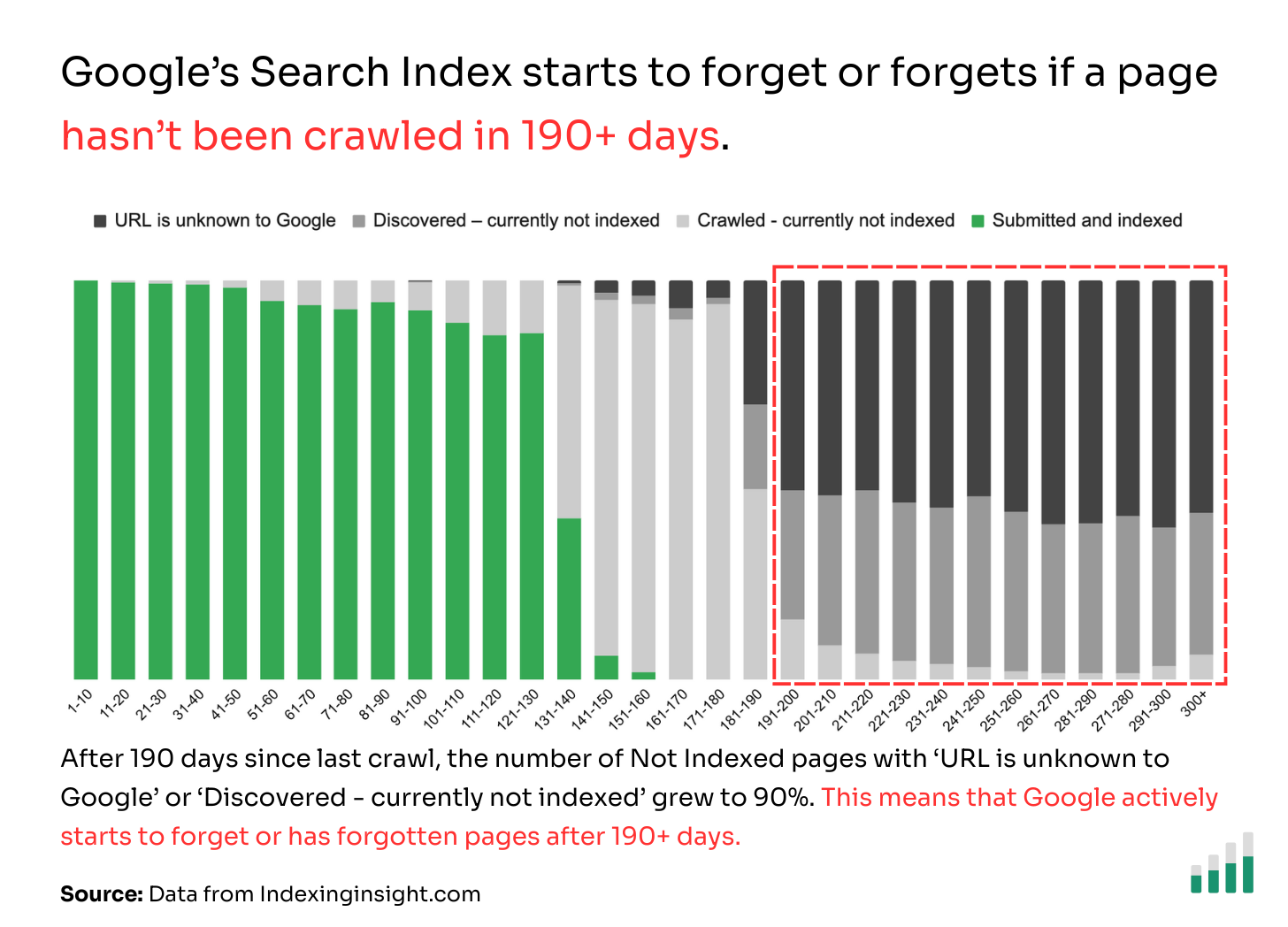
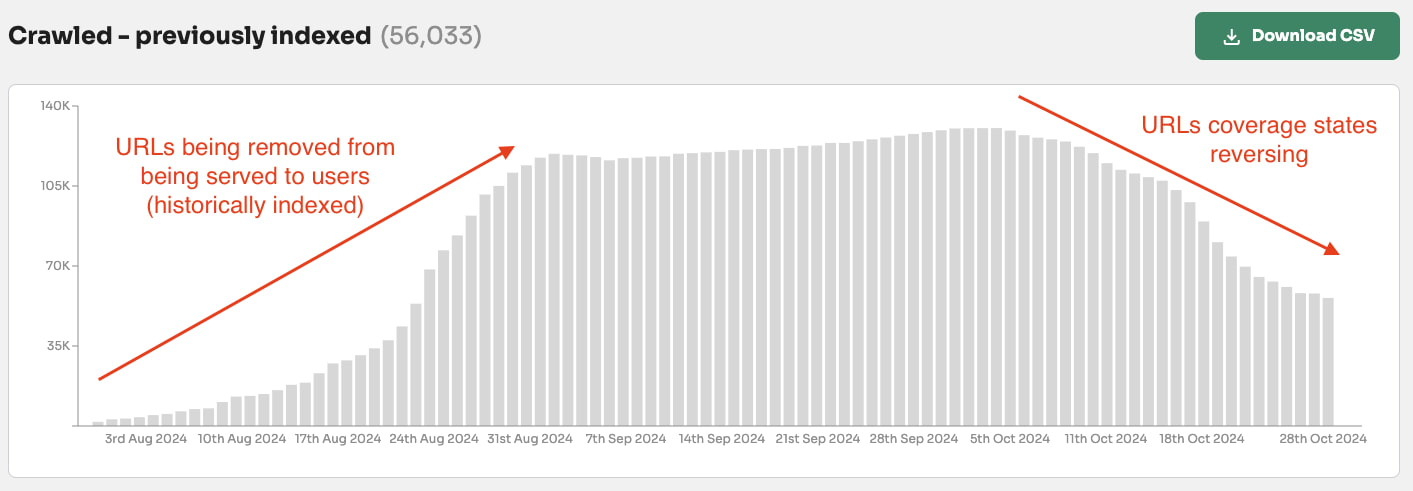
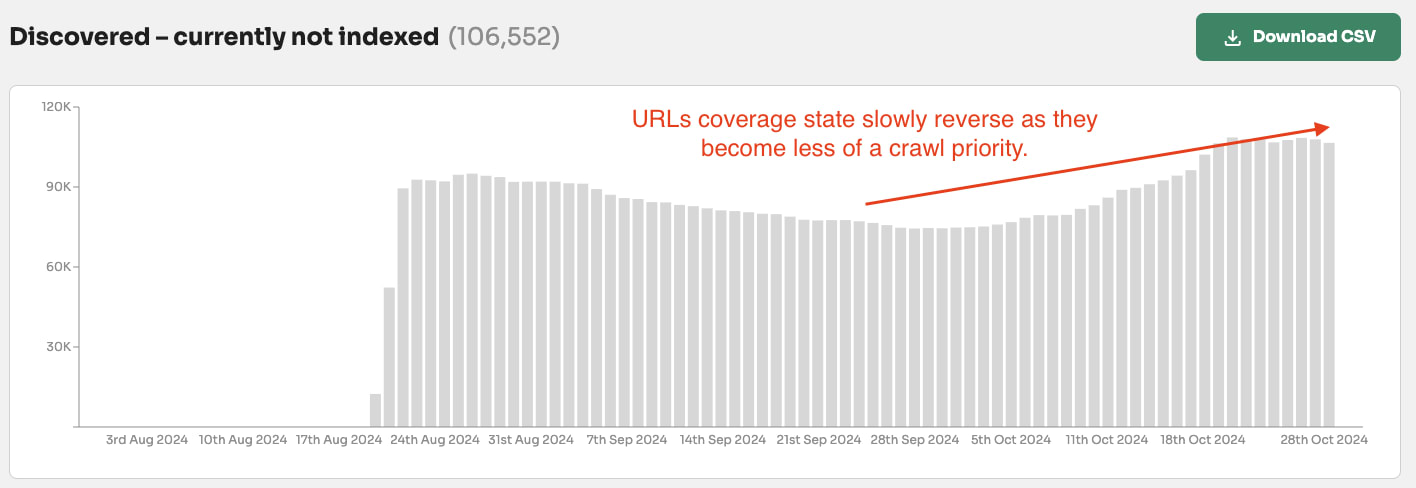
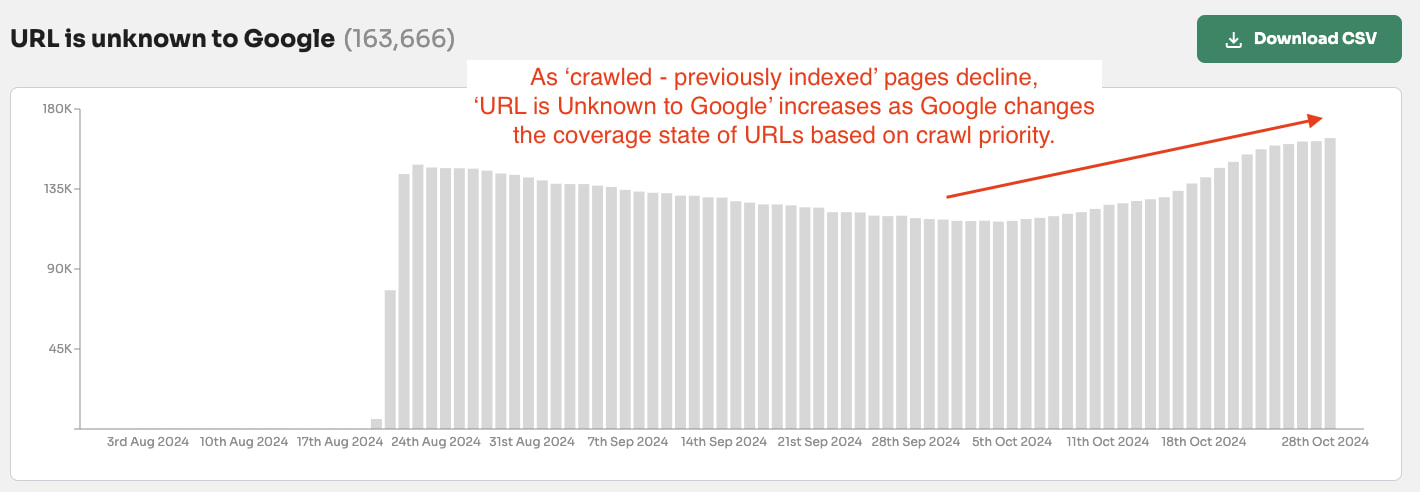
Googlebot forgets or has forgotten pages that have not been crawled in 190 days.
Our data from 1.4 million pages across multiple websites shows that if a page has not been crawled in 190+ days then there is a90% chance the page will be either start to be forgetten or forgotten by Google Search.
Below is the raw data to understand the scale of the pages in each category.
How did we come to this conclusion when looking at this data?
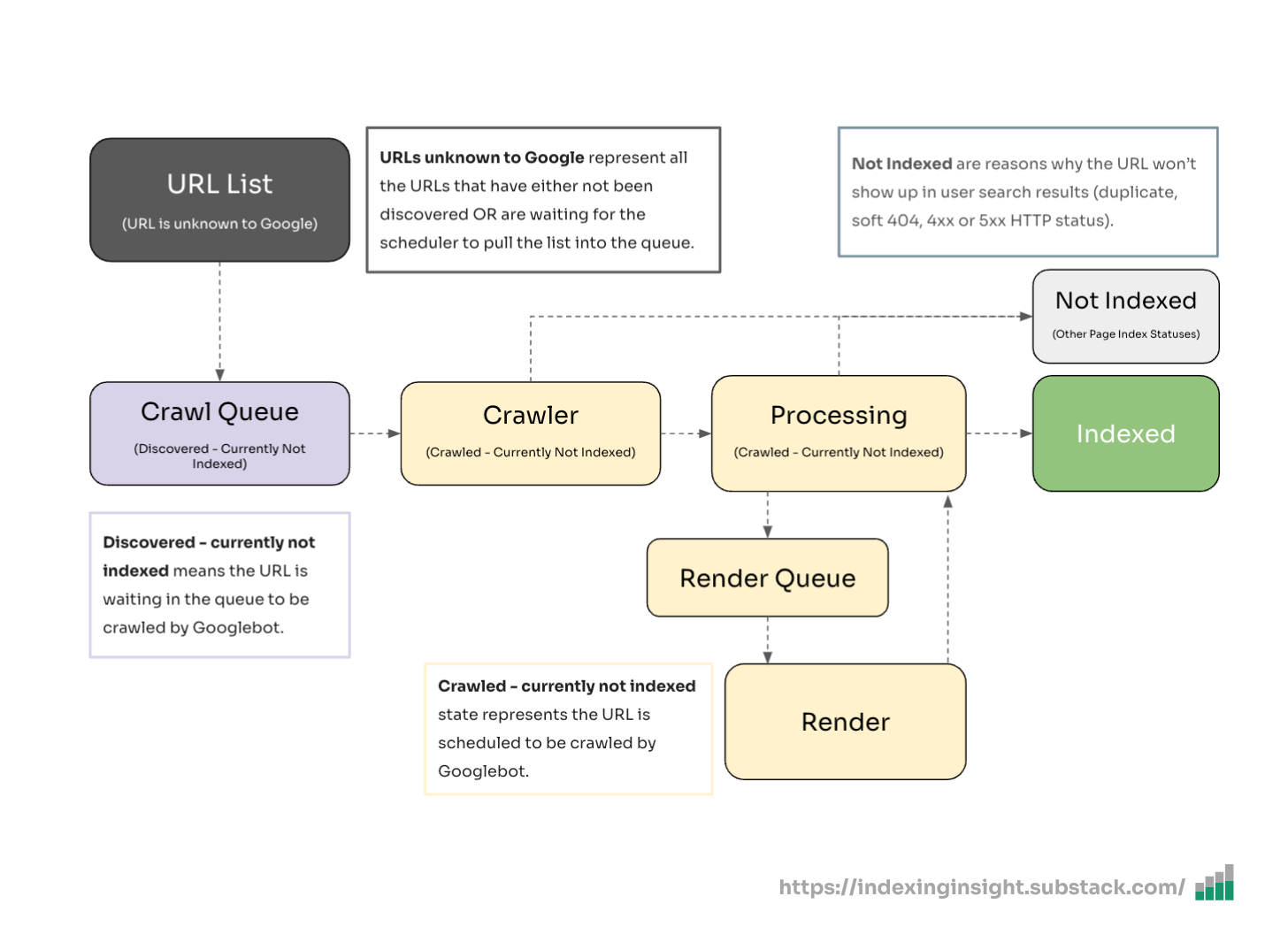
Over the last 12 months while building the tool we’ve noticed that three indexing states (‘Crawled - currently not indexed’, ‘discovered - currently not indexed’, and ‘URL is unknown to Google’) changed based on the URL's crawl priority.
Our research highlighted that the definition of these 3 not indexed coverage states in Google Search Console needs to change:
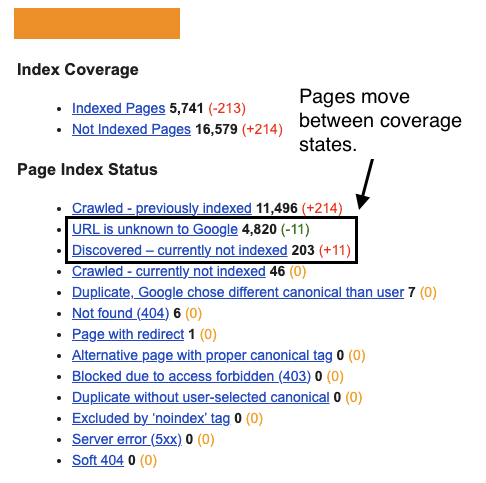
Crawled - currently not indexed: The page has either been discovered, crawled but not indexed OR the historically indexed page has been actively removed from Google’s search results.
Discovered—currently not indexed: A new page has been discovered but not yet crawled, OR Google is actively forgetting the historically indexed page.
URL is unknown to Google: A page has never been seen by Google OR Google has actively forgotten the historically crawled and indexed pages.
Note: You can read more about our research and data here:
After seeing this trend multiple times across different customer sites, we did some research into Google’s Search index to understand why this happened.
Based on our research we found that Google’s Search index is designed to actively remove pages from its search results AND forget about them over time.
Note: You can read more about our research and data here:
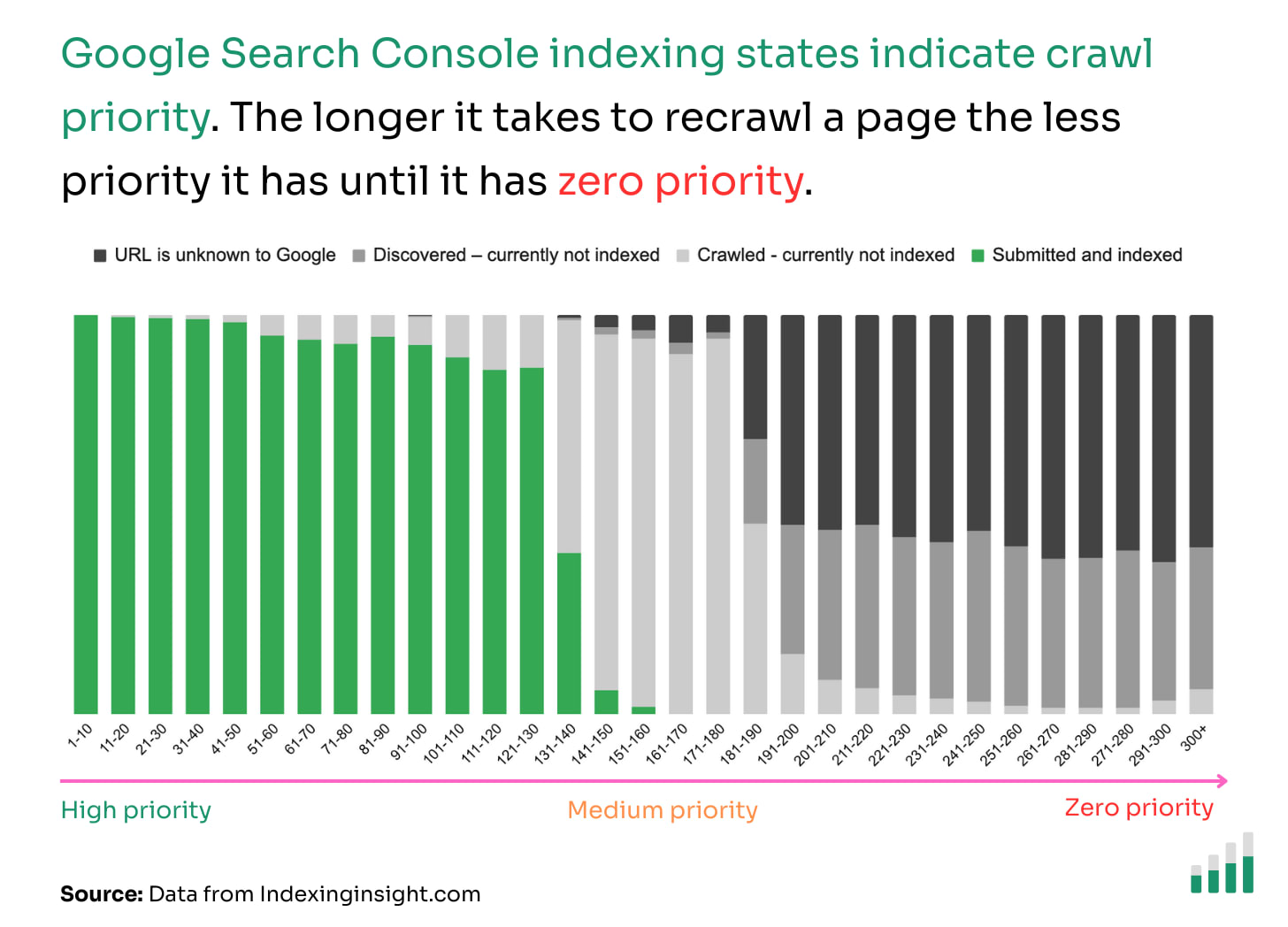
The 3 not indexed coverage states you see in Google Search Console (‘Crawled - currently not indexed’, ‘Discovered - currently not indexed’, and ‘URL is unknown to Google) reflect the crawl priority of those pages.
As a page becomes forgotten it moves through these 3 not indexed coverage states. Eventually reaching the ‘URL is unknown to Google’.
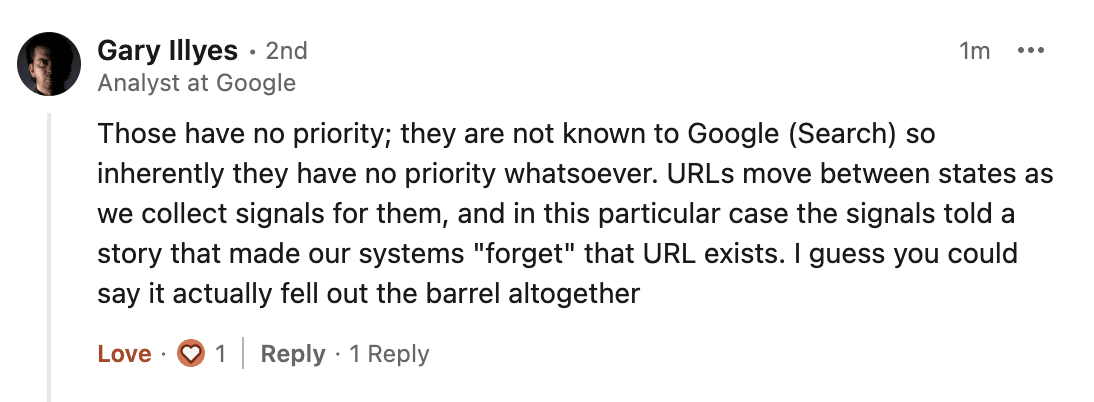
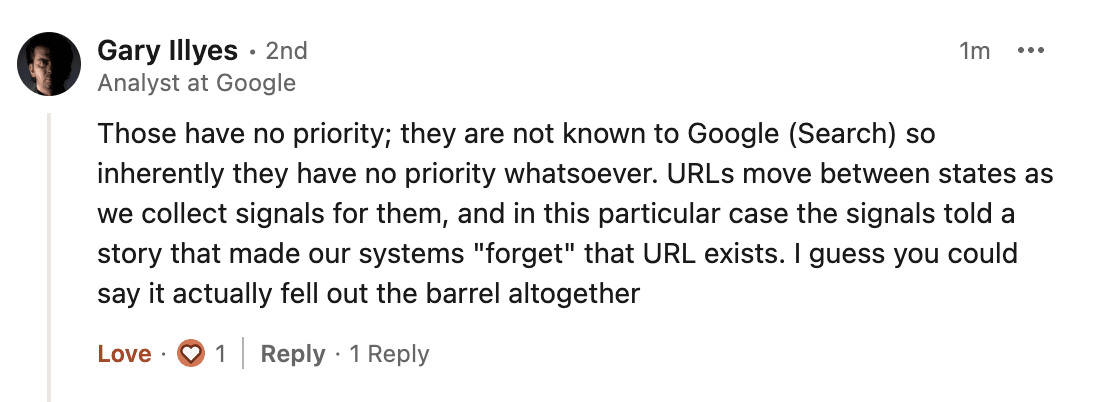
This research was supported by a comment from Gary Illyes when asked on LinkedIn why historically crawled and indexed pages can move to ‘URL is unknown to Google’:
“Those have no priority (URL is known to Google); they are not known to Google (Search) so inherently they have no priority whatsoever. URLs move between states as we collect signals for them, and in this particular case the signals told a story that made our systems "forget" that URL exists. I guess you could say it actually fell out the barrel altogether.”
The reply here mentions that URLs move between “states” as Google’s system picked up signals over time (which backs up our own research). And that historically crawled and indexed pages can eventually move to ‘URL is unknown to Google’.
To quote Gary, Google’s systems will eventually “forget” that a URL exists.
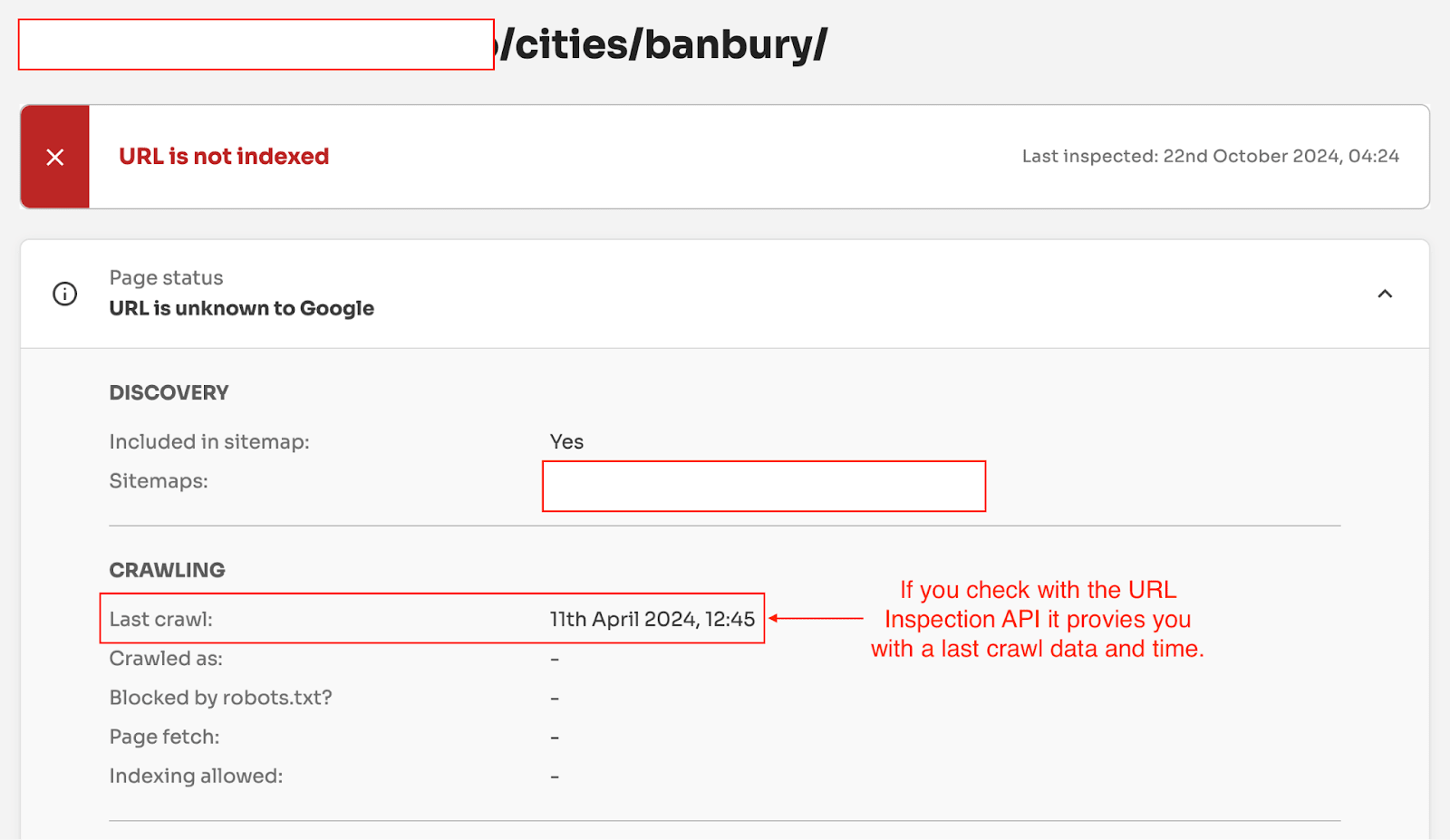
The data from Indexing Insight gives us the ability to measure and monitor how long it takes for Google to ‘forget’ a URL. All by using the Last Crawl Time metric.
If we combine the data from the 130-day indexing rule study we can build a picture of how long it takes for a page to be forgotten by Google’s Search index:
✅ 1-130 days: Between 1 - 130 days of being crawled 90% of the pages are ‘submitted and indexed’.
❌ 131-180 days: Between 131 - 190 days 50% - 90% of the not indexed pages have ‘crawled - currently not indexed’ index coverage state.
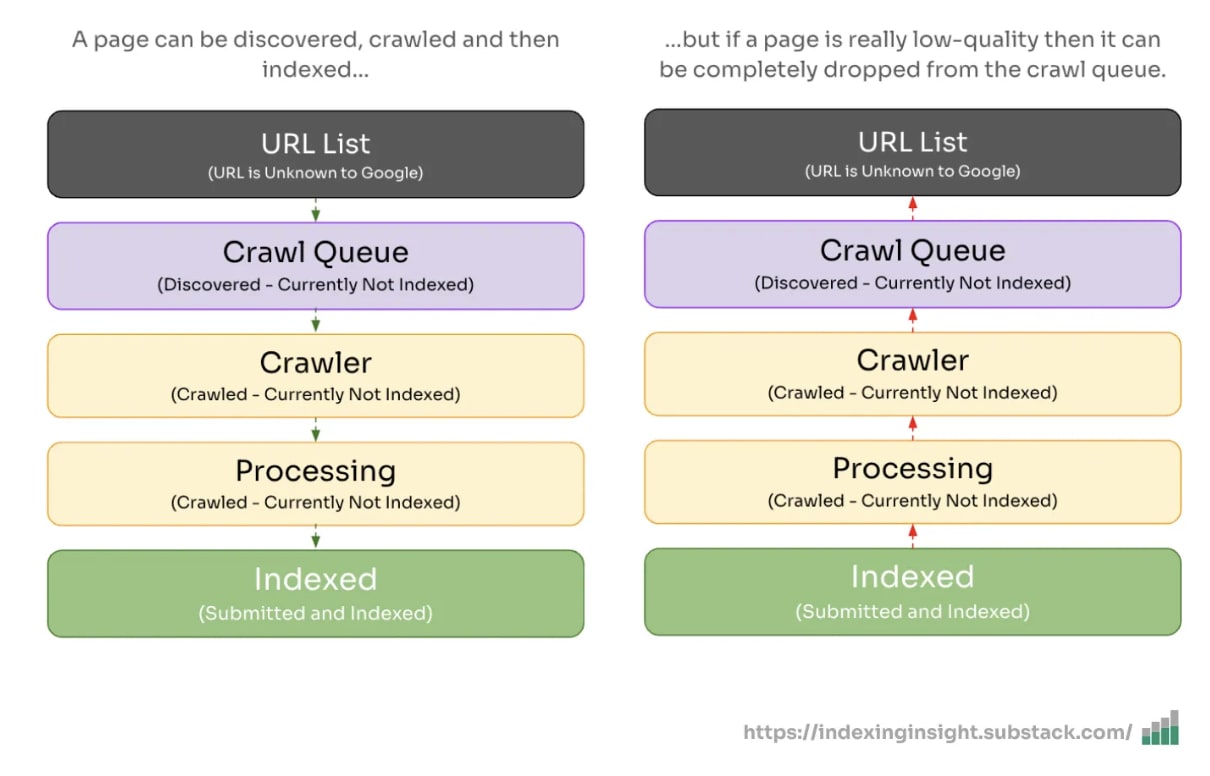
👻 190+ days: After 190 days since the pages were crawled 90% of the pages are made up of ‘Discovered - crawled currently not indexed’ or ‘URL is unknown to Google’.
If we layer this data over how Google’s Search index (might) work diagram we can now fill in the gaps for the different crawl priority “tiers”.
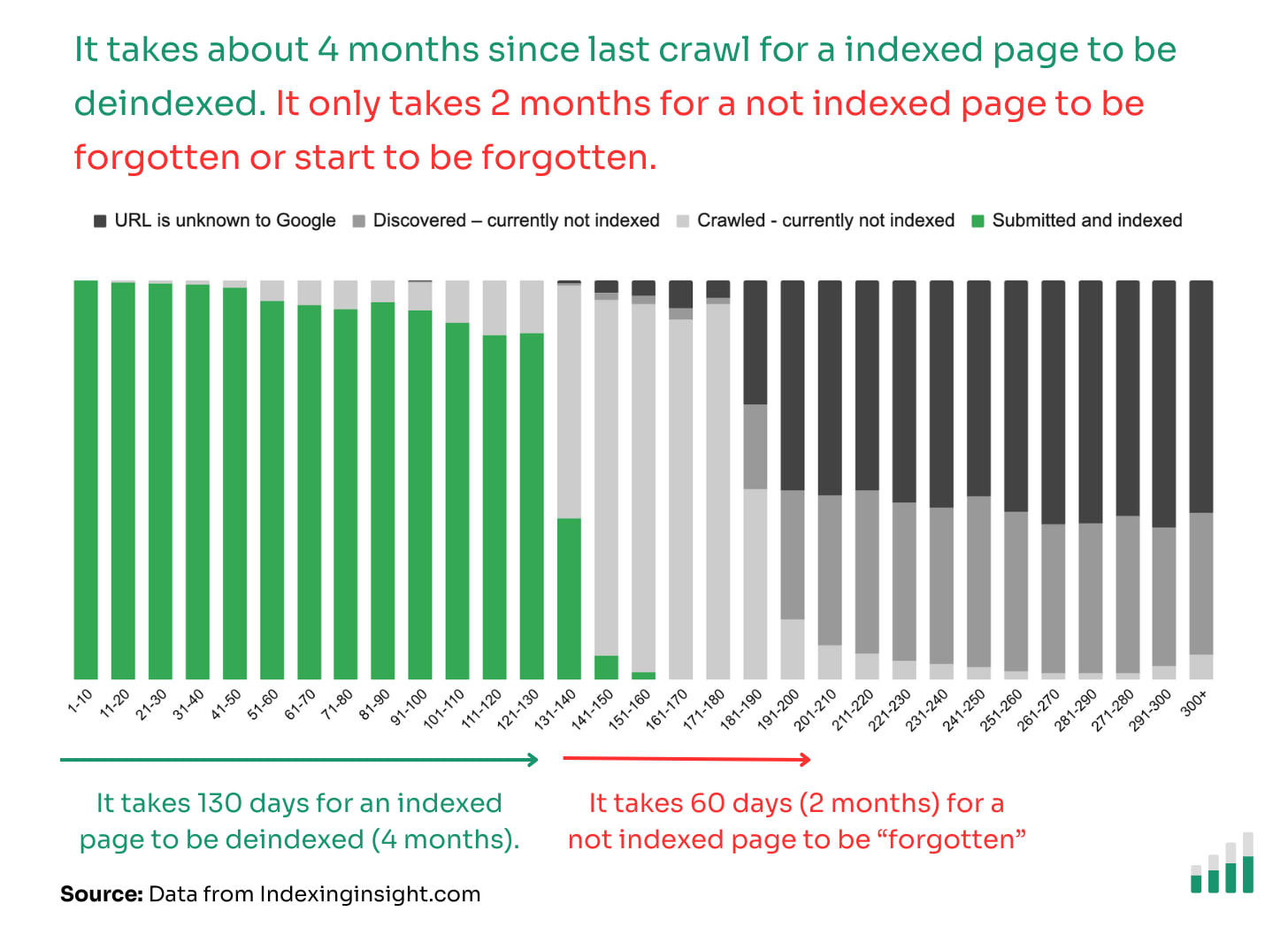
After a page has been deindexed it doesn’t take long for it to be “forgotten” by Google (zero priority) in the crawling queue.
After just 60 days of not being crawled a page can go from ‘Crawled - currently not indexed’ to ‘Discovered - currently not indexed’ or ‘URL is unknown to Google’.
It can take 4 months for Google to actively remove a page from search results (indexed to not indexed) but only 2 months for not indexed pages to start to be forgotten by Google (meaning zero or close to zero crawling priority).
🧠 Final Thoughts
SEO teams can make educated guesses on crawl frequency reflecting how important a page is to Google but our study (and research) should remove a lot of guesswork.
Now we have a clear set of benchmarks that we can use to inform our SEO strategies.
For example, when using URL Inspection API with Screaming Frog you can now start to understand the crawl priority of your indexed and not indexed pages.
Screaming Frog + Search Console URL Inspection API to identify indexing pages that are at risk of being deindexed
By understanding the crawl priority of your pages using index coverage states you can also start to uncover quality issues on your website. AND start to identify which indexed pages are at risk of being deindexed.
URL Report that includes Days Since Last Crawl
At Indexing Insight we’re working hard in the background to group pages into Days Since Last Crawl reports to help customers identify unique SEO insights that can help inform content quality.
Crawl Coverage Concept Wireframe
Do you want to monitor Google indexing and crawling at scale?
Indexing Insight is a Google indexing intelligence tool for SEO teams who want to identify, prioritise and fix indexing issues at scale.
If a page hasn’t been crawled in the last 130 days, it gets deindexed.
This is the idea that Alexis Rylko put forward in his article: Google and the 130-Day Rule. Alexis identified that by using Days Since Last Crawl metric in Screaming Frog + URL Inspection API you can quickly identify pages at risk of becoming deindexed.
Pages are at risk of being deindexed if they have not been crawled in 130 days.
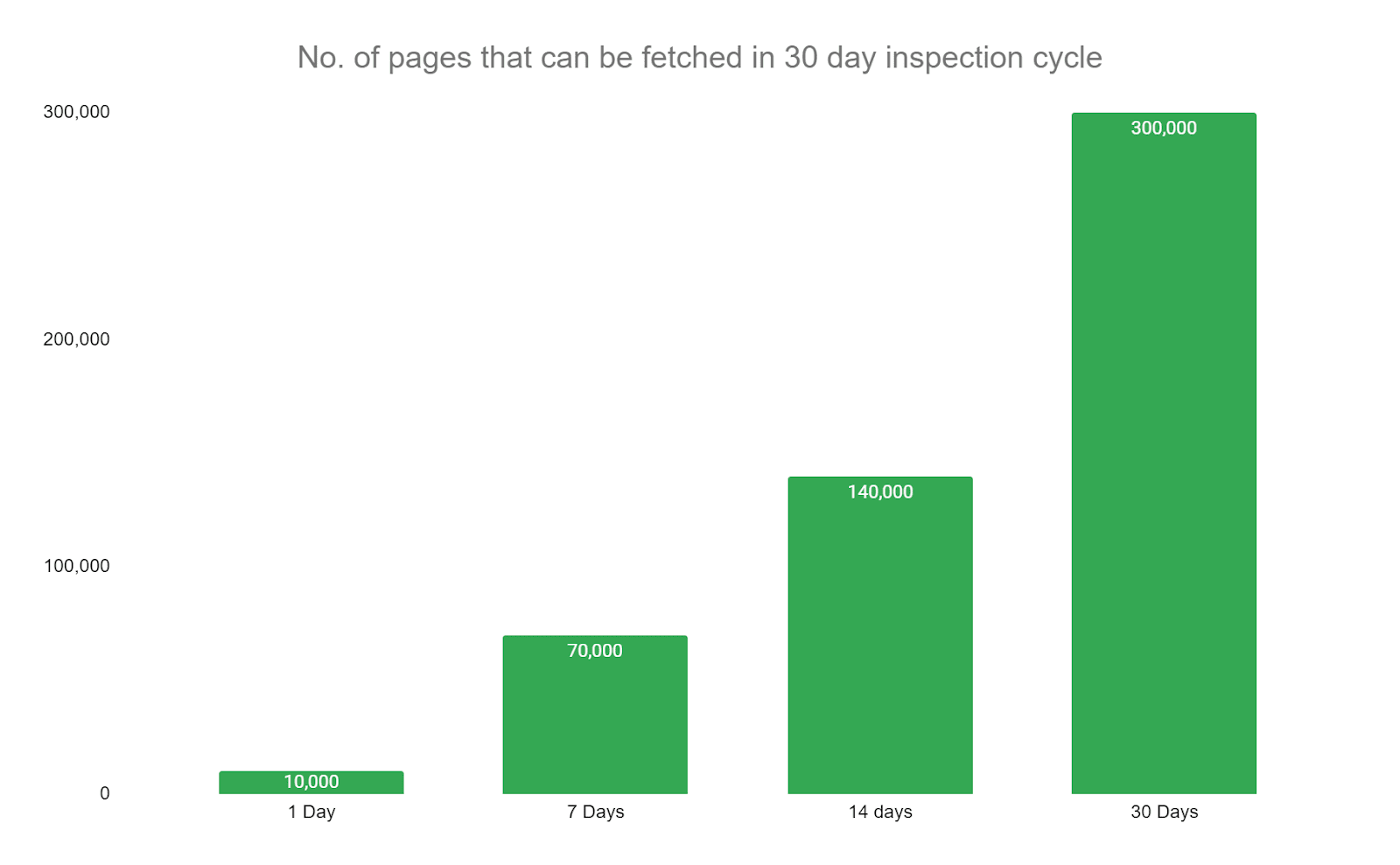
At Indexing Insight we track Days Since Last Crawl for every URL we monitor for over 1 million pages. And decided to run our own study to see if there is any truth to 130 day indexing rule.
Side note: The 130 day indexing rule isn’t a new idea. A similar rule was identified by Jolle Lahr-Eigen and Behrend v. Hülsen who found that Googlebot had a 129 days cut off in its crawling behavior in a customer project in January 2024.
💽 Methodology
The indexing data pulled in this study is from Indexing Insight. Here are a few more things to keep in mind when looking at the results:
👥 Small study: The study is based on 18 websites that use Indexing Insight of various sizes, industry types and brand authority.
⛰️ 1.4 million pages monitored: The total number of pages used in this study is 1.4 million and aggregated into categories and analysed to identify trends.
🤑 Important pages: The websites using our tool are not always monitoring ALL their pages, but they monitor the most important traffic and revenue-driving pages.
📍 Submitted via XML sitemaps: The important pages are submitted to our tool via XML sitemaps and monitored daily.
🔎 URL Inspection API: The Days Since Last Crawl metric is calculated using the Last Crawl Time metric for each page is pulled using the URL Inspection API.
🗓️ Data pulled at the end of March: The indexing states for all pages were pulled on 17/04/2025.
Only pages with last crawl time included: This study has included only pages that have a last crawl time from the URL Inspection API for both indexed or not indexed pages.
Quality type of indexing states: The data has been filtered to only look at the following quality indexing state types: ‘Submitted and indexed’, ‘Crawled - currently not indexed’, ‘Discovered - currently not indexed’ and ‘URL is unknown to Google’. We’ve filtered out any technical or duplication indexing errors.
🕵️ Findings
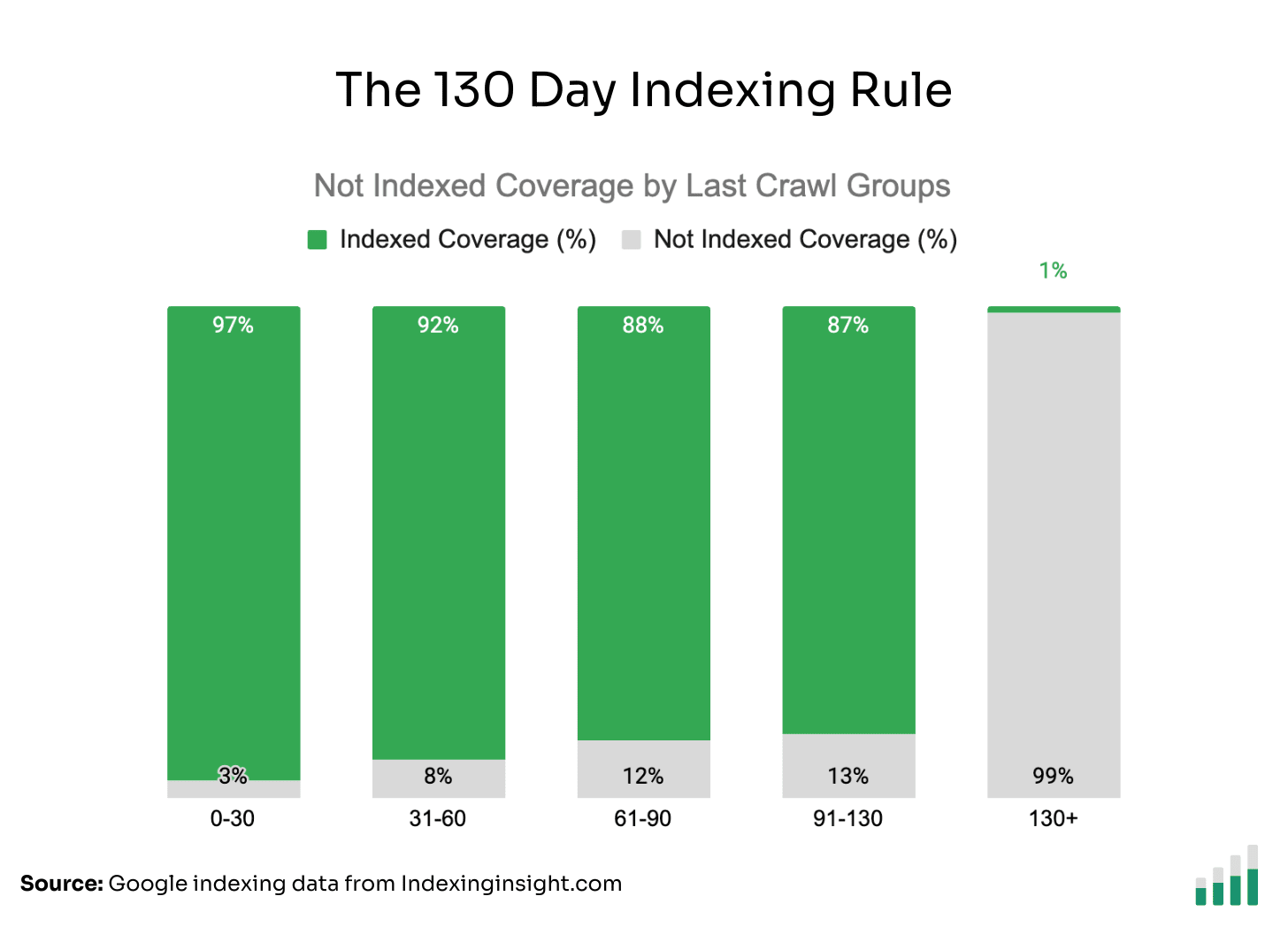
The 130-day indexing rule is true. BUT it’s more of an indicator than a hard rule.
Our data from 1.4 million pages across multiple websites shows that if a page has not been crawled in the last 130 days then there is a99% chance the page is Not Indexed.
However, there are Not Indexed pages crawled in less than 130 days.
This means that the 130-day rule is not a hard rule but more of an indicator that your pages might be deindexed by Google.
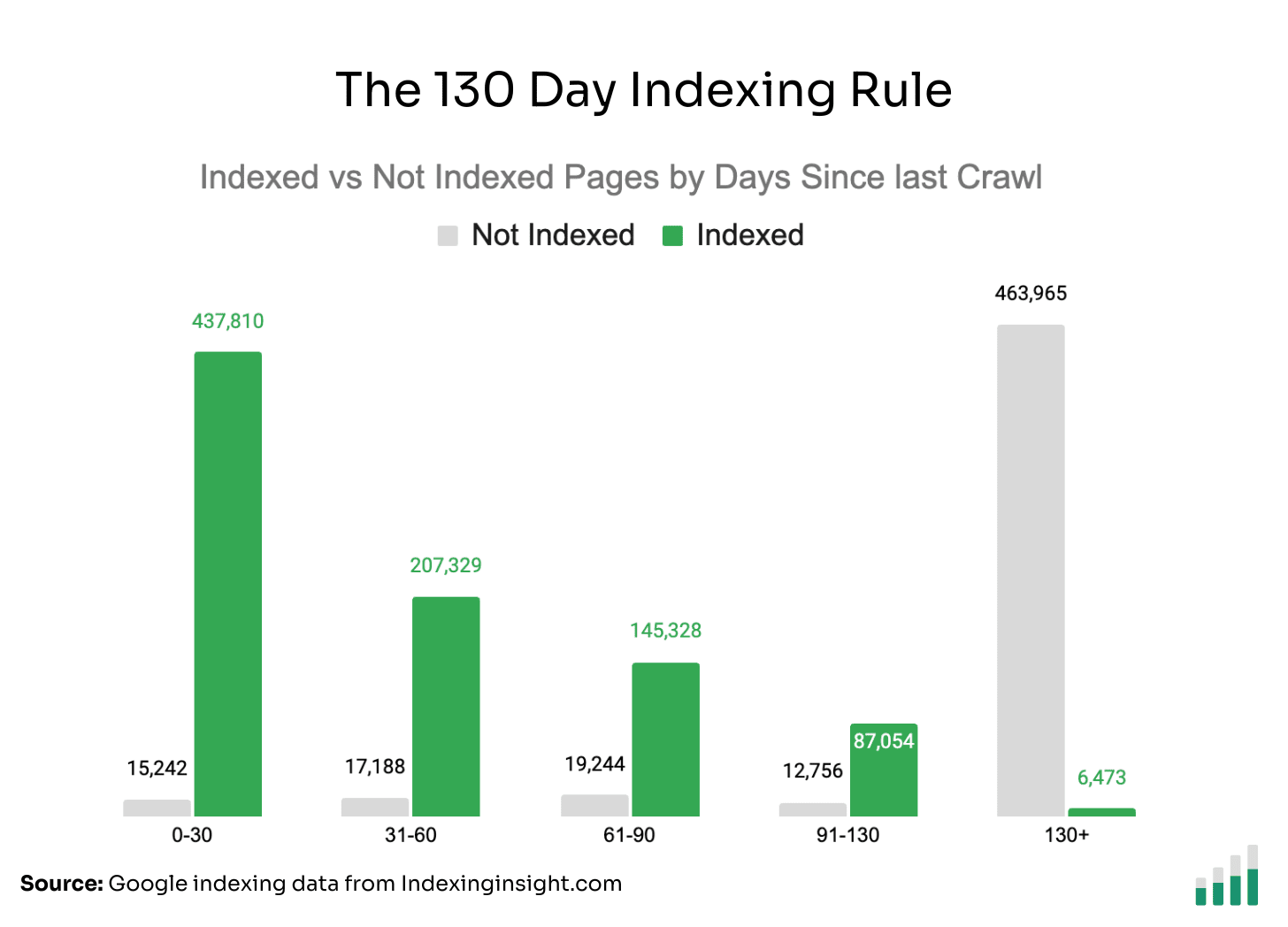
The data does show that the longer it takes for Googlebot to crawl a page, the greater the chance that the page will be Not Indexed. But after 130 days, the number of Not Indexed pages jumps from around 10% to 99%.
Below is the raw data to understand the scale of the pages in each category.
🤷♂️ What happens after 130 days?
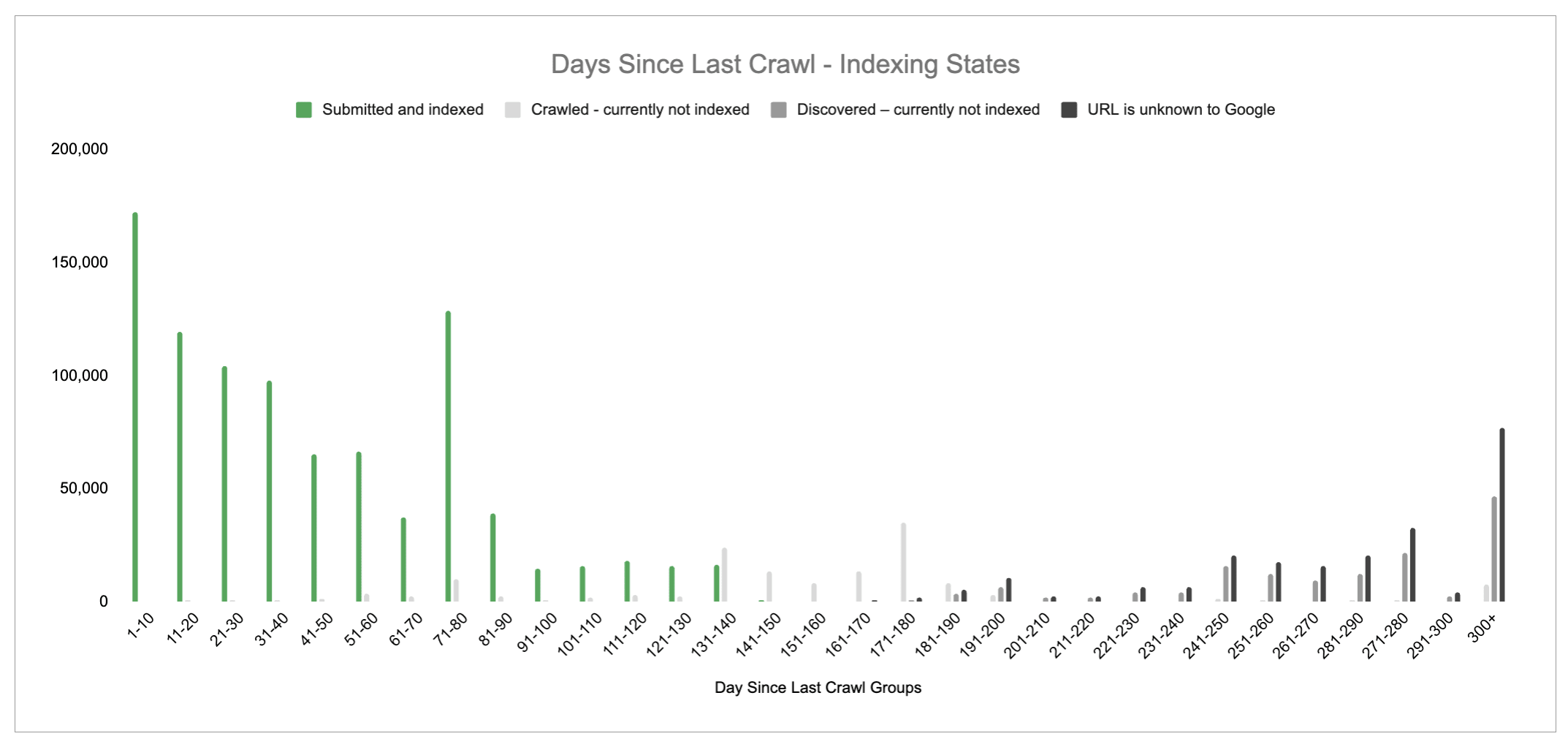
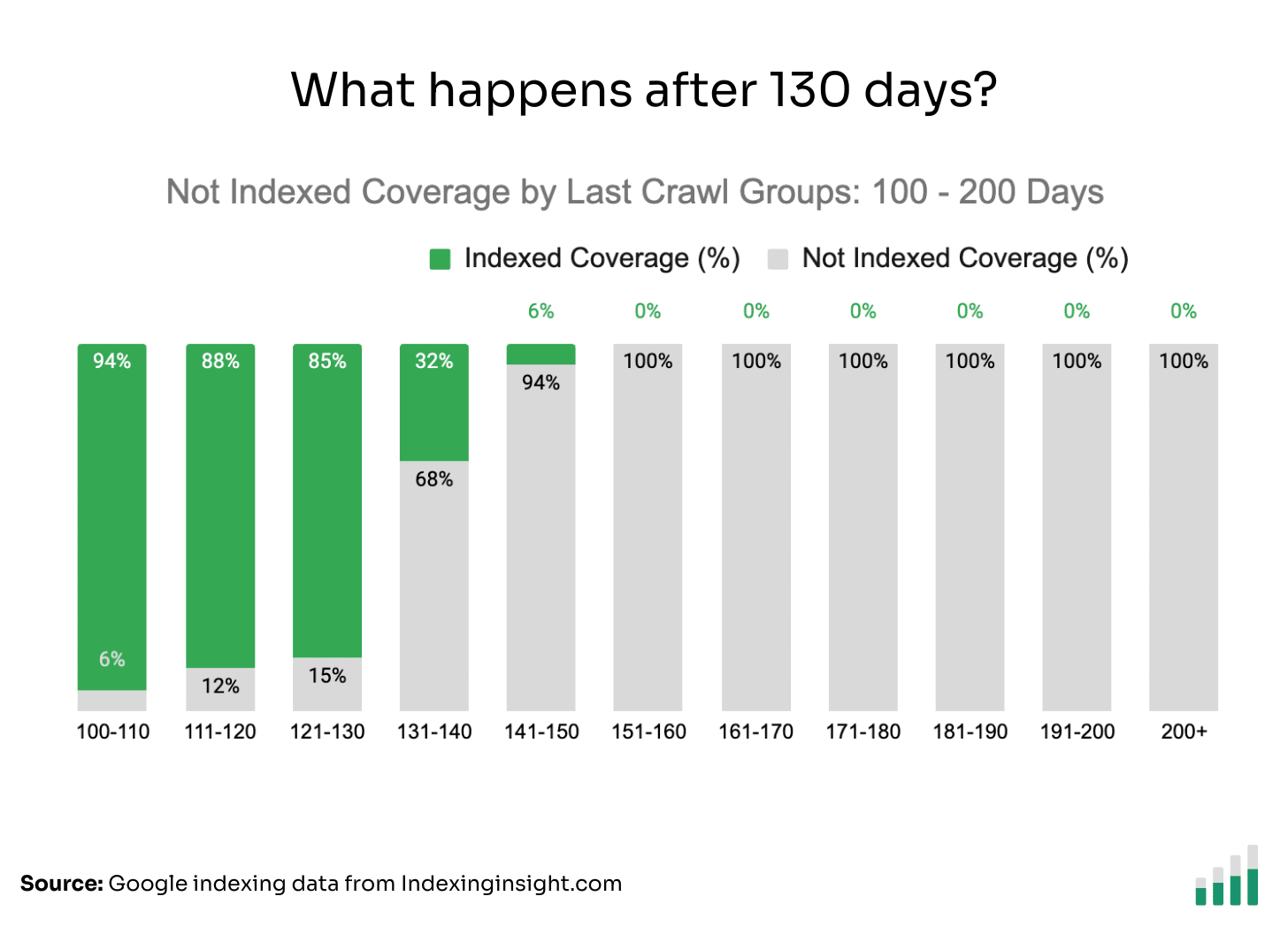
We broke down the data into last crawl buckets between 100 - 200 days.
The data shows that between 100 - 130 days the index coverage is between 94% - 85%.
But, after 131 days, the Not Index coverage shoots up.
The Not Indexed coverage state goes from 68% to 100% between 131 and 151 days. There are still pages indexed after 131 days, but the Index coverage reduces significantly between 131 - 150 days.
After 151 days, there are 0 indexed pages.
Below is the raw data to understand the scale of the pages in each crawl bucket.
🧠 Final Thoughts
The 130-day indexing rule is an indication that your pages will get deindexed.
However, it’s not a hard rule. There will be Not Indexed pages that can be crawled in the last 130 days. Based on the data, 2 rules stand out when it comes to tracking days since last crawl:
🔴 130-day rule: If a page hasn’t been crawled in the last 130 days, then there is a 99% chance the page will not be indexed.
🟢 30-day rule: If the page has been crawled in the last 30 days, then there is a 97% chance the page is indexed.
The longer it takes for Googlebot to crawl your pages (130+ days), the greater the chance the pages will be not indexed.
This shouldn’t come as a surprise to many experienced SEO professionals.
The idea of crawl optimisation and tracking days since last crawl is not new. Over the last 10 years, many SEO professionals like AJ Kohn have talked about the idea of CrawlRank. And Dawn Anderson has provided deep technical explanations on how Googlebot crawling tiers work.
To summarise their work in a nutshell:
Pages crawled less frequently compared to your competitors receive less SEO traffic. You win if you get your important pages crawled more often by Googlebot than your competition.
The issue has always been tracking days since the last crawl for many websites at scale and identifying the exact length of time when pages are deindexed.
However, at Indexing Insight, we can automatically track the last crawl time for every page we monitor AND calculate the days since last crawl for every page.
What does this mean?
It means very soon we’ll be able to add new reports to Indexing Insight that allow customers to, at scale, identify which important pages are at risk of being deindexed. And allow you to monitor how long it takes for Googlebot to crawl important pages for your website.
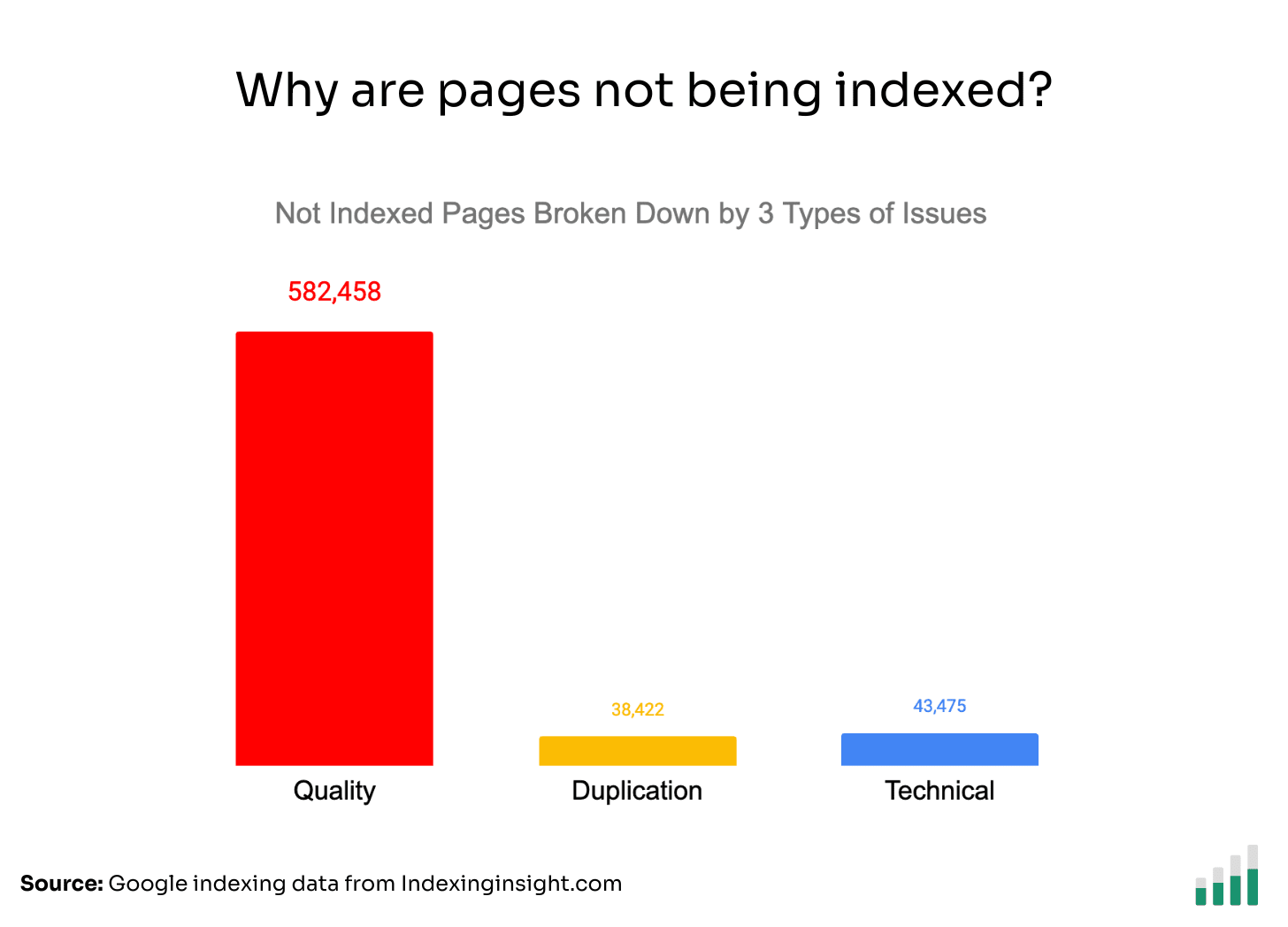
Google is actively removing pages from its search results.
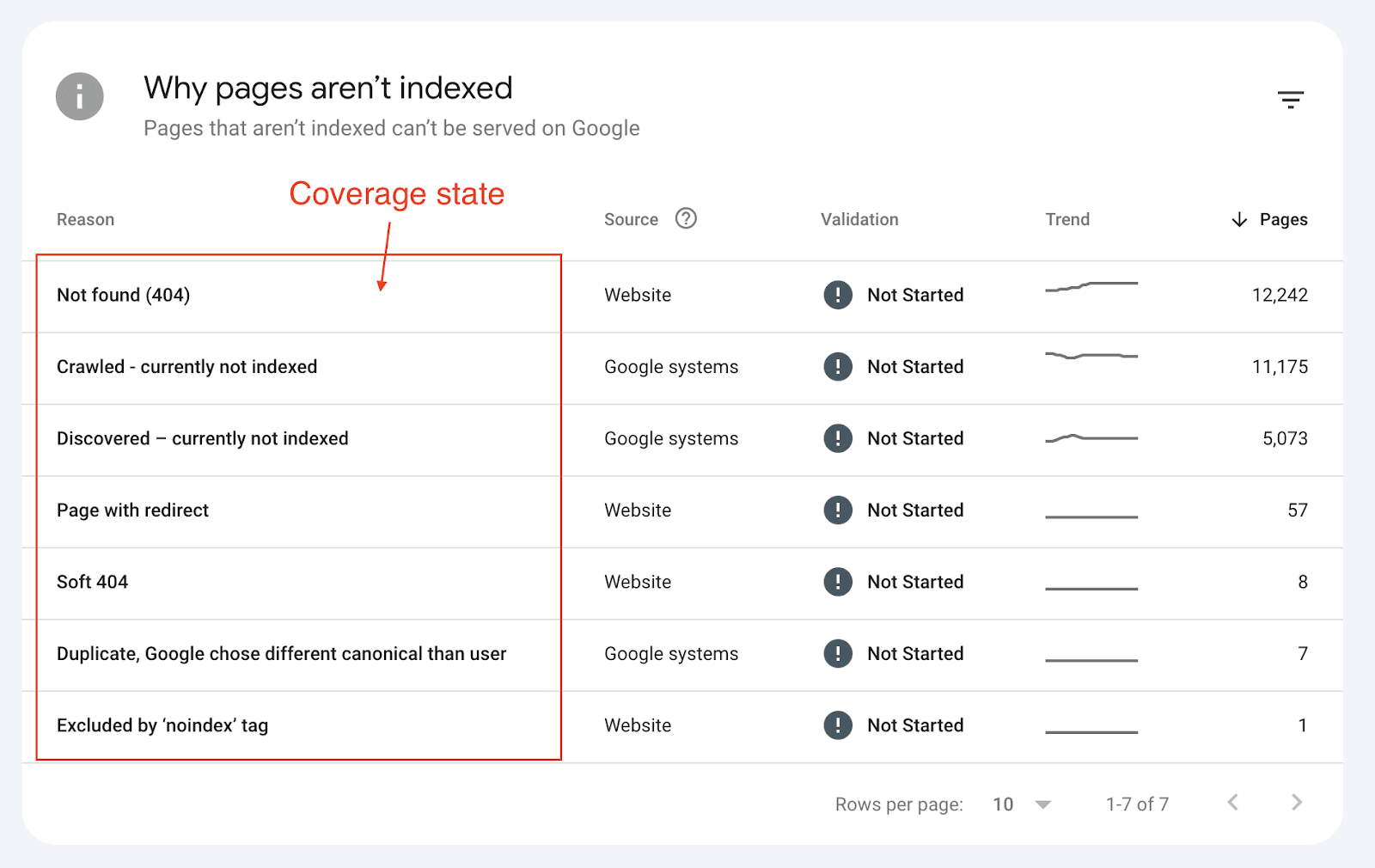
At Indexing Insight, we analysed the indexing data of 1.7 million pages across 18 websites. And found that 88% of not indexed pages were due to quality issues.
Important pages are actively being removed and forgotten by Google.
It doesn’t matter if you’re a large or small website. A big brand or a small brand. The trend is always the same. The biggest reason why your pages are not indexed is that they are actively being removed and forgotten by Google’s index.
Let’s dive into the methodology and findings.
💽 Methodology
The indexing data pulled in this study is from Indexing Insight. Here are a few more things to keep in mind when looking at the results:
👥 Small study: The study is based on 18 websites that use Indexing Insight of various sizes, industry types and brand authority.
⛰️ 1.7 million pages monitored: The total number of pages used in this study is 1.7 million and aggregated into categories and analysed to identify trends.
🤑 Important pages: The websites using our tool are not always monitoring ALL their pages, but they monitor the most important traffic and revenue-driving pages.
📍 Submitted via XML sitemaps: The important pages are submitted to our tool via XML sitemaps and monitored daily.
🔎 URL Inspection API: The indexing verdict (Indexed vs Not Indexed) and the indexing state for all the pages have been pulled using the URL Inspection API.
🗓️ Data pulled at the end of March: The indexing states for all pages were pulled on 31/03/2025.
Only inspected pages included: This study has included only pages that have an indexed or not indexed verdict (this means some websites do not have all the data included).
Alright, let’s jump into the findings!
🕵️ Indexing Study Findings
Based on our first-party data, this is what we found (and it surprised us!).
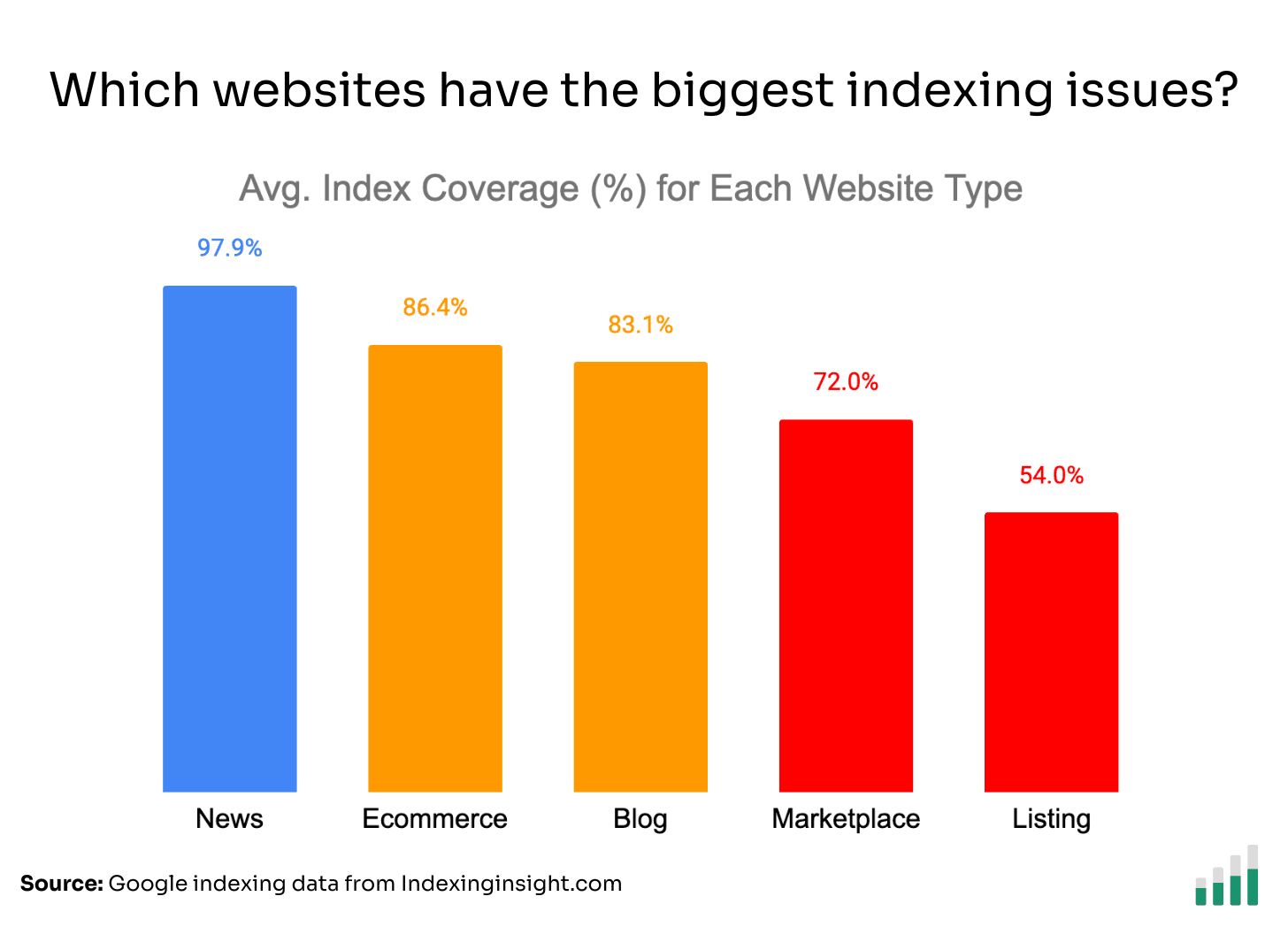
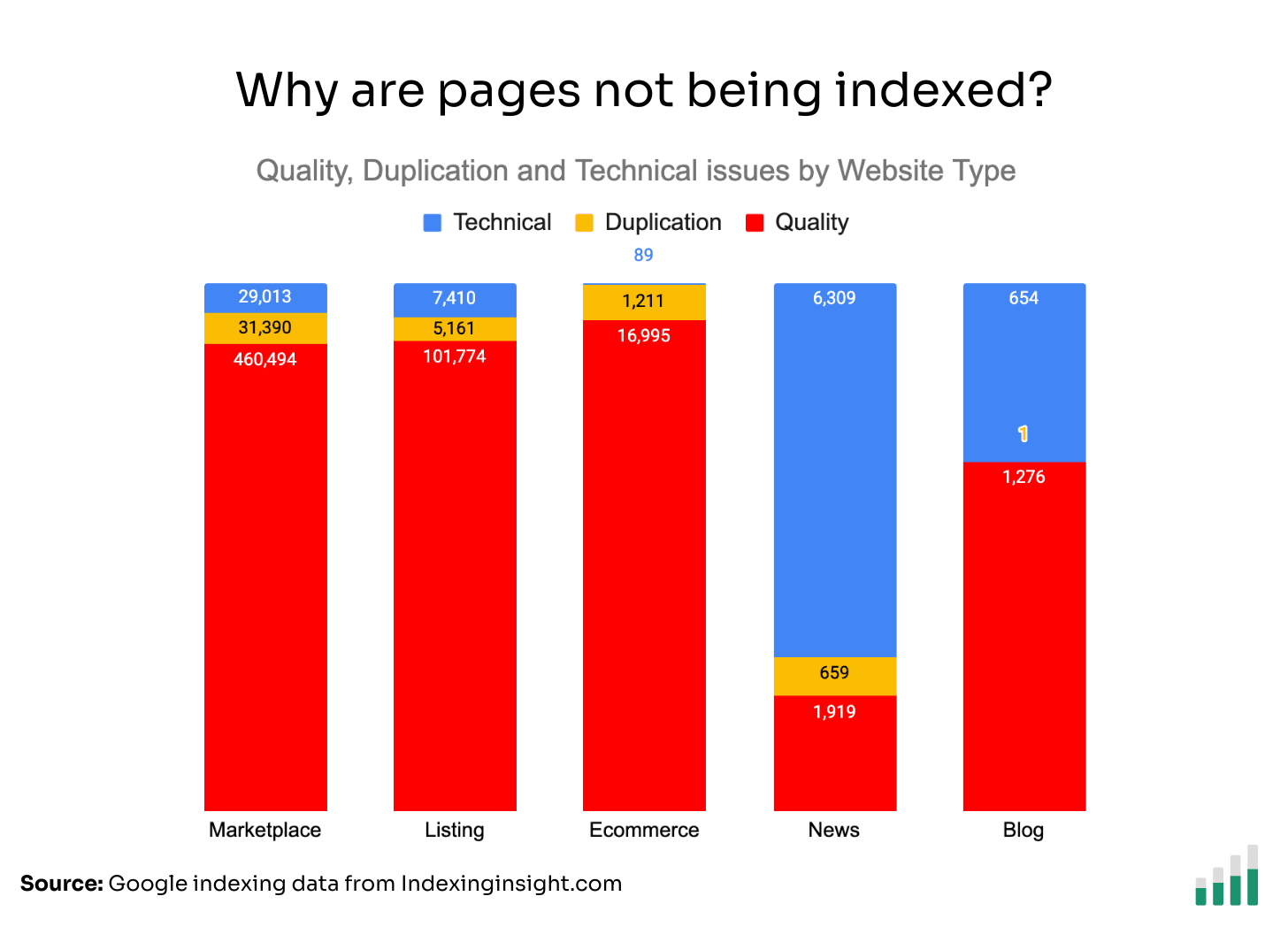
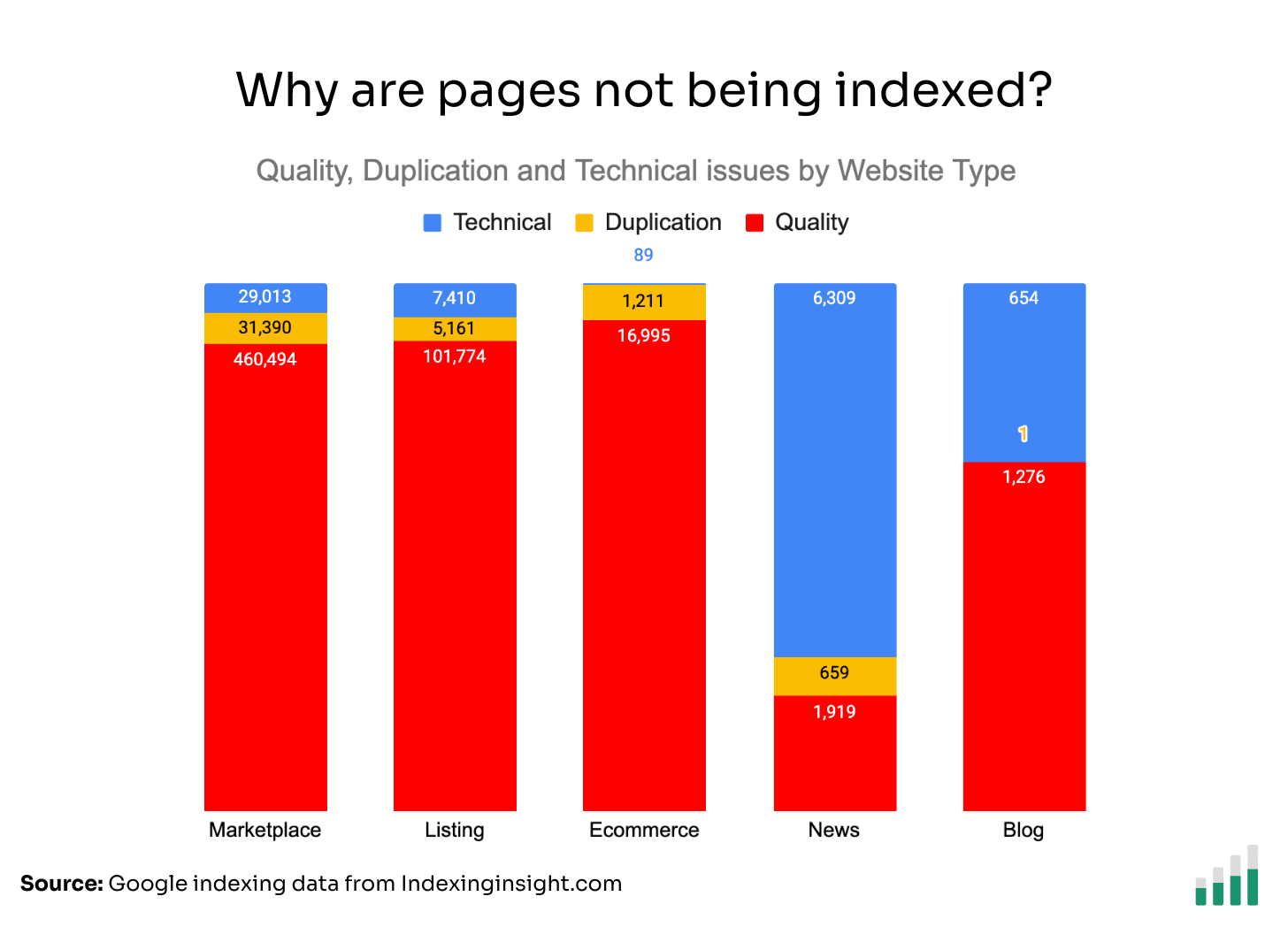
🗼 Marketplace & listing sites have the biggest issues
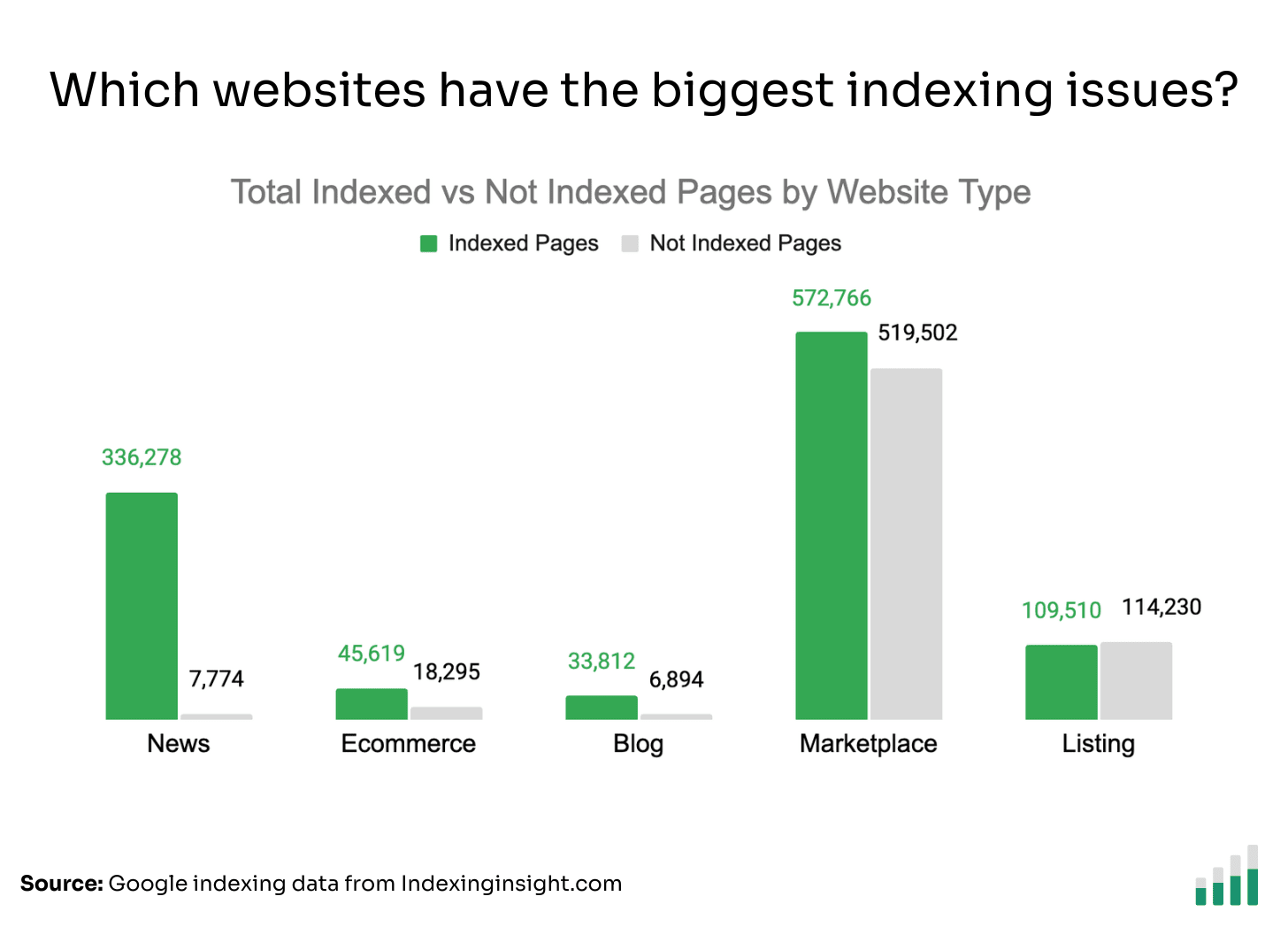
The indexing data shows that marketplace and listing websites have the lowest Indexing Coverage score >70% (the % of pages indexed vs total monitored pages).
News websites had the best Index Coverage score for monitored pages at 97%.
Ecommerce websites didn’t have as many indexing issues, but still had less than 90% Index Coverage score for all the monitored pages.
Side note: Index Coverage score is a metric to indicate the scale of your indexing issues for a website or set of monitored pages. You want to aim for 90% or more.
If we look at the raw indexed vs not indexed page numbers, we can see the scale of the indexing issues for marketplace and listing websites.
They make up a lot of the indexing issues we monitor.
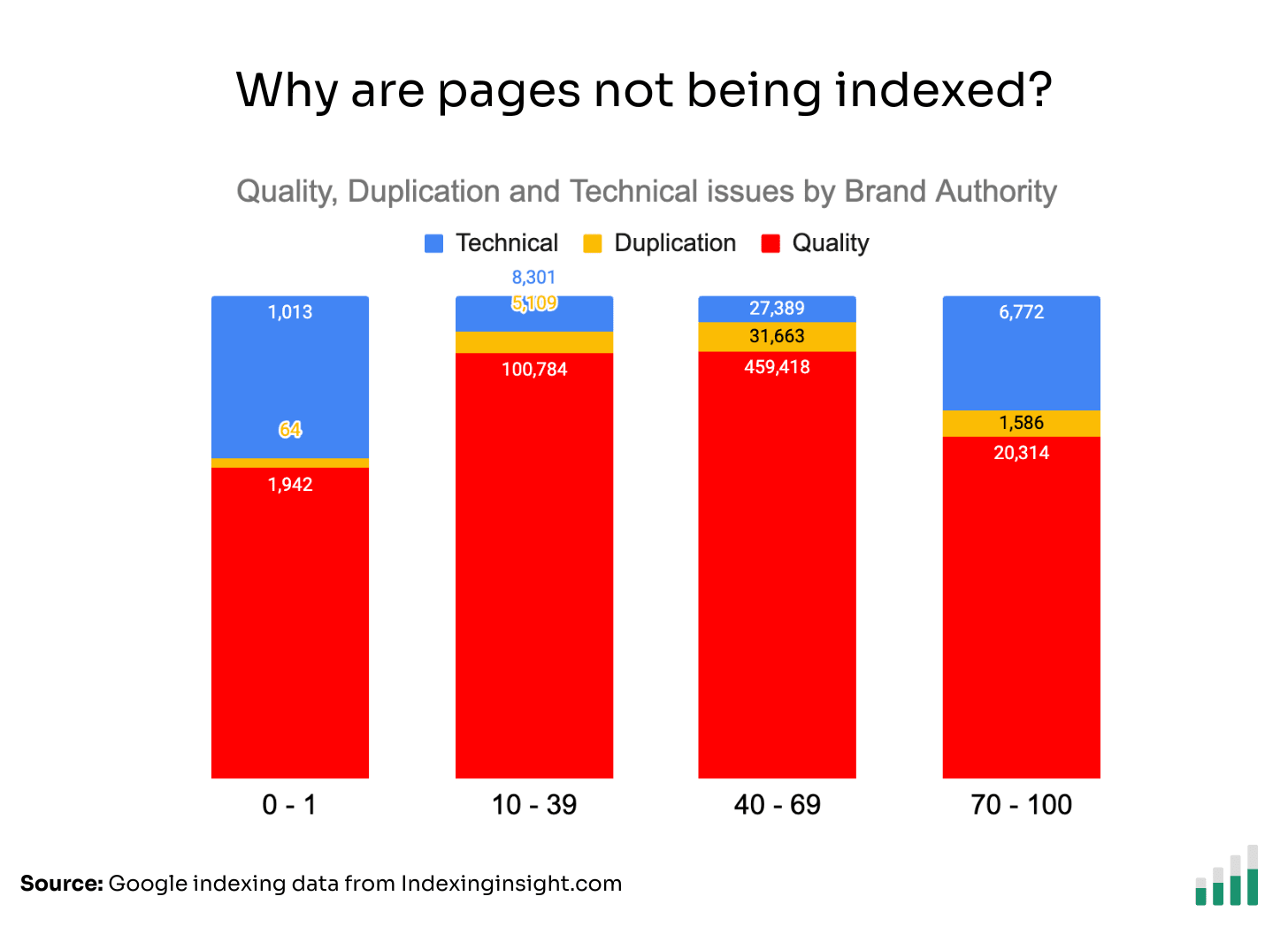
🏦 Brands suffer from indexing issues
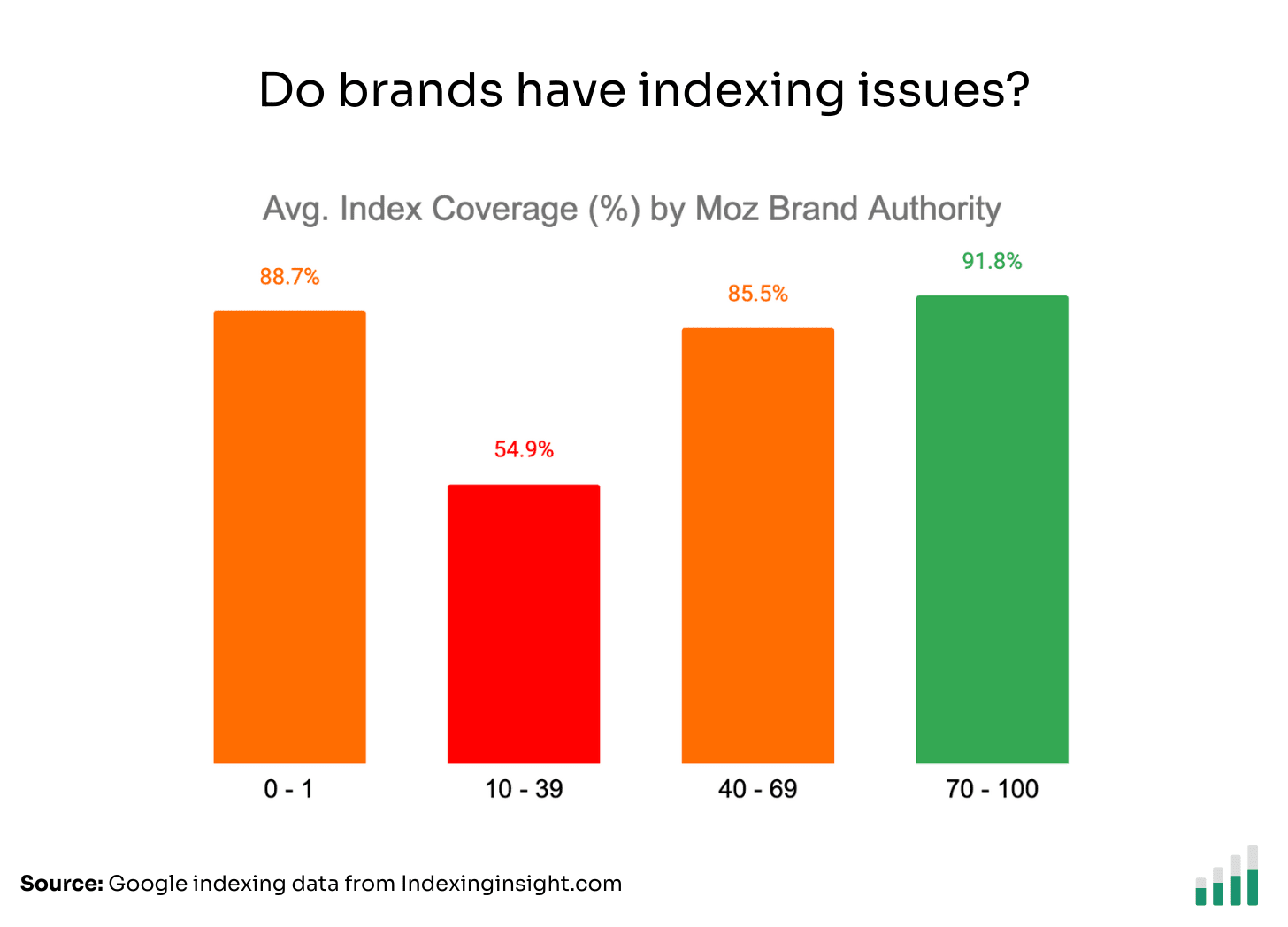
If we layer Moz Brand Authority with our indexing data we can see that even big brands suffer from indexing issues for important traffic and revenue-driving pages.
The indexing data shows that both small and big brands have an Index Coverage score around 85 - 91%.
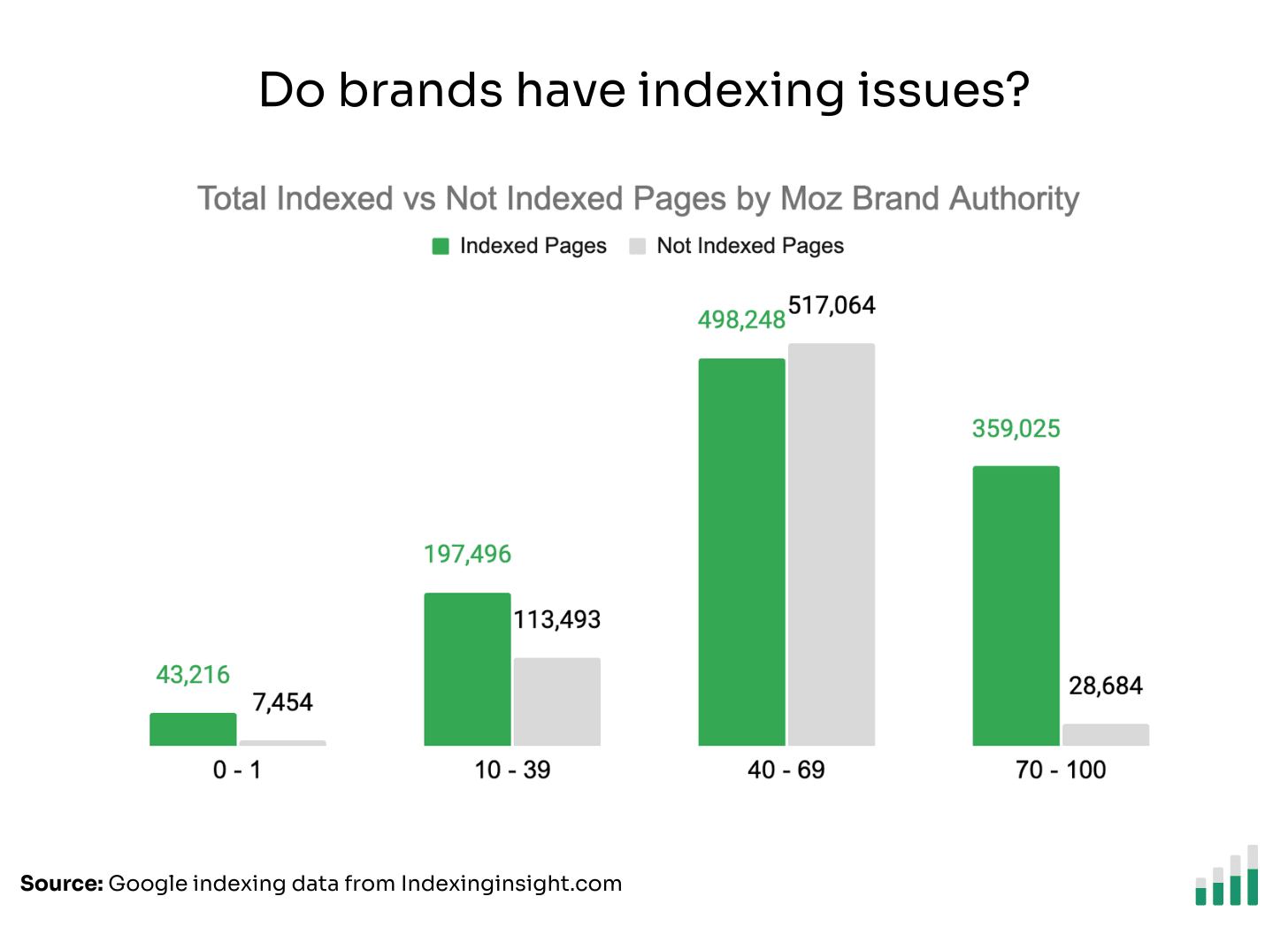
If we look at the raw data for indexed vs not indexed pages by Moz Brand Authority, we can see the scale of the problem for brands.
The indexing data shows that even big brands suffer from large-scale indexing issues.
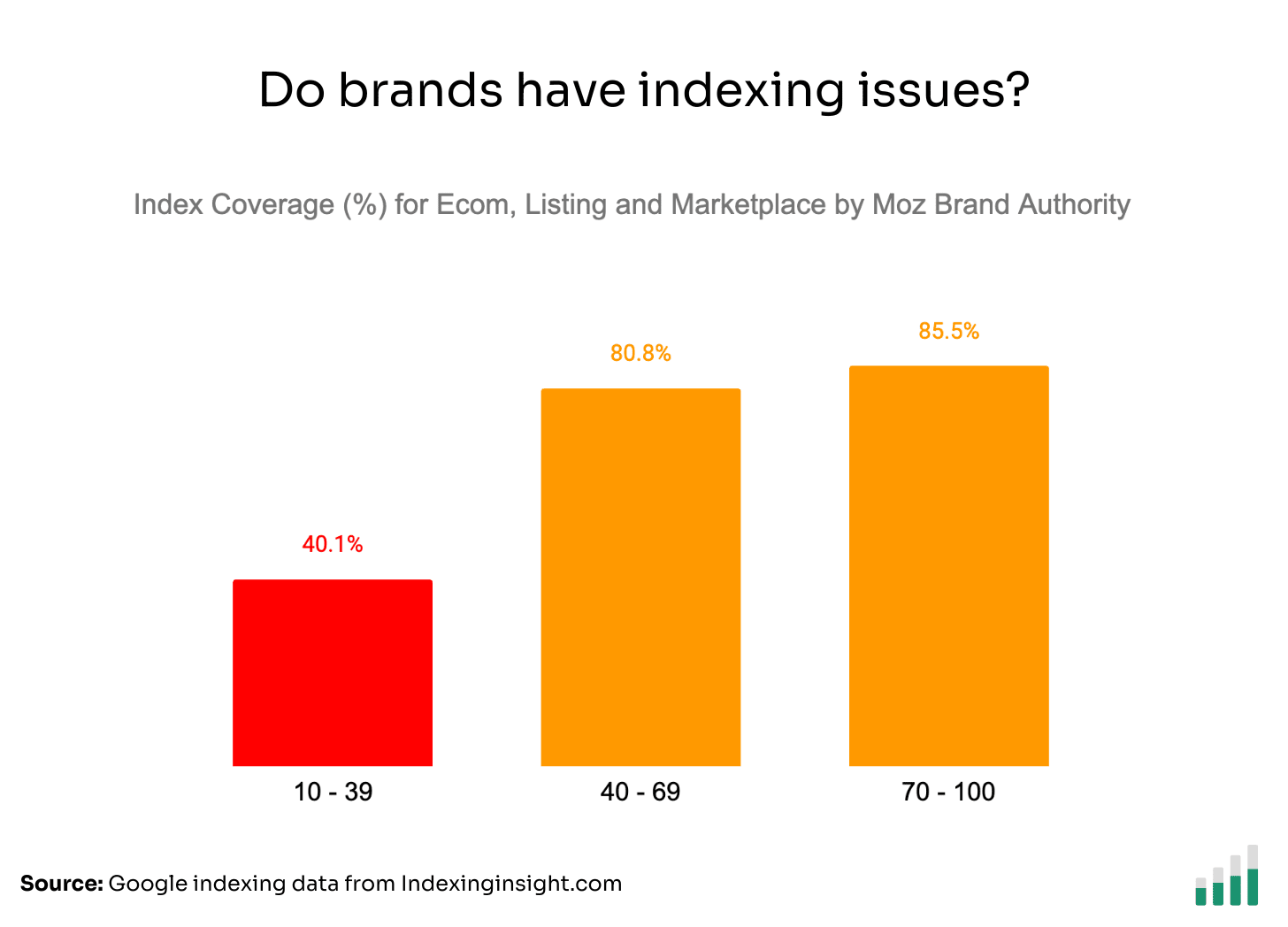
Interestingly, if you only focus on ecommerce, marketplace and listing websites, the average Index Coverage score by Moz Brand Authority is lowered.
Big and small brands with Ecommerce, Marketplace and Listing websites suffer from much larger-scale indexing issues than news or blog websites.
This makes sense as these sorts of websites have lots more pages in our data set.
It doesn’t matter how we chop or slice the not indexed pages, the trend is always the same:
Quality indexing issues are the biggest reason why important pages are not indexed.
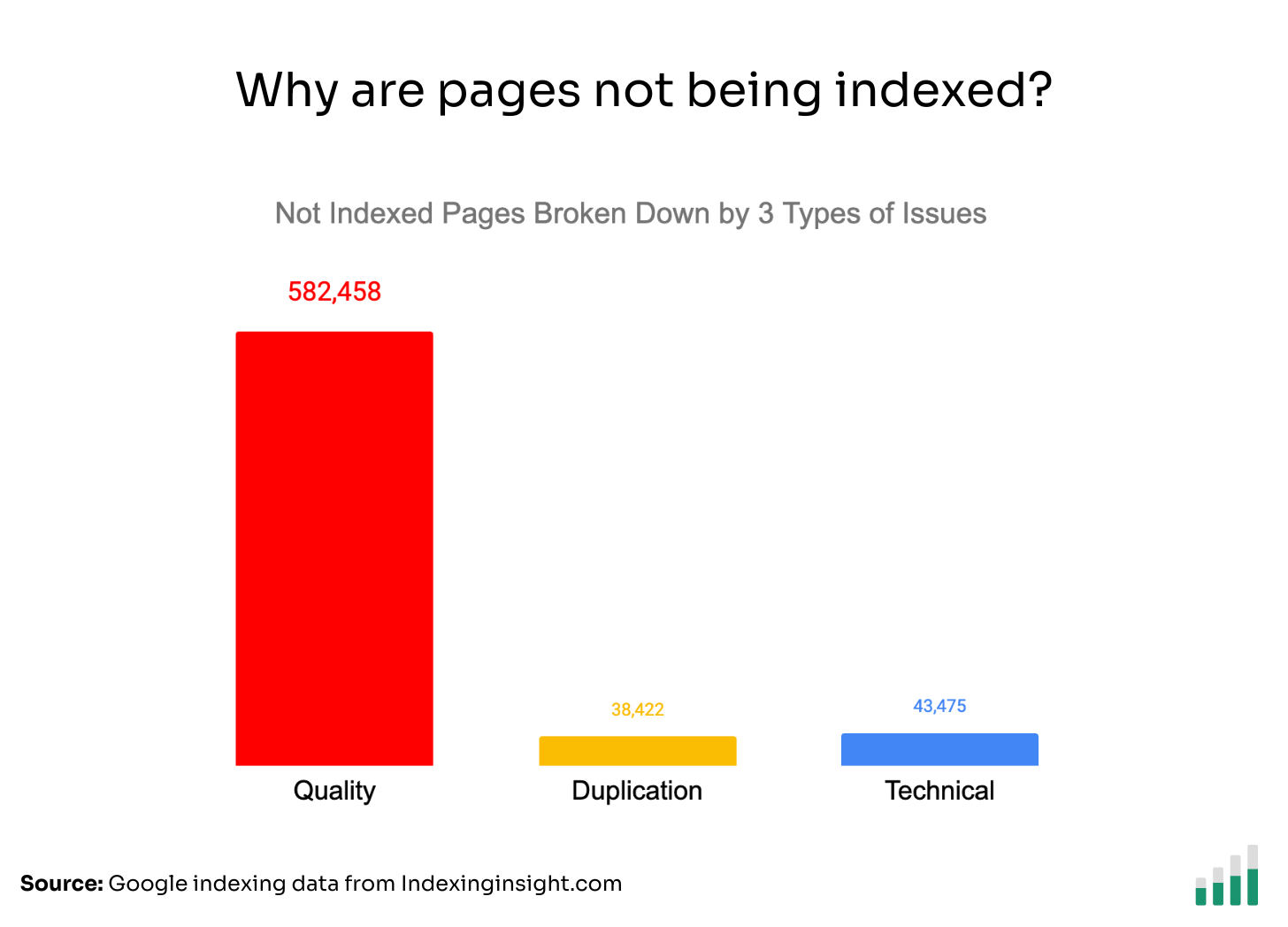
If we group all the not indexed pages across all the websites into the 3 types of indexing issues, we can see that quality issues make up 88% of all monitored indexing issues.
How do you define quality?
Quality is Indexed pages being actively removed from Google’s search results, and Not Indexed pages actively being forgotten by the search index over time.
Learn more about quality not indexed category here.
This means that the biggest reason why important pages are not indexed is that they are being actively removed from Google’s search results and, over time, forgotten.
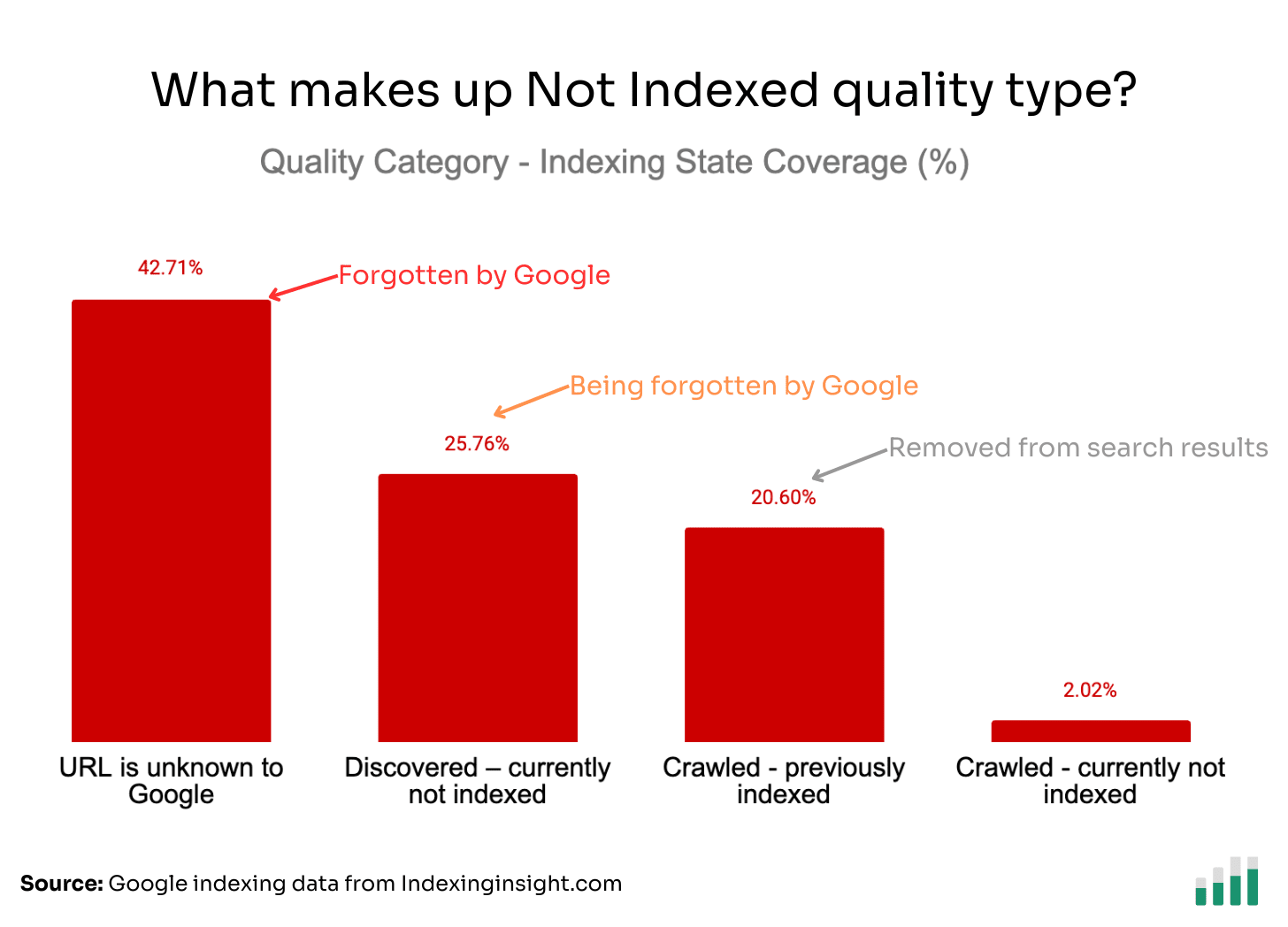
Let's break down the quality type by indexing state.
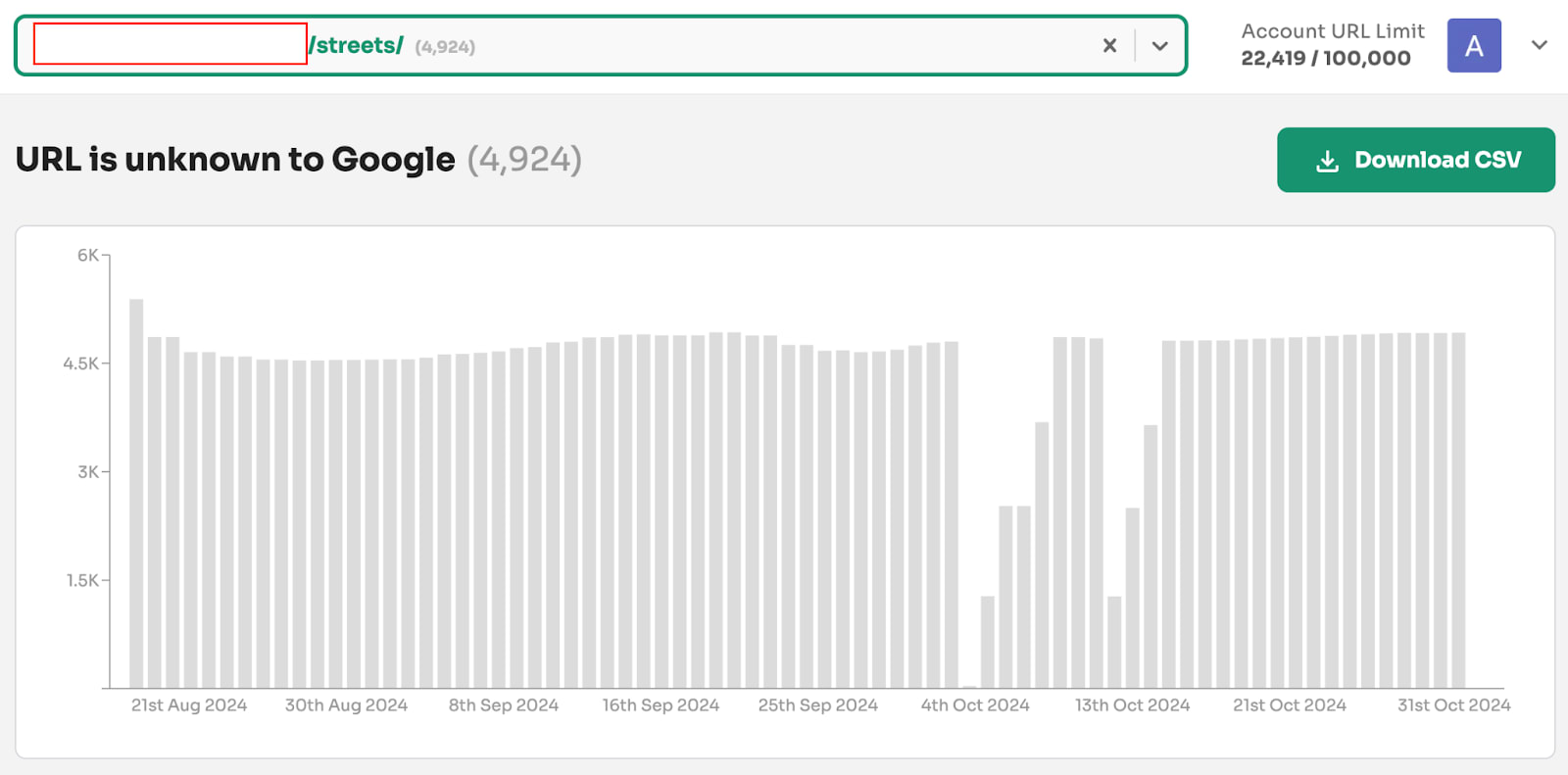
You can see that ‘URL is unknown to Google’ and ‘Discovered - currently not indexed’ make up 67% of the 500,000+ not indexed pages in the quality type.
These might appear to be crawling issues, but are in reality indexing issues.
Our research has found that ‘URL is unknown to Google’, ‘Crawled - currently not indexed’, and ‘Discovered - currently not indexed’ need new definitions. Indexing states for not indexed pages can change over time as Google actively removes and forgets pages.
Side note: You can learn more about our indexing state changes:
Quality indexing issues are impacting different websites and brand sizes.
Even if we group the 3 types of not indexed pages by Moz brand authority, we get the same trend: Quality indexing issues are the biggest reason why important pages are not indexed for big, medium or small brands.
If we group the 3 types of indexing issues by website type, we get the same trend for e-commerce, marketplace and listing websites. Quality indexing issues are the biggest reason important pages are not indexed.
Interestingly, news websites suffer more from technical indexing issues.
Finally, if we then group the 3 types of not indexed pages by website size, we can see the same trend: Quality indexing issues are the biggest reason why important pages are not indexed across both small and large websites.
The only exception to this rule is websites that are monitoring 100,000 - 500,000 pages. As most of the websites in this category are news websites.
🧠 Final Thoughts
The findings from our indexing data were surprising.
Although we’ve seen Google actively remove pages, we were surprised to find the scale of quality issues across all monitored pages.
Ever wondered why some of your important pages aren't indexed in Google?
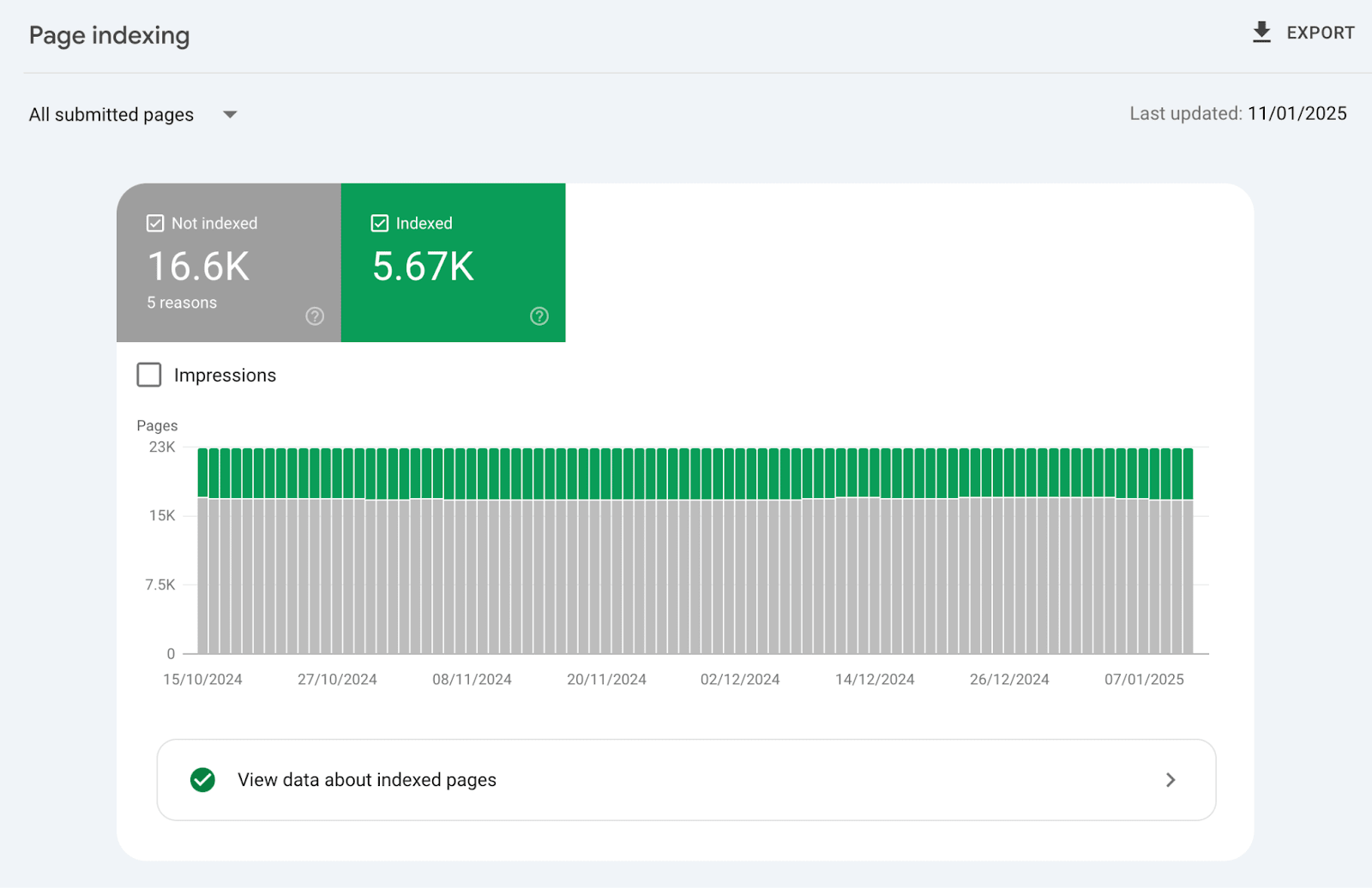
Despite submitting your URLs through XML sitemaps and following best practices, many pages still end up in the dreaded "Not Indexed" category in Google Search Console.
In this newsletter, I'll explain the 3 common types of Not Indexed pages that every SEO professional should know about. And how to identify which category your pages fall into.
So, let's dive in.
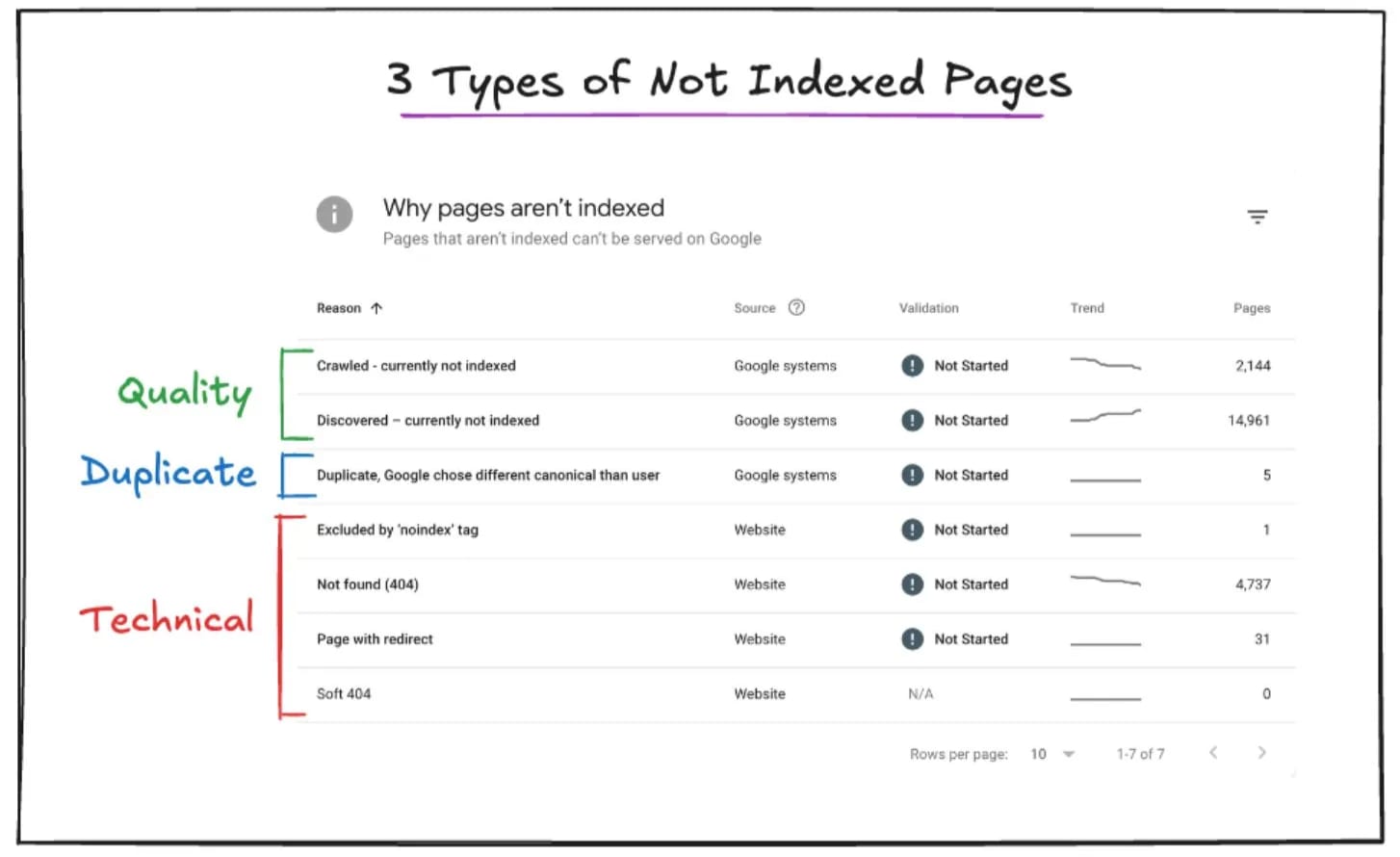
🪝 Three Types of Not Indexed Pages
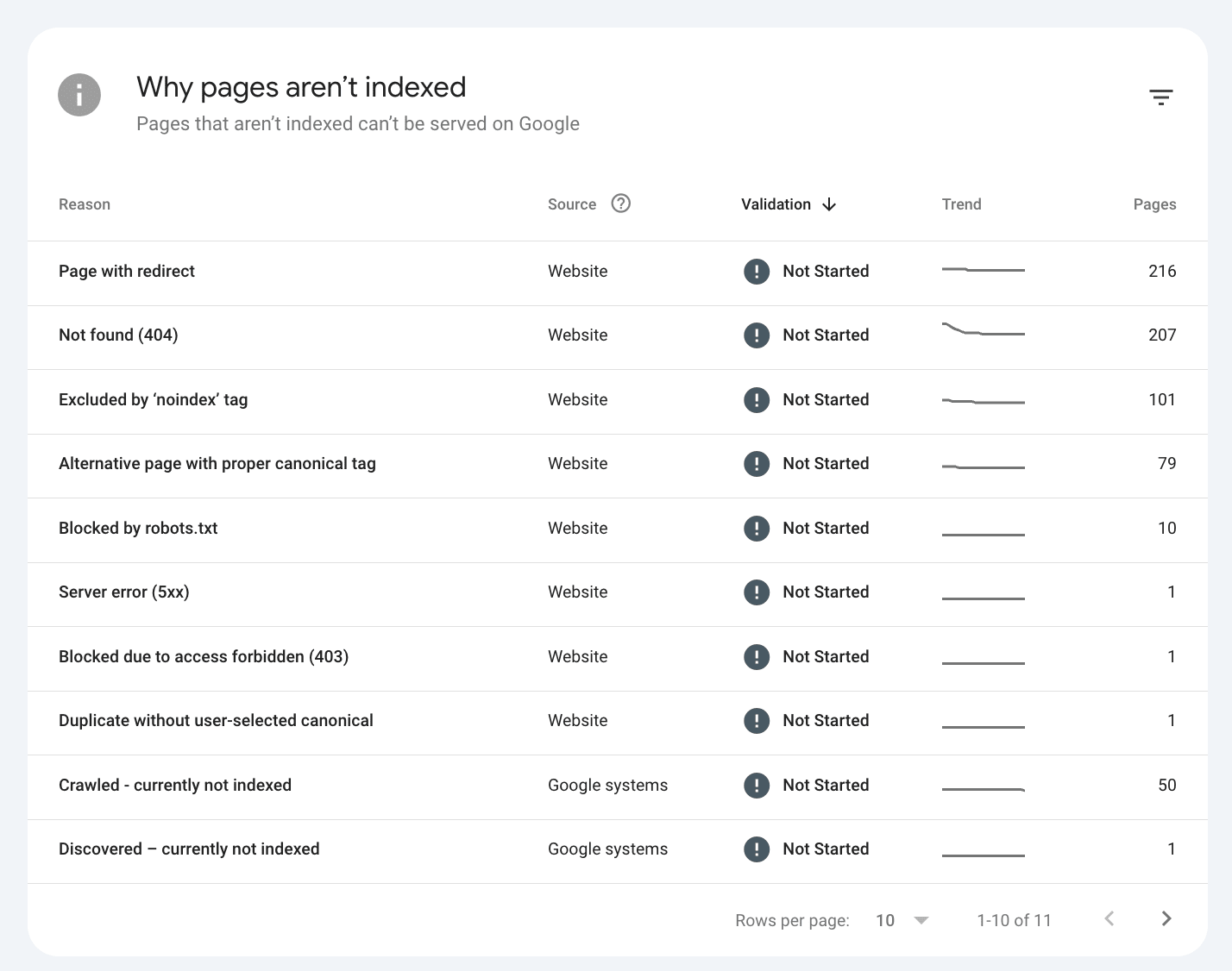
The three types of Not Indexed pages are:
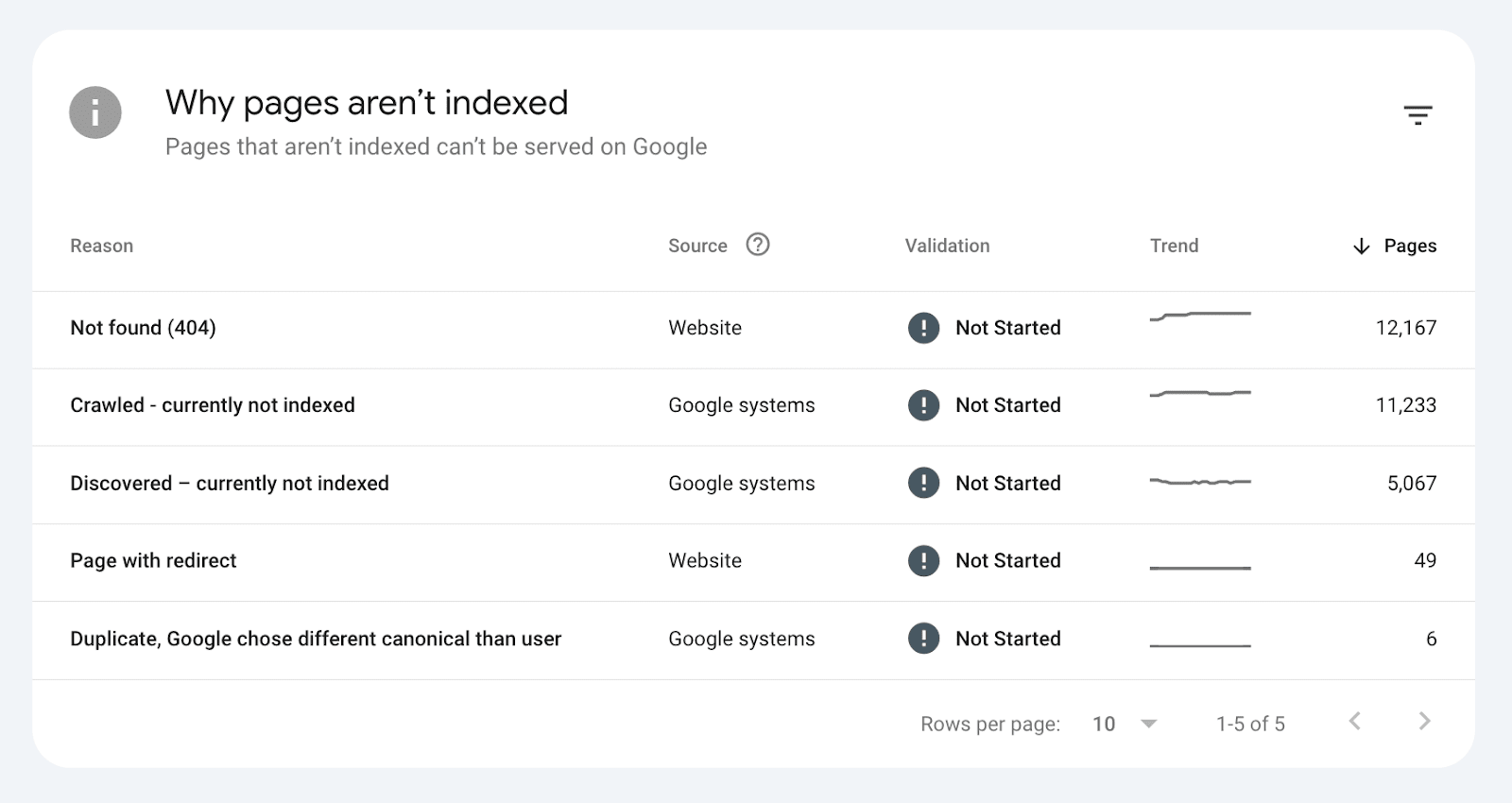
1️⃣ Technical: These Not Indexed errors are about pages that either don't meet Google's basic technical requirements or have directives to stop Google from indexing the page.
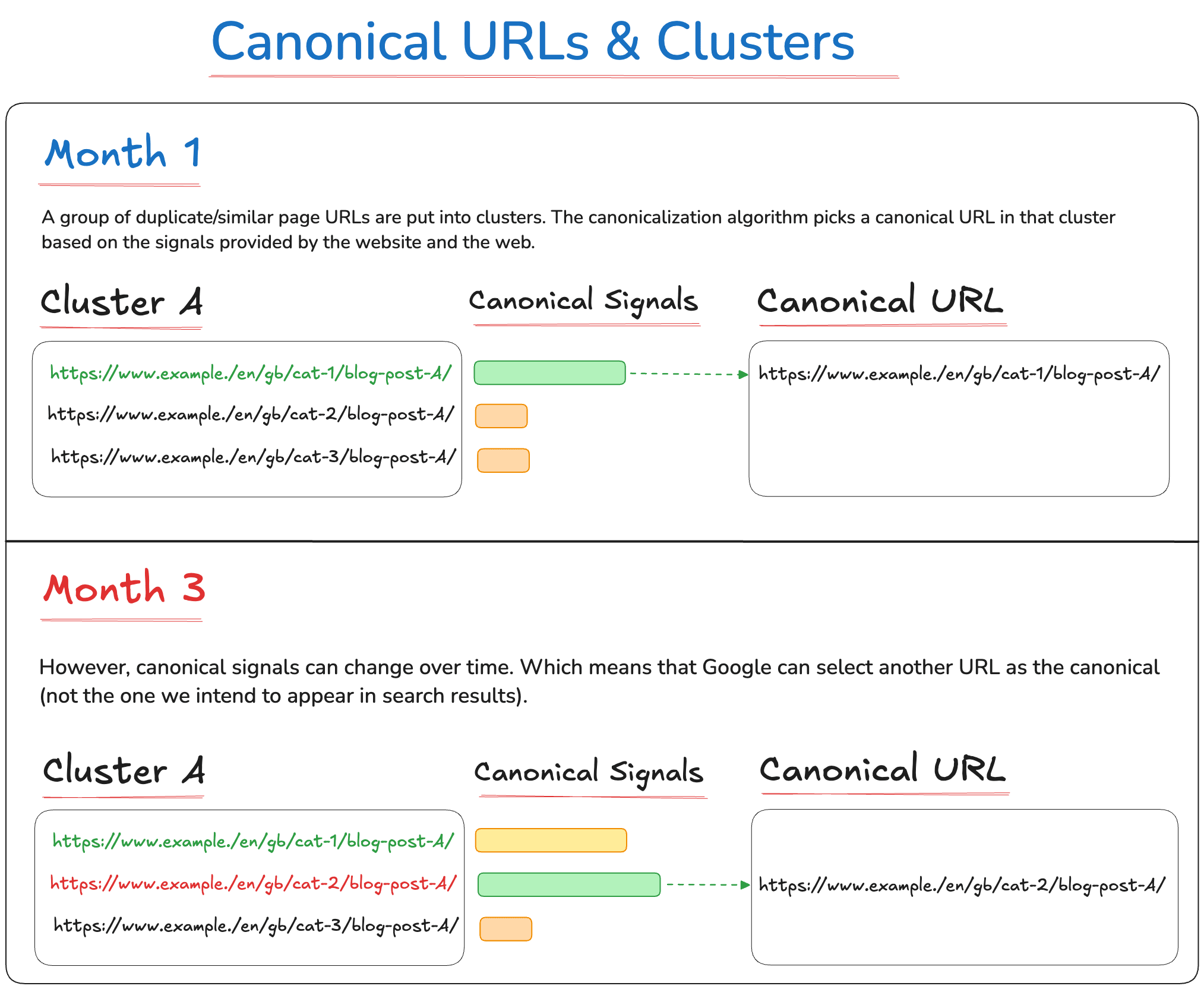
2️⃣ Duplication: These Not Indexed errors are about pages that trigger Google’s canonicalization algorithm, and a canonical URL is selected from a group of duplicate pages.
3️⃣ Quality: These Not Indexed errors are about pages that are actively being removed from Google’s search results and, over time, forgotten.
Let’s dive into each one and understand them better!
🆚 Important vs Unimportant Pages
Before we dive in, I want to separate out important and unimportant pages.
When trying to fix indexing issues, you should always separate pages into two types:
🥇 Important pages
😒 Unimportant pages
🥇 Important page
An important page are pages that you want to:
Appear in search results to help drive traffic and/or sales
Help pass link signals to other important pages (e.g. /blog)
For example, if you’re an ecommerce website, you want your product pages to be crawled, indexed and ranked for relevant keywords.
You also want your /blog listing page to be indexed so it passes PageRank (link signals) to your blog posts. So, these important page types can also appear in search results and drive SEO traffic.
😒 Unimportant page
Unimportant pages are pages that you don’t want to:
Appear in search results
Waste Googlebot crawl budget
Help pass link signals to other pages.
This doesn’t mean we just ignore these pages completely. It just means we’re not spending time trying to get these page types indexed in Google.
For example, a lot of ecommerce content management systems (CMS) by default will generate query strings (parameter URLs) which can be crawled and indexed by Google. And we need to properly handle these URLs to help Google not index the pages.
↔️ How do you identify important vs unimportant pages?
The best way to separate important and unimportant pages is with XML sitemaps.
An XML sitemap that contains your important pages submitted to Google Search Console will allow you to filter the page indexing report by submitted (important) vs. unsubmitted (unimportant) pages.
Right, now let’s dive in!
1️⃣ Minimum Technical Requirements
The first type of error is about the minimum technical requirements to get indexed.
What are these types of errors?
These pages either don't meet Google's basic technical requirements or have directives that explicitly tell Google not to index them:
2) Google receives an HTTP 200 (success) status code
If an important page is NOT returning a HTTP 200 (success) status code then Googlebot will not index the page.
There are 3 reasons an important page is returning non-200 status code:
The non-200 status is not intentional (and needs to return a 200 status code)
The non-200 status is intentional (and the XML sitemap has not been updated)
The page is returning a 200 status code but Googlebot has not recrawled the page.
If an important page is unintentionally returning a non-200 status code it could because the page was 3xx redirected, returning a 4xx or a 5xx error. You can read more about how different HTTP status code impact Googlebot.
Finally, don’t panic if Google is returning a non-200 HTTP status code error for one of your important pages. Especially if you know the page (or pages) were changed recently.
Sometimes, Googlebot hasn’t crawled the page, or the reports take time to catch up with the changes made to your website.
Check with the Live URL test in the URL inspection tool in Google Search Console.
3) The page has indexable content
Finally, if your important pages do not have indexable content it is usually because:
Googlebot discovered a noindex tag on the page.
Googlebot analysed the content and believes it is a soft 404 error.
If an important page has a noindex tag (meta robots or X-robots) then Google will not render or index the page. You can learn more about the noindex tag on Google’s official documentation.
If an important page has a Soft 404 error then this means that Google believes the content should return a 404 error. This usually happens because Google is detecting similar minimal content across multiple pages that make it think the pages should be returning a 404 error.
The second type of not indexed pages relate to duplicate content issues.
What are these types of errors?
These types of errors are to do with Google canonicalization process in the indexing pipeline (I’ve provided descriptions as these are a bit more complicated):
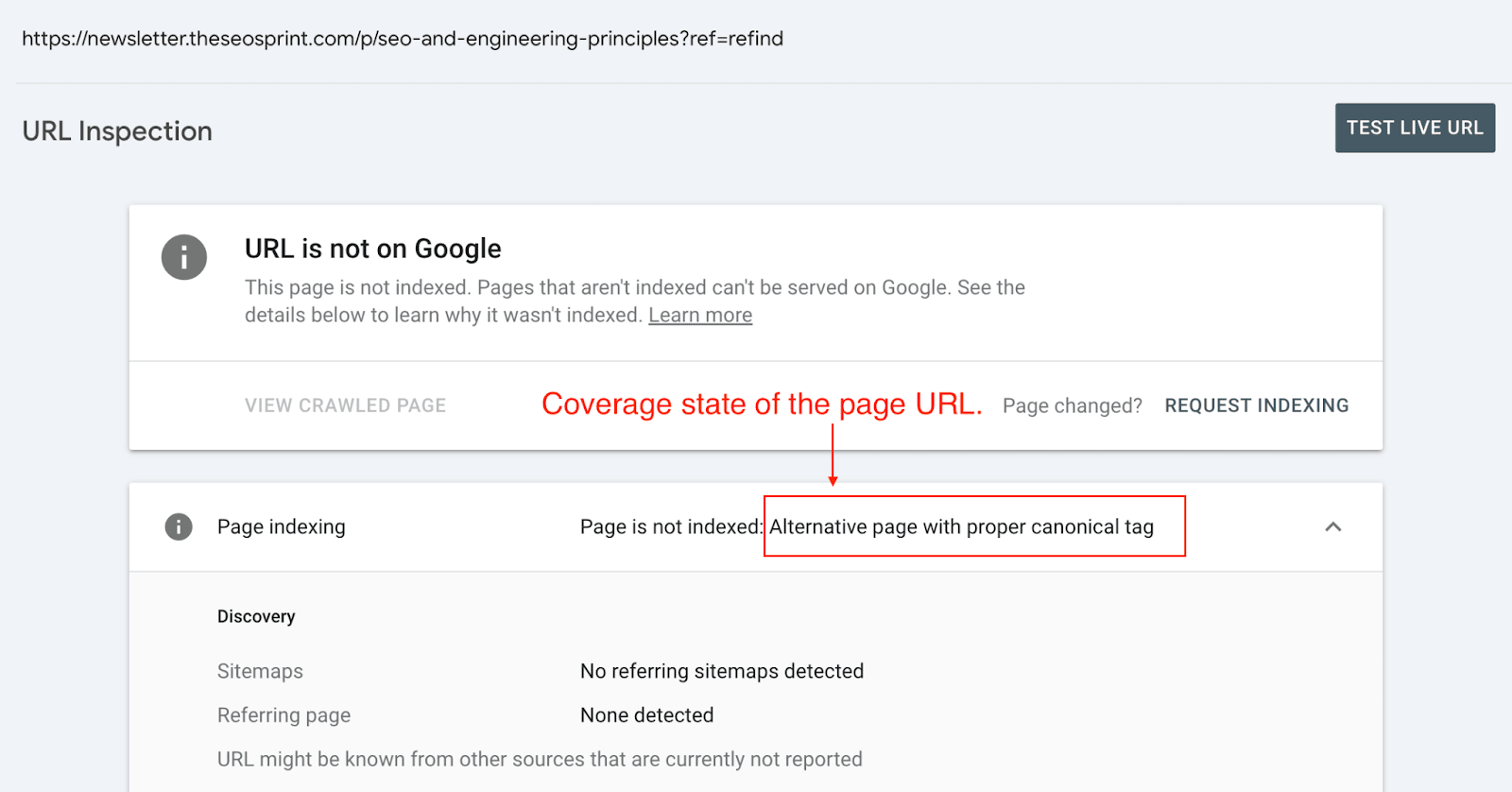
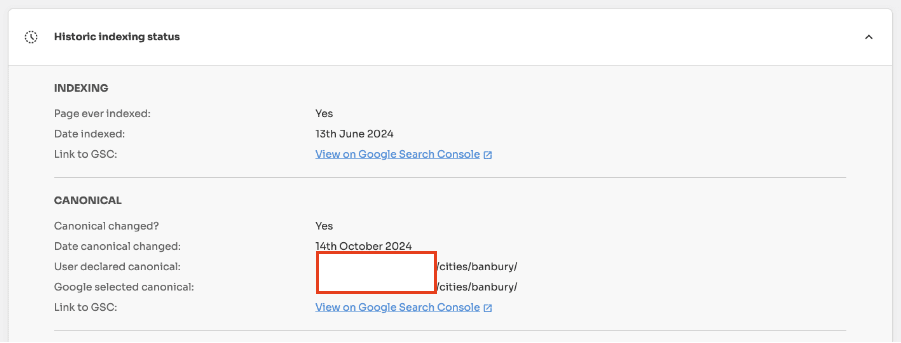
Alternate page with proper canonical tag - The page has indicated that another page is the canonical URL that will appear in search results.
Duplicate without user-selected canonical - Google has detected that this page is a duplicate of another page, that it does not have a user-selected canonical and that they have chosen another page as the canonical URL.
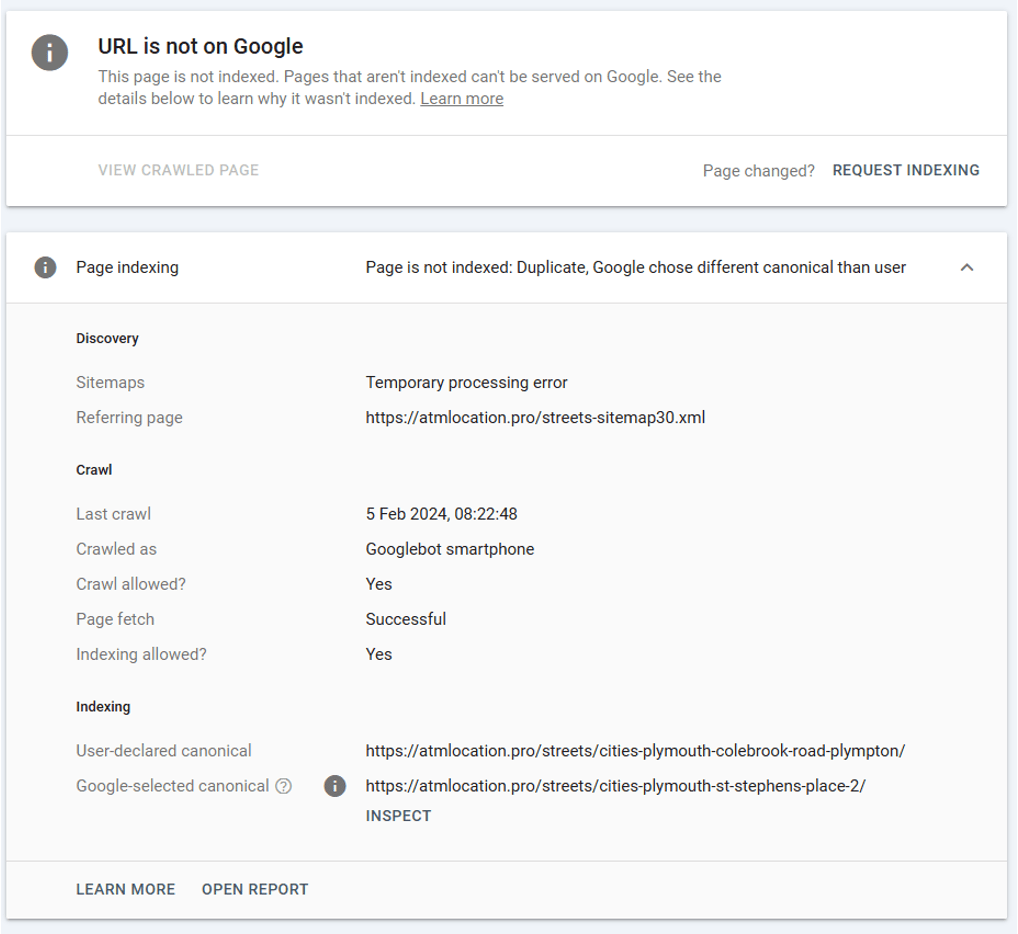
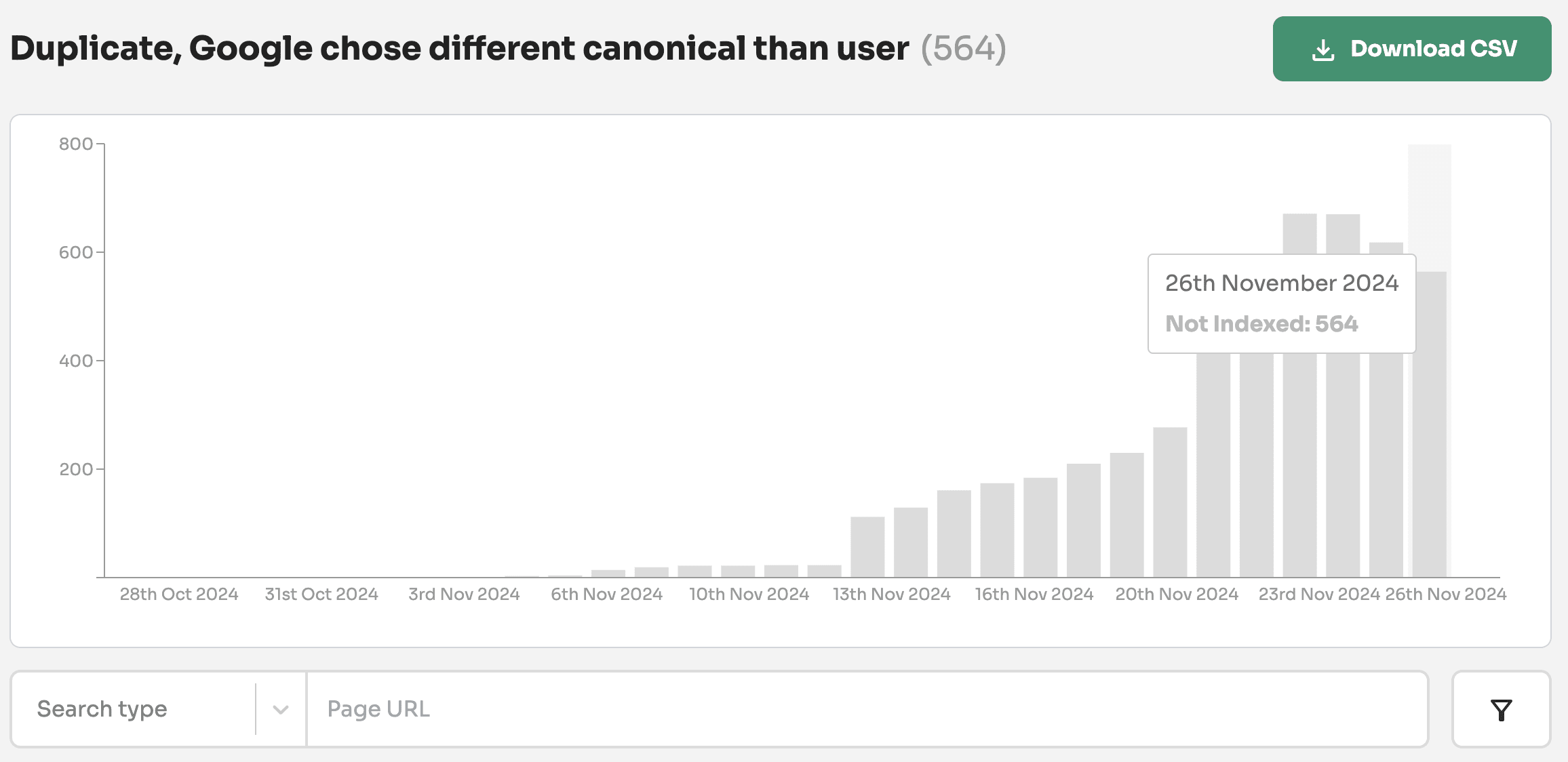
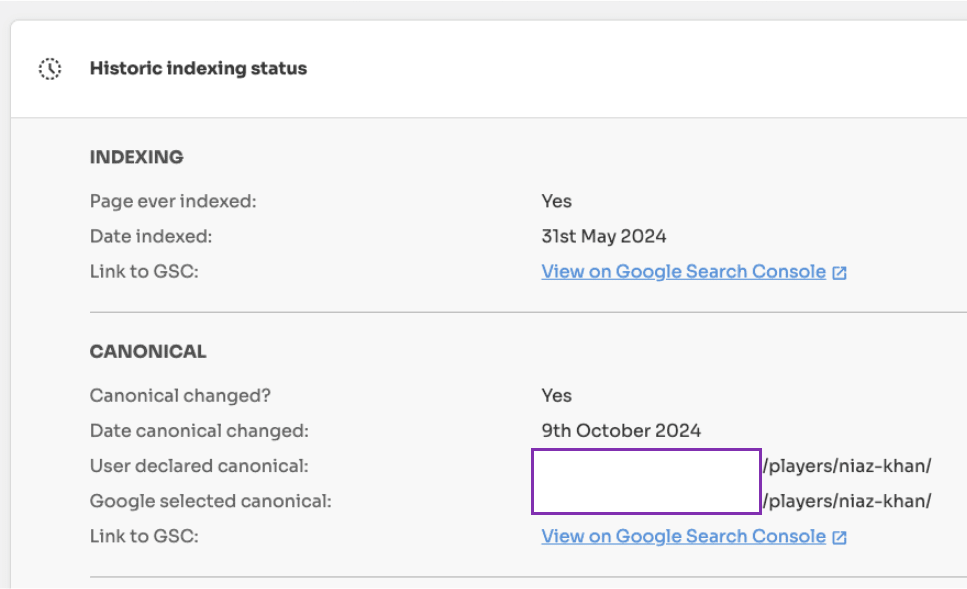
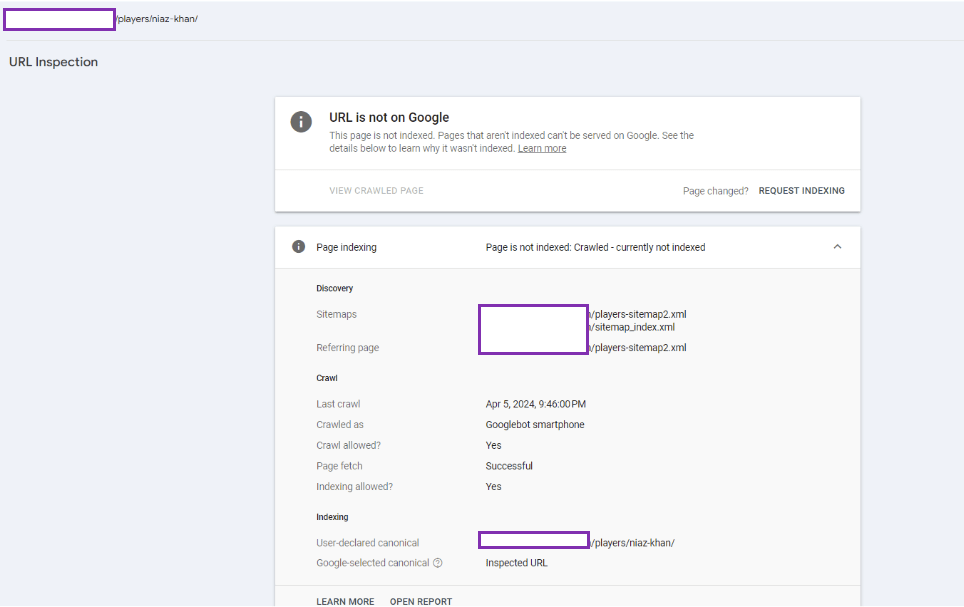
Duplicate, Google chose different canonical than user - Although you have specific another page as the canonical URL, Google has chosen a different page as the canonical URL to appear in search results.
Why are pages grouped into this category?
Pages are grouped into this category because of Google’s canonicalization algorithm.
When Google identifies duplicate pages across your website it:
Groups the pages into a cluster.
Analyses the canonical signals around the pages in the cluster.
Selects a canonical URL from the cluster to appear in the search results.
This process is called canonicalization. However, the process isn't static.
Google continuously evaluates the canonical signals to determine which URL should be the canonical URL for the cluster. It looks at:
3xx Redirects
Sitemap inclusion
Canonical tag signals
Internal linking patterns
URL structure preferences
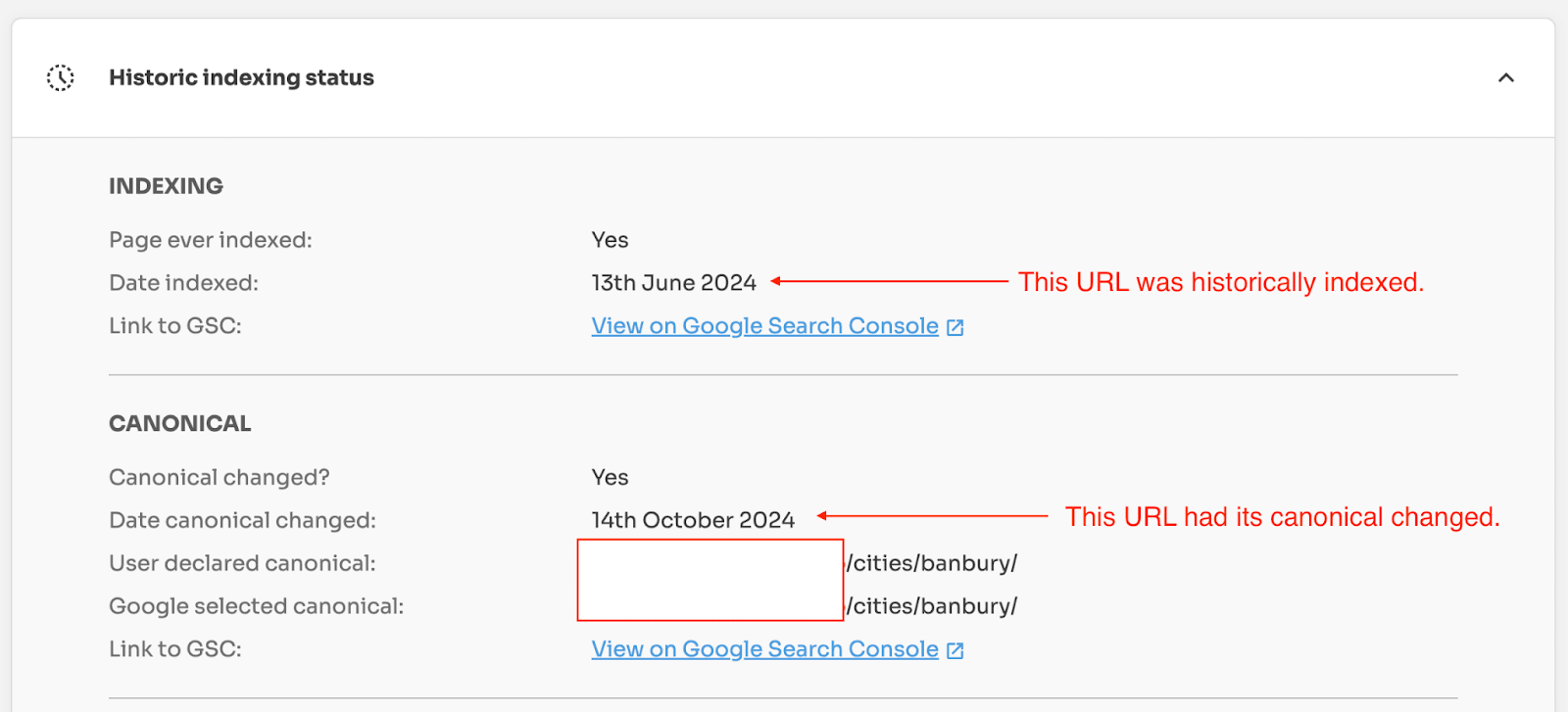
If a page was previously the canonical URL but new signals make Google select another URL in the cluster, then your original page gets removed from search results.
How can you fix these errors?
These types of Not Indexed pages are within your control to fix.
There are 3 reasons why your important pages are appearing in these categories:
Important pages don’t have a canonical tag.
Important page’s have been duplicated due to website architecture.
Important page’s canonical signals lack consistency across the website.
Duplicate without user-selected canonical
If an important page (or pages) does not have a canonical tag, then this can cause Google to choose a canonical URL based on weaker canonical signals.
Always make sure you specific the canonical URL by using canonical tags. For further information you can read how to specify a canonical link in Google’s documentation.
Duplicate, Google chose different canonical than user
If the signals around an important page aren’t consistent then this can cause Google to pick another URL as the canonical URL in a cluster.
Even if you use a canonical tag.
You need to ensure canonical signals are consistent across your website for the URLs you want to appear in search results. Otherwise, Google can, and will, choose the canonical URL for you. And it might not be the one you prefer.
The final type of not indexed page relates to quality issues, and these are the most challenging to address.
What are these types of errors?
These types of indexing errors are split into 3 groups based on the signals collects around pages over time:
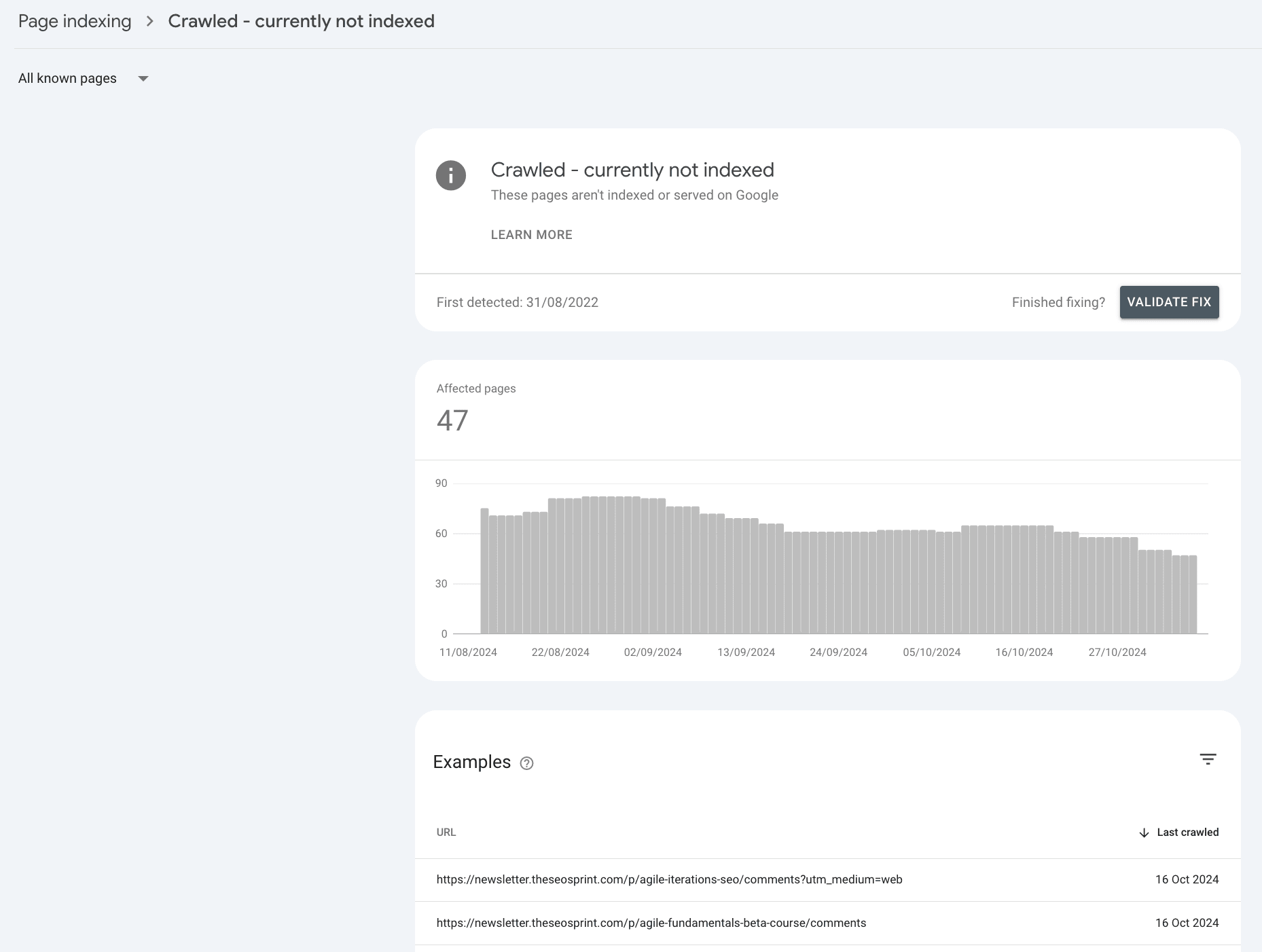
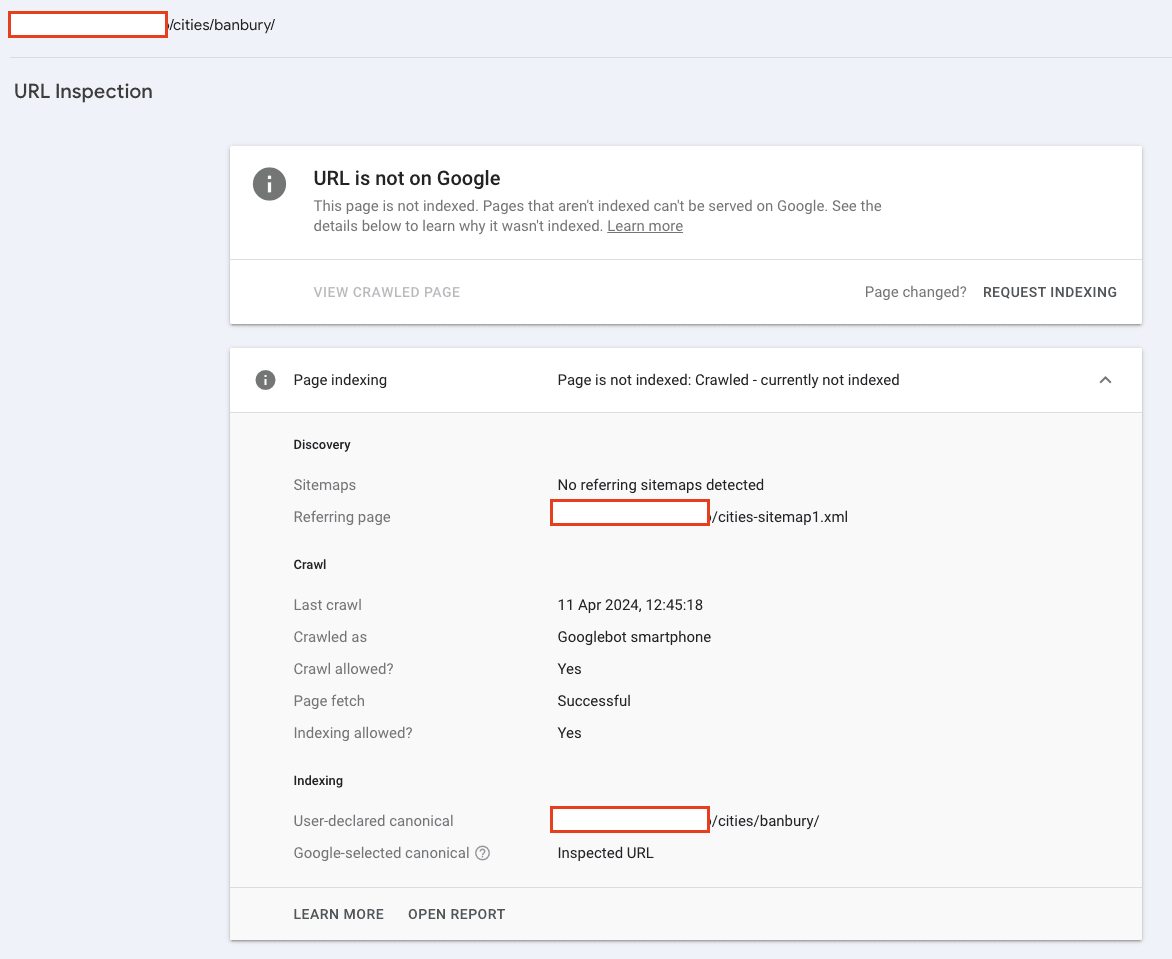
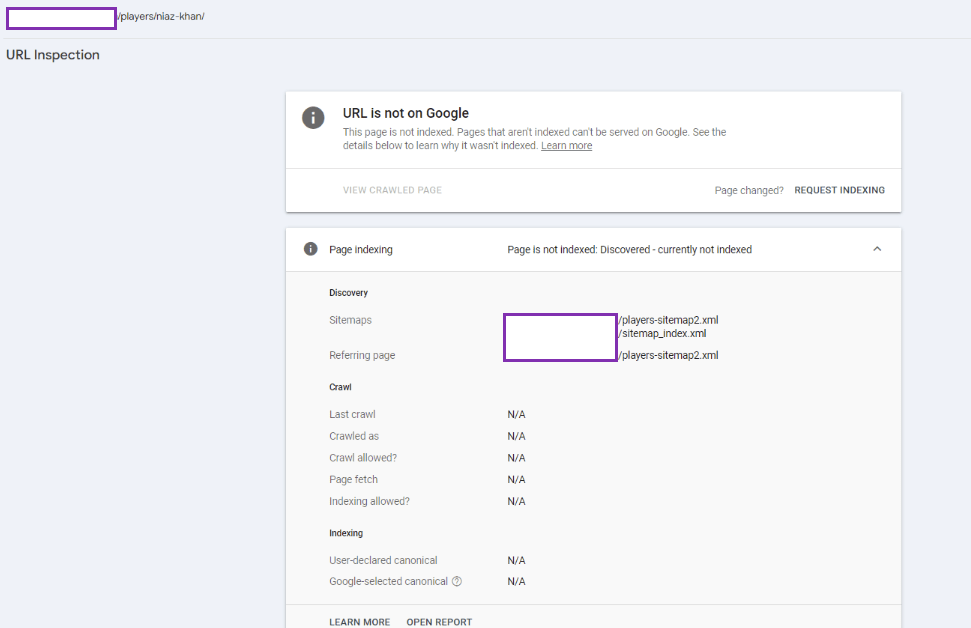
Crawled - currently not indexed: The page has either been discovered, crawled but not indexed OR the historically indexed page has been actively removed from Google’s search results.
Discovered—currently not indexed: A new page has been discovered but not yet crawled, OR Google is actively forgetting the historically indexed page.
URL is unknown to Google: A page has never been seen by Google OR Google has actively forgotten the historically crawled and indexed pages.
Why are pages grouped into this category?
Google is actively removing these pages from its search results and index.
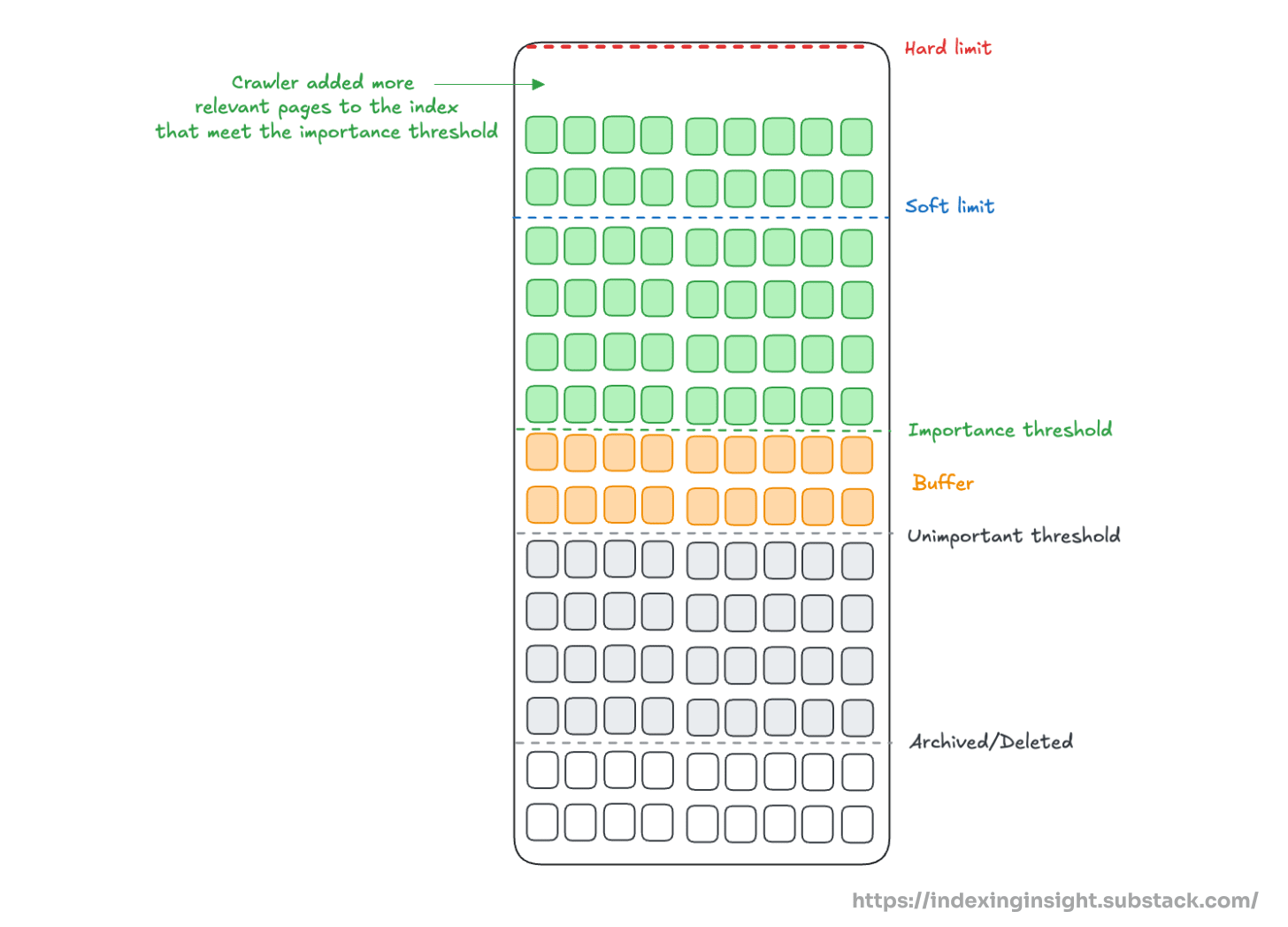
In another article, we discussed how Google might actively manage its index. The article discusses a patent that describes two systems: importance thresholds and soft limits.
The soft limit sets a target for the number of pages to be indexed. And the importance threshold directly influences which URLs get crawled and indexed.
Here's how it works according to the patent when the soft limit is reached:
Pages with an importance rank equal to or greater than the threshold are indexed.
As the threshold dynamically adjusts, URLs' crawl and indexing priority changes.
URLs with an importance rank far below the threshold have zero crawl priority.
It's all about their importance rank relative to the current threshold.
You need to group the two types of important pages within this category to avoid actioning unimportant pages:
✅ Indexable: Live important pages that are indexable but are not indexed.
❌ Not Indexable: Important pages that are not indexable (301, 404, noindex, etc.)
Why do we need to distinguish between these 2-page types in Google Search Console?
Our first-party data has shown that a small % of pages that are not indexable over time can be grouped into these categories.
For example, an ‘Excluded by nonindex tag’ can become ‘Crawled - currently not indexed’ after roughly 6 months. This isn’t a bug but by design.
When trying to figure out why pages are grouped into this category, it’s important to distinguish between what pages are Indexable and Not Indexable.
How can you fix indexable page errors?
Important indexable pages that are not indexed will be harder to fix.
Why?
If a page is live, indexable, and meant to be ranked in Google search and is underneath this category, then it means the website has bigger quality problems.
According to Google, they actively forget low-quality pages due to signals picked up over time.
There are 2 types of signals that can influence why Google might forget your important indexable pages:
📄 Page-level signals
🌐 Domain-level signals
📄 Page-level signals
The page-level signals can be grouped into three problems:
The indexable pages do not have unique indexable content.
The indexable pages are not linked to from other important pages.
The indexable pages weren’t ranking for queries or driving relevant clicks.
📄 Content: The text, metadata and assets used on the page.
🔗 Links: The quality of links and words used in anchor text pointing to a page.
🖱️ Clicks: The user interactions (clicks, swipes, queries) for a page in search results.
In the DOJ trial, Google provided a clear slide highlighting that content (vector embeddings), user interactions (click models) and anchors (PageRank/anchor text) play a key role across all their systems.
A BIG signal used in ranking AND indexing is user interaction data.
The DOJ documents describe how Google uses “user-side data” to determine which pages should be maintained in its index. Also, another DOJ trial document mentions that the user-side data, specifically the query data, determines a document's place in the index.
Query data for specific pages can indicate if a page is kept as “Indexed” or “Not Indexed”.
What does this mean?
This means that for important pages, you must include unique indexable content that matches user intent and build links to the page with verified anchor text. These pillars are essential to help you rank for a set of queries searched for by your customers.
However, user interaction with your page will likely decide whether it remains indexed over time.
When reviewing your important indexable pages that Google is actively removing, look at:
Indexing Eligibility: Check if Googlebot can crawl the page URL and render the content using the Live URL test in the URL inspection tool in Google Search Console.
Content quality: Check if the page or pages you want to rank match the quality and user intent of the target keywords (great article from Keyword Insights on this topic).
Internal links to the page: Check if the pages are linked to from other important pages on the website and you’re using varied anchor text (great article from Kevin Indig on this topic).
User experience: Check if your important pages actually provide a good user experience, load quickly, and answer the user’s question (great article from Seer Interactive on this topic).
🌐 Domain-level signals
However, page-level signals aren’t the only factor at play.
New research by SEO professionals has found that domain-level signals like brand impact a website’s ability to rank, which, as mentioned above, eventually impacts indexing.
The domain-level signals can be grouped into three areas:
The pages are part of a sitewide website quality issue.
The pages are on a website that is not driving any brand clicks.
The pages/website are not linked to other relevant, high-quality websites.
Mark Williams Cook and his team identified an API endpoint exploit that allowed them to manipulate Google’s network requests. This exploit allowed his team to extract metrics for classifying websites and queries in Google Search.
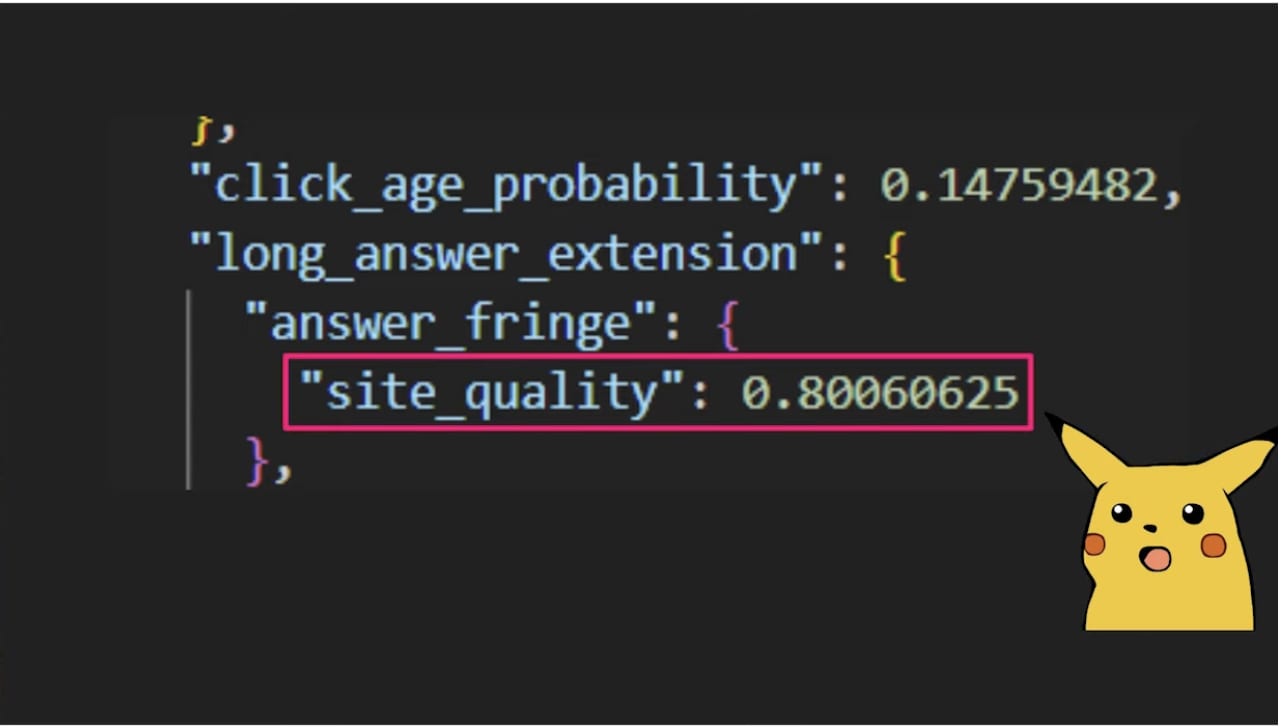
One of the most interesting metrics extracted was Site Quality score.
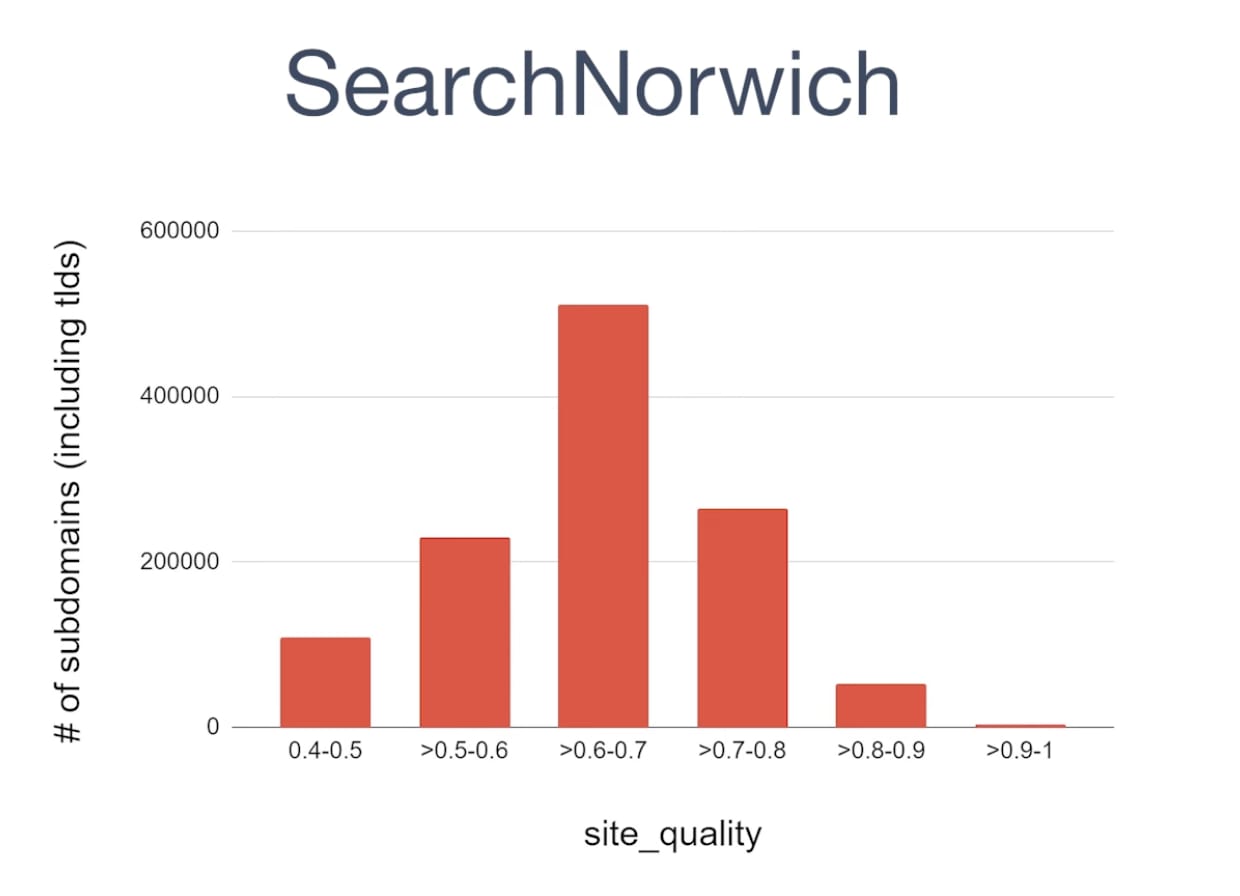
The Site Quality score is a metric that Google give each subdomain ranking in Google search and is scored from 0 - 1.
One of the most interesting points from Mark’s talk is that when analysing a specific rich result, his team noticed that Google only shows subdomains above a Site Quality score threshold.
For example, his team noticed that sites with a site quality score lower than 0.4 were NOT eligible to appear in rich results. No matter how much you “optimise” the content, you can’t appear in rich results without a site quality greater than 0.4.
What makes up the Site Quality score?
Mark pointed out a Google patent called Site Quality Score (US9031929B1) that outlines 3 metrics that can be used to calculate the Site Quality score.
The 3 metrics that influence Site Quality score:
Brand Volume - How often people search for your site alongside other terms.
Brand Clicks - How often people click on your site when it’s not the top result.
Brand Anchors - How often your brand or site name appears in anchor text across the web.
What if you’re a brand new website?
Mark pointed to a helpful Google patent called Predicting Site Quality (US9767157B2**),** which outlines 2 methods for predicting site quality scores for new website’s.
The 2 methods for predicting Site Quality score for new websites:
Phrase Models: Predicts site quality by analysing the phrases present within a website and comparing them to a model built from previously scored sites.
User Query Data: Using historic click models, predict the site quality score based on how users interact with the particular website.
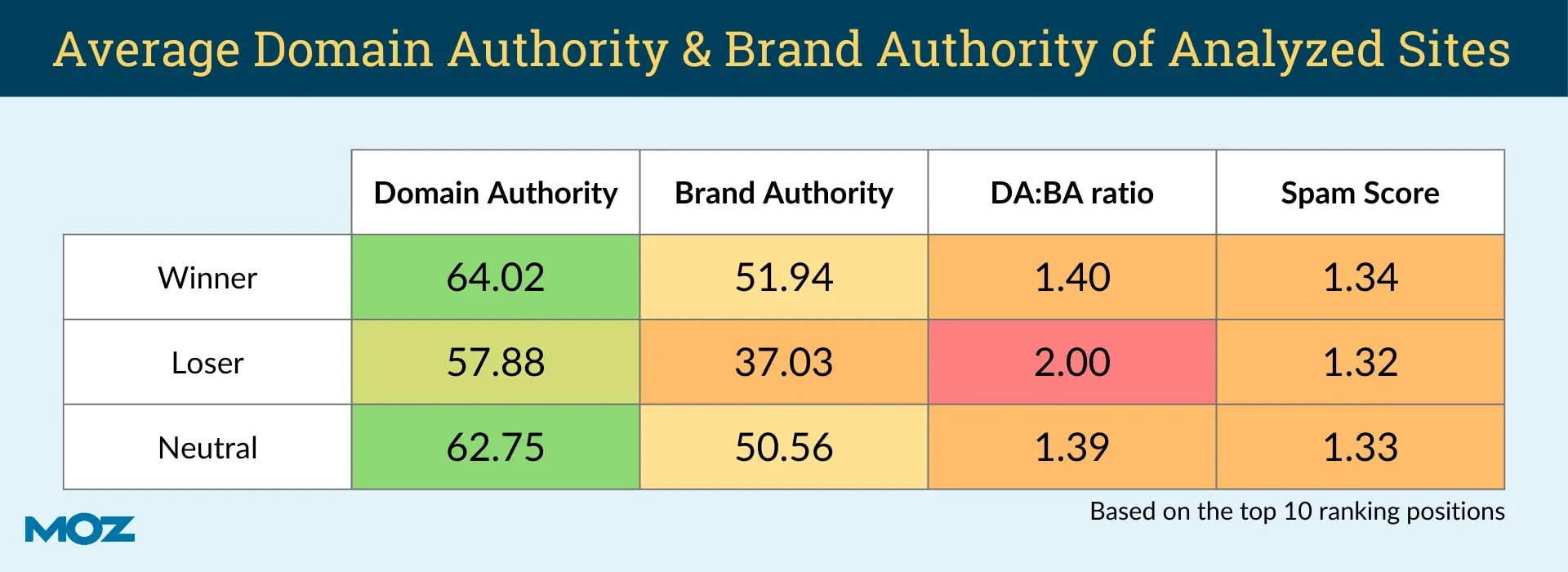
Is there any data or research that backs up the Site Quality Score?
This means that core updates impacted sites with a low brand authority more heavily.
Google doesn’t use the brand authority metric from Moz in its ranking algorithms. However, Tom’s study shows a connection between your domain's brand “authority” and a website’s ability to rank in Google Search.
Why does any of this site quality or brand authority matter to indexing?
Let me lay it all out for us to think it through:
Google uses indexable content, anchor text and links to rank pages for queries.
Over time, Google uses “user-side data” (click models/query data) to determine if a page remains in its index at a page level.
Google tracks the site quality score of your subdomain (website), and only sites above a certain threshold (=> 0.4) can appear in features like rich results.
Based on a Google patent, the site quality score is calculated using brand volume, clicks and interactions (as well as predicting scores for new websites).
Based on Moz’s research, The Google Help Content Update (HCU) impacts websites with low brand authority but high backlink authority.
If a website or pages are affected by Google updates (like the HCU), they will not rank for user queries and will have less “user-side data” over time.
The less “user-side data” over time, the greater the chance that Google’s search index will decide to remove the page from search results actively.
Domain-level signals like brand and backlinks help important indexable pages rank in search.
By ranking in search results, your important pages will get “user-side data” (clicks/queries), increasing the chance of your pages remaining in Google’s index.
Domain-level signals drive rankings, impacting whether important pages remain in the index.
If your page-level changes are not improving the indexing status of your important pages, you might need to work on building the website and brand's authority.
It’s why so many enterprise websites suffer from index bloat.
Google is happy to crawl and index lower-quality pages on websites with higher site quality scores (but that’s an issue for another newsletter).
It sucks but the reality is that Google prefers to rank brands over small websites.
📌 Summary
There are 3 main types of not indexed pages: technical barriers, duplicate content issues, and quality problems.
Technical barriers and duplicate content issues are generally within your control to fix through standard optimization practices.
Quality issues, however, require deeper analysis and often signal more significant problems with how your content meets user and search engine expectations.
Regularly monitoring your indexation status is crucial to identifying which category your not indexed pages fall into and taking appropriate action.
Google actively manages its index by removing low-quality pages.
In this newsletter, I'll explain insights from Google's patent "Managing URLs" (US7509315B1) on how Google might manage its search index.
I'll break down the concepts of importance thresholds, crawl priority, and the deletion process. And how you can use this information to spot quality issues on your website.
So, let's dive in.
⚠️ Before we dive in remember: Just because it’s in a Google patent doesn’t mean that Google engineers are using the exact systems mentioned in US7509315B1.
However, it does help build foundational knowledge on how Informational Retrival (IR) professionals think about managing a massive general search engine’s search index. ⚠️
📚 What is the Search Index?
Google’s search index is a series of massive databases that store information.
To quote Google’s official documentation:
“The Google Search index covers hundreds of billions of webpages and is well over 100,000,000 gigabytes in size. It’s like the index in the back of a book - with an entry for every word seen on every webpage we index.” -How Google Search organizes information
When you do a search in Google, the list of websites returned in Google’s search results comes from its search index.
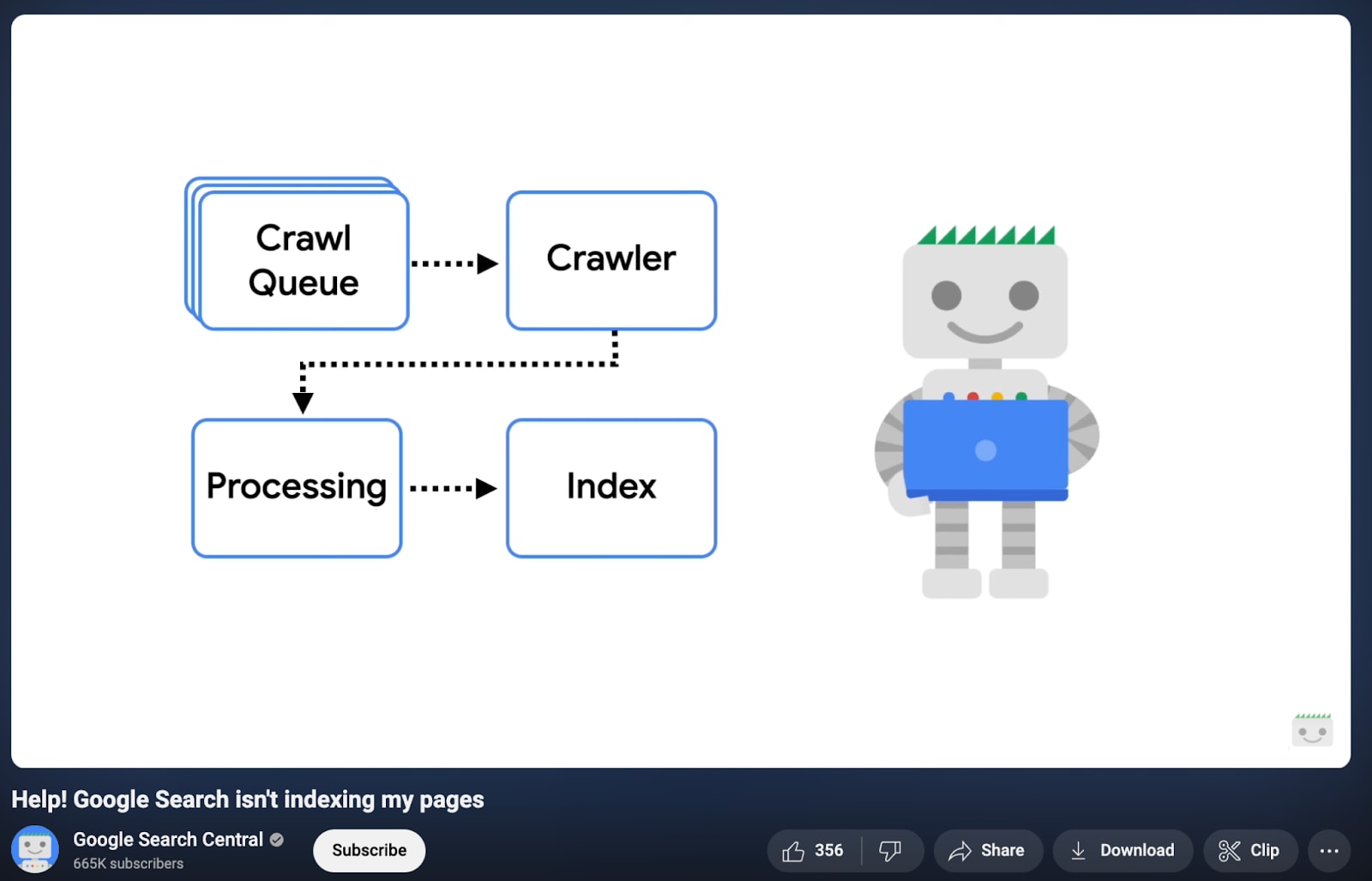
The process of building its search results is done in a 3-step process (source):
🕷️ Crawling: Google uses automated web crawlers to discover and download content.
💽 Indexing: Google analyses the content and stores it in a massive database.
🛎️ Serving: Google serves the stored content found in its search results.
If a website’s page is not indexed, it cannot be served in Google’s search results.
Any SEO professional or company can view the indexing state of their website’s pages in the Page Indexing report in Google Search Console.
🤖 Google Search Index Quality
Google actively removes pages from its search index.
This isn’t a new concept or idea. Lots of SEO professionals and Googler’s have flagged this over the last decade (but you have to really go looking). A few examples below.
Gary Illyes has mentioned in interviews that Google actively removes pages from its index:
“And in general, also the the general quality of the site, that can matter a lot of how many of these crawled but not indexed, you see in Search Console. If the number of these URLs is very high that could hint at a general quality issues. And I've seen that a lot uh since February, where suddenly we just decided that we are de-indexing a vast amount of URLs on a site just because the perception, or our perception of the site has changed.” - Google Search Confirms Deindexing Vast Amounts Of URLs In February 2024
Martin Splitt put out a video explaining Google actively removes pages from its index:
“The other far more common reason for pages staying in "Discovered-- currently not indexed" is quality, though. When Google Search notices a pattern of low-quality or thin content on pages, they might be removed from the index and might stay in Discovered.” -Help! Google Search isn’t indexing my pages
But how does Google decide which pages to remove from it’s index?
A Google patent called "Managing URLs" (US7509315B1) might hold the answer to how a search giant like Google manages its mammoth Search Index.
🔍 Search Index Limit
Any database (like a Search Index) has limits.
According to the Google patent "Managing URLs" (US7509315B1), any search index comes with limits for the number of pages that can be efficiently indexed.
There are two different limits to managing a search engine’s index effectively:
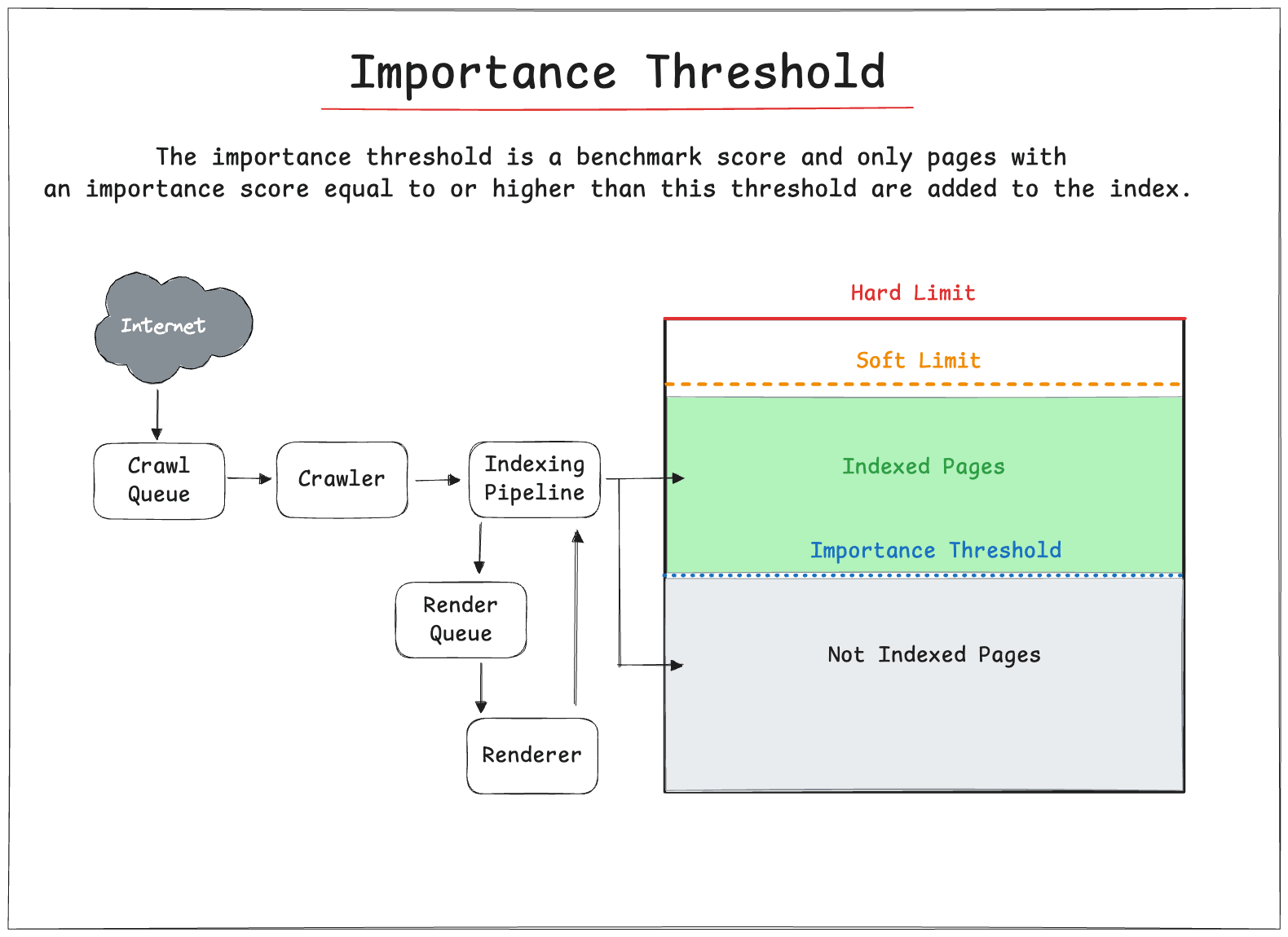
Soft Limit: This limit sets a target for the number of pages to be indexed.
Hard Limit: This limit acts as a ceiling to prevent the index from growing excessively large.
These two limits work together to ensure Google's index remains manageable while prioritizing high-ranking documents.
However, reaching this limit doesn't mean a search engine stops crawling entirely.
Instead, it continues to crawl new pages but only indexes those deemed "important" enough based on query-independent metrics (e.g. PageRank, according to the patent).
This leads us to an interesting concept: the importance threshold.
⚖️ The importance threshold
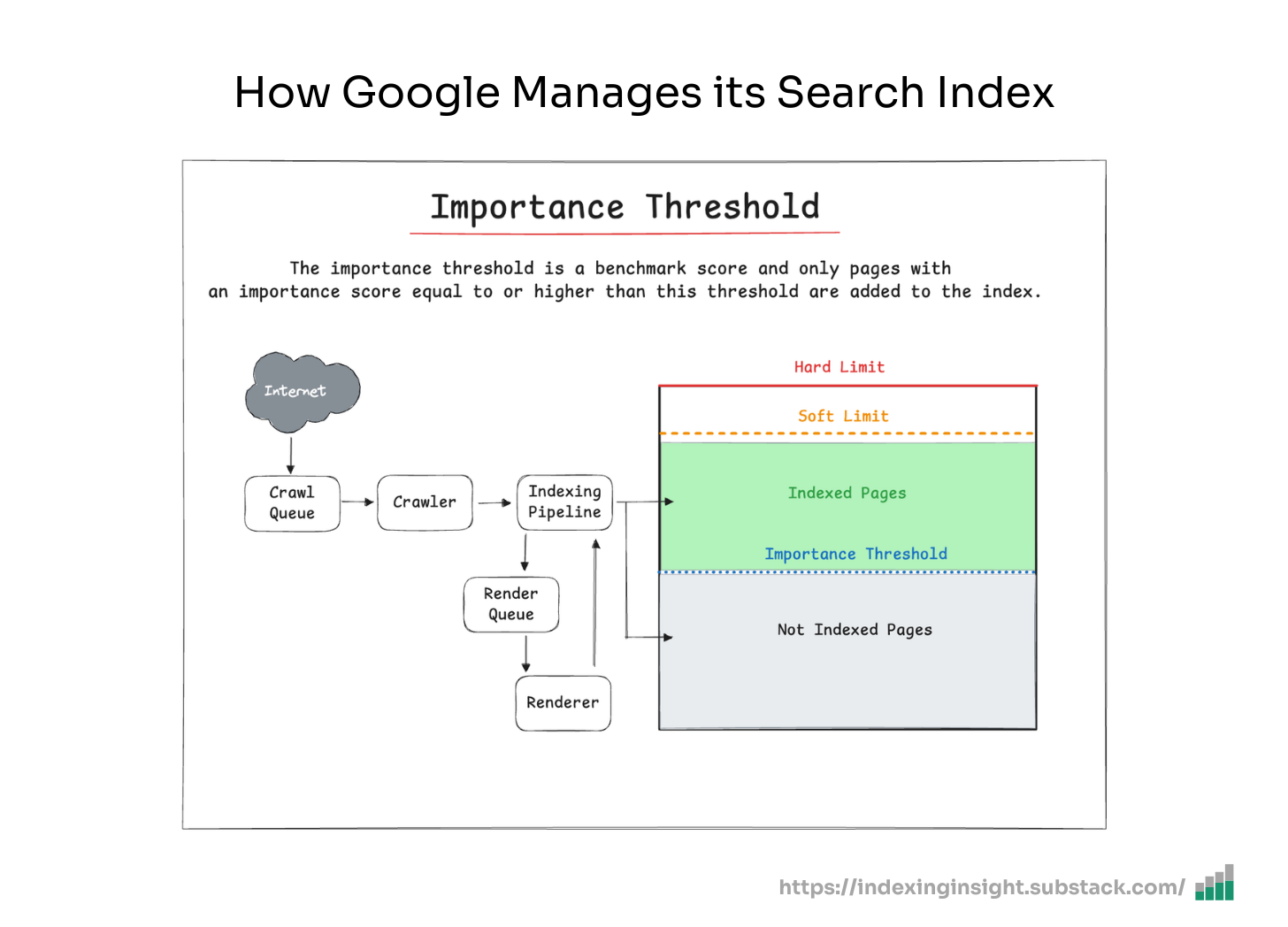
The importance threshold is a benchmark score mentioned in the Google patent.
It describes that a new page should be indexed after the initial limit has been reached. Only pages with an importance score equal to or higher than this threshold are added to the index.
This ensures that a search engine index prioritizes indexing the most important content.
Based on the patent, there are two main methods for determining the importance threshold:
🔢 Ranking Comparison Method
🏛️ Histogram-Based Method
🔢 Ranking Comparison Method
All known pages are ranked according to their importance.
The threshold is implicitly defined by the importance rank of the lowest-ranking page currently in the index.
For example, if a search engine had 1,000,000 pages indexed. It would rank (sort) the pages based on each calculated importance score. The lowest importance rank the list would be 3.
So the importance threshold in the Search Index would be 3.
🏛️ Histogram-Based Method
The system would use a histogram representing the distribution of importance ranks.
The threshold is calculated by analyzing the histogram and identifying the importance rank corresponding to the desired index size limit.
For example, if a search engine had a limit of 1,000,000 pages. If the histogram shows that 800,000 pages have an importance rank of 6 or higher, the importance threshold would be 6.
📊 Importance threshold fluctuates
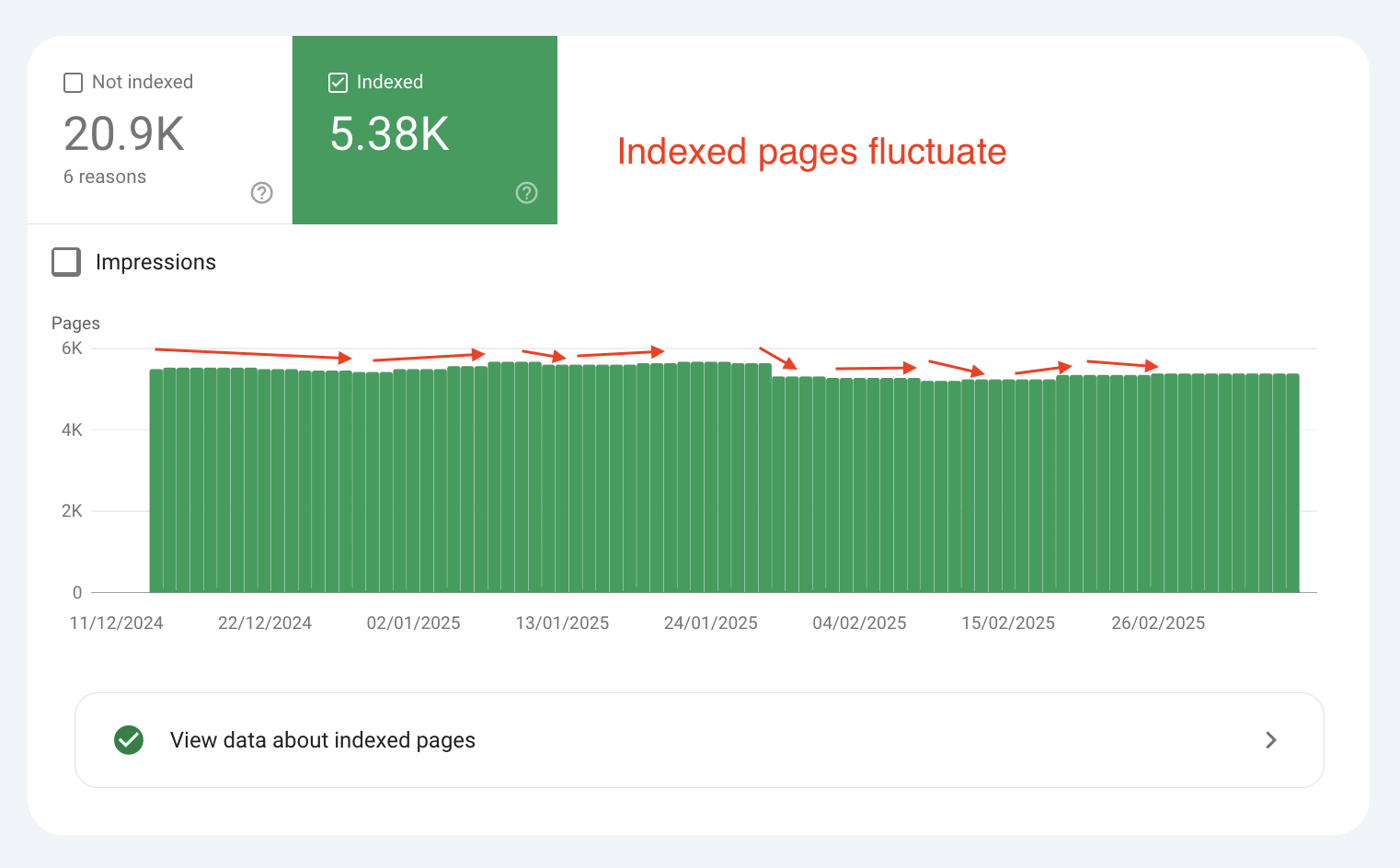
The number of indexed pages can fluctuate due to the importance threshold.
This is due to the dynamic nature of both the importance threshold and the importance rankings of individual pages.
You can see this sort of process in action in the Page Indexing report in GSC.
According to the patent, three main factors cause these fluctuations:
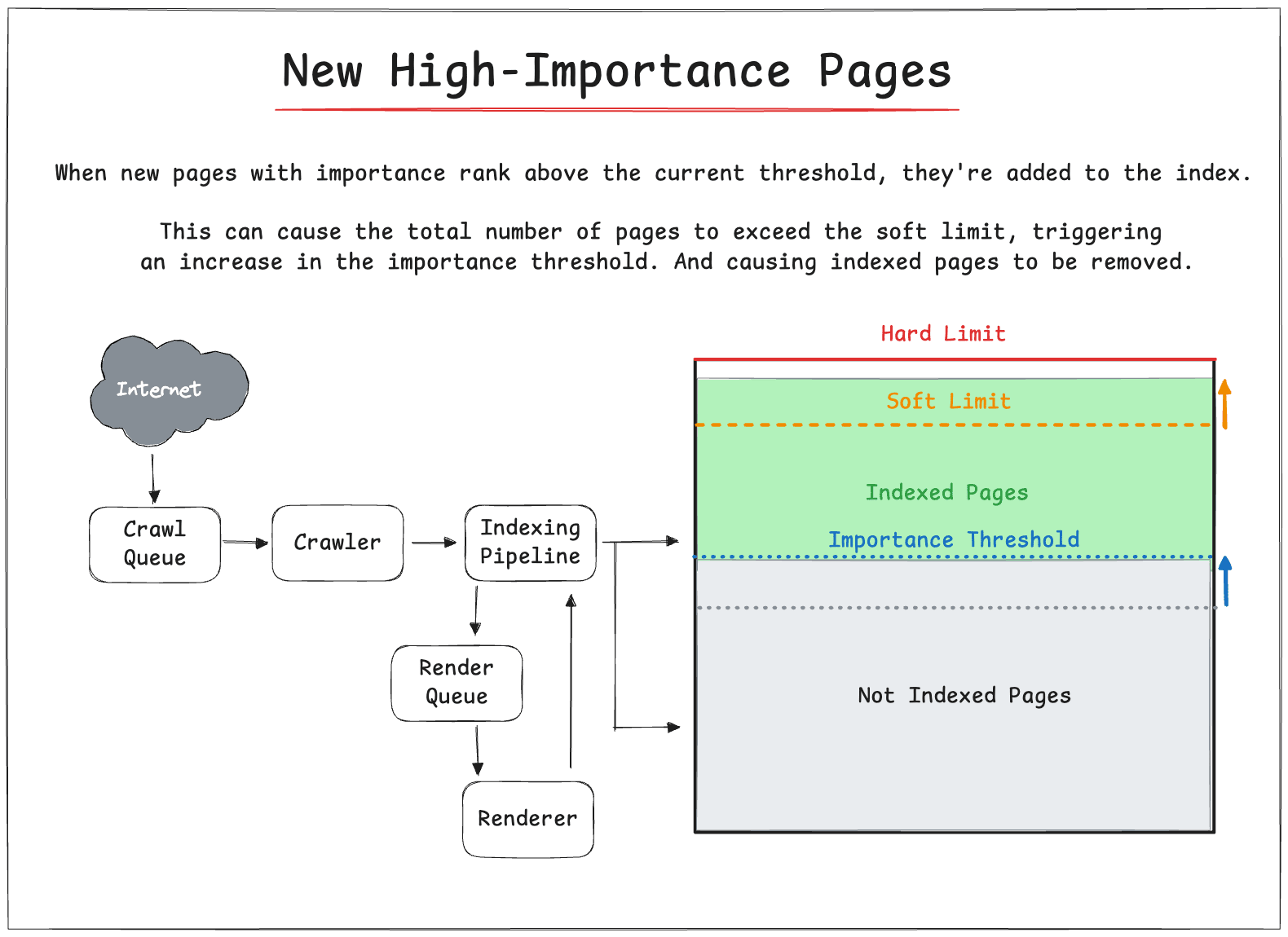
🆕 New High-Importance Pages
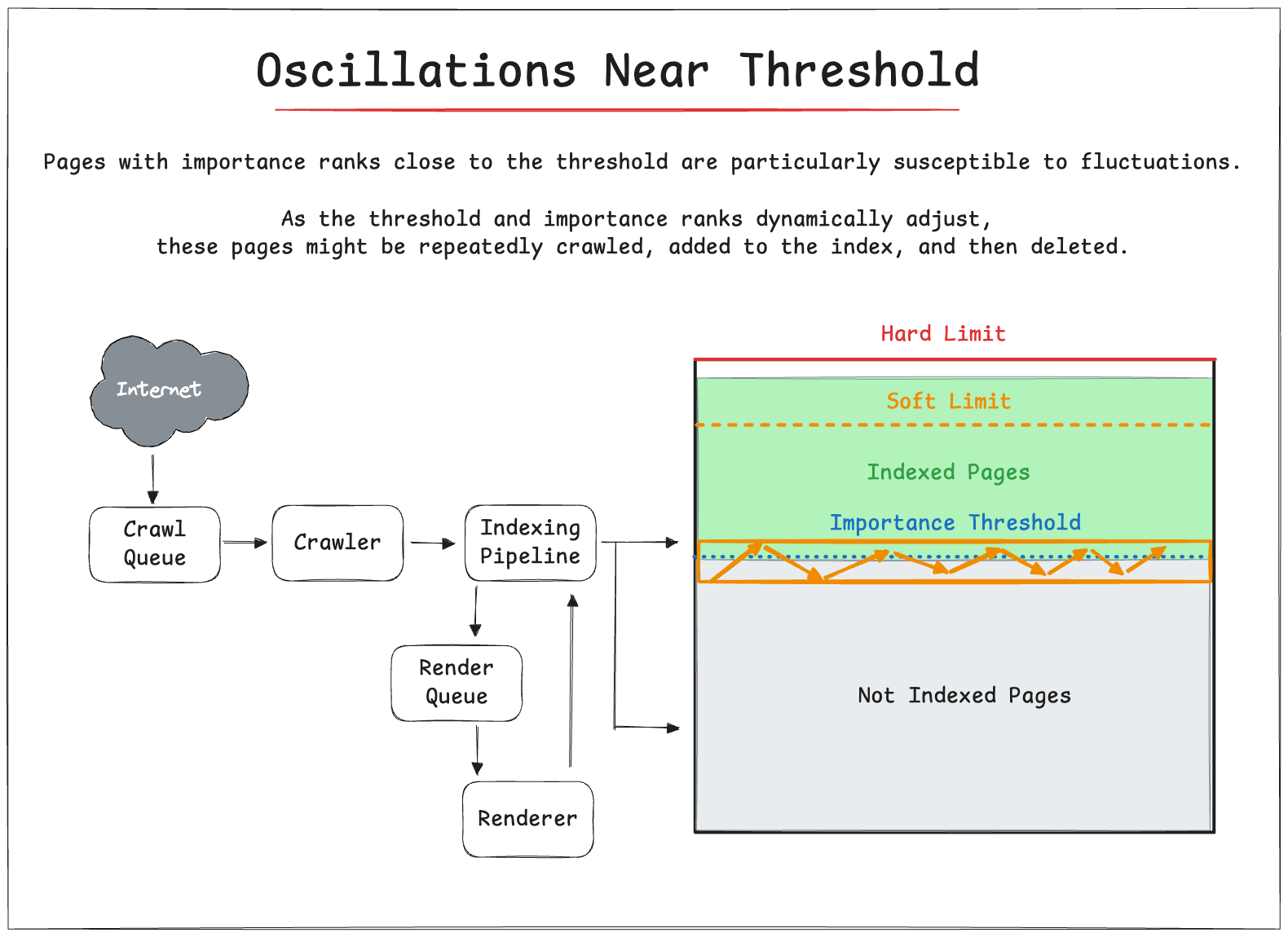
🚨 Oscillations Near Threshold
📊 Importance Rank Changes
🆕 New High-Importance Pages
When new pages with importance rank above the current threshold, they're added to the index.
This can cause the total number of pages to exceed the soft limit, triggering an increase in the importance threshold and potentially removing existing pages with lower importance.
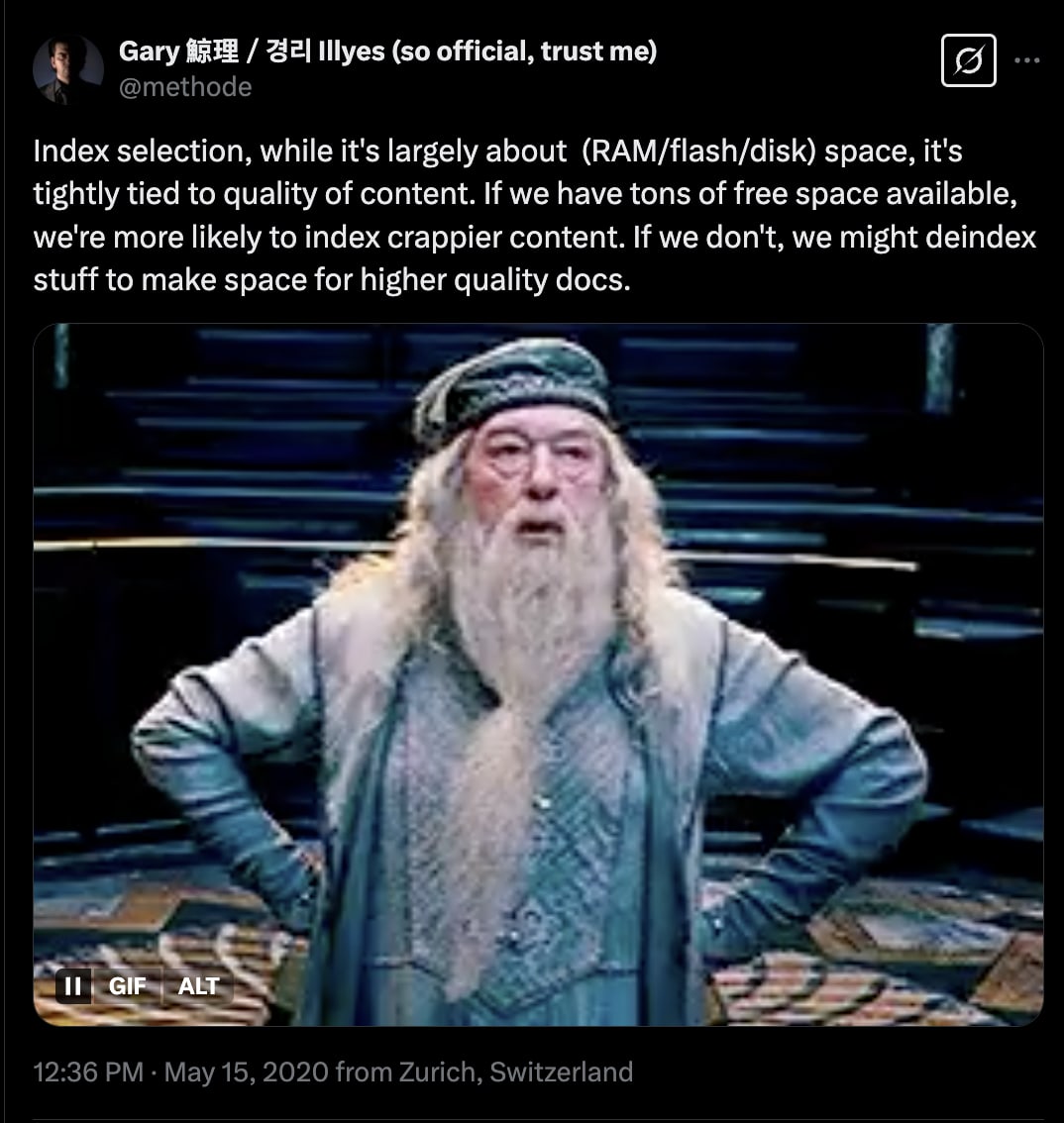
Gary Illyes actually confirmed that this process happens in Google’s Search Index.
Poor quality content (lower importance rank) will be actively removed if higher quality content is needs to be added to the index.
🚨 Importance Rank Changes
Existing pages are removed from the index because they drop below the unimportance threshold.
If an existing page's importance rank drops below the unimportance threshold (due to content updates, link structure changes, or poor user engagement from session logs), it might be deleted from the index, even if it was previously above the importance threshold.
Indexing Insight first-party data has seen indexed pages become not indexed pages in our ‘Crawled - previously indexed’ report.
Gary Illyes confirmed that Google Search’s index tracks signals over time and that these can be used to decide to remove pages from its search results:
“And in general, also the the general quality of the site, that can matter a lot of how many of these crawled but not indexed, you see in Search Console. If the number of these URLs is very high that could hint at a general quality issues. And I've seen that a lot uh since February, where suddenly we just decided that we are de-indexing a vast amount of URLs on a sitejust because the perception, or our perception of the site has changed.”
Pages with importance ranks close to the threshold are particularly susceptible to fluctuations.
As the threshold and importance ranks dynamically adjust, these pages might be repeatedly crawled, added to the index, and then deleted.
This creates oscillations in the index size.
The patent describes using a buffer zone to mitigate these oscillations, setting the unimportance threshold slightly lower than the importance threshold for crawling.
This reduces the likelihood of repeatedly crawling and deleting pages near the threshold.
Gary Illyes again confirms that a similar system happens in Google’s Search Index, indicating that pages very close to the quality threshold can fall out of the index.
But it can then be crawled and indexed again (and then fall back out of the index).
Indexing states: Why do they change?
The patent also explains why your page’s indexing states can change over time.
At Indexing Insight, we have noticed using our first-party data that indexing state in GSC can indicate the crawl priority of a website.
The Google patent (US7509315B1) explains why this happens using two systems:
🔄 Soft vs Hard Limits
🚦 Importance threshold and crawl priority
🔄 Soft vs Hard Limits
There are two different limits to managing a search engine’s index effectively:
Soft Limit: This limit sets a target for the number of pages to be indexed.
Hard Limit: This limit acts as a ceiling to prevent the index from growing excessively large.
These two limits work together to ensure Google's index remains manageable while prioritizing high-ranking documents.
For example, if Google’s Search Index has a soft limit of 1,000,000 URLs, and the system detects they have hit that target, then Google will start to increase the importance threshold.
The result of increasing the importance threshold removes indexed pages that are below the importance threshold.
Which impacts the crawling and indexing of new pages.
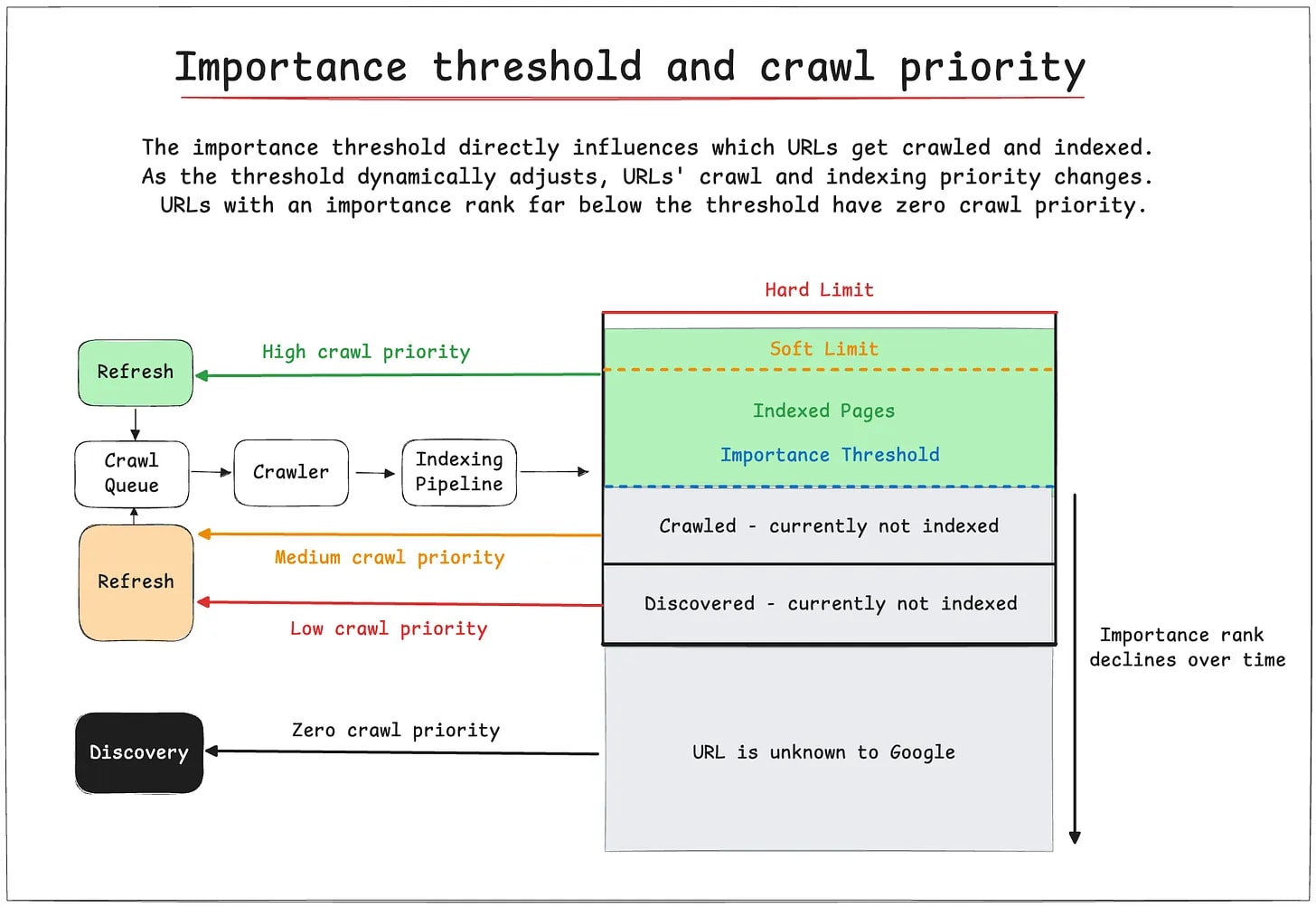
🚦 Importance threshold and crawl priority
The importance threshold directly influences which URLs get crawled and indexed.
Here's how it works according to the patent when the soft limit is reached:
Only pages with an importance rank equal to or greater than the current threshold are crawled and indexed.
As the threshold dynamically adjusts, URLs' crawl and indexing priority changes.
URLs with an importance rank far below the threshold have zero crawl priority.
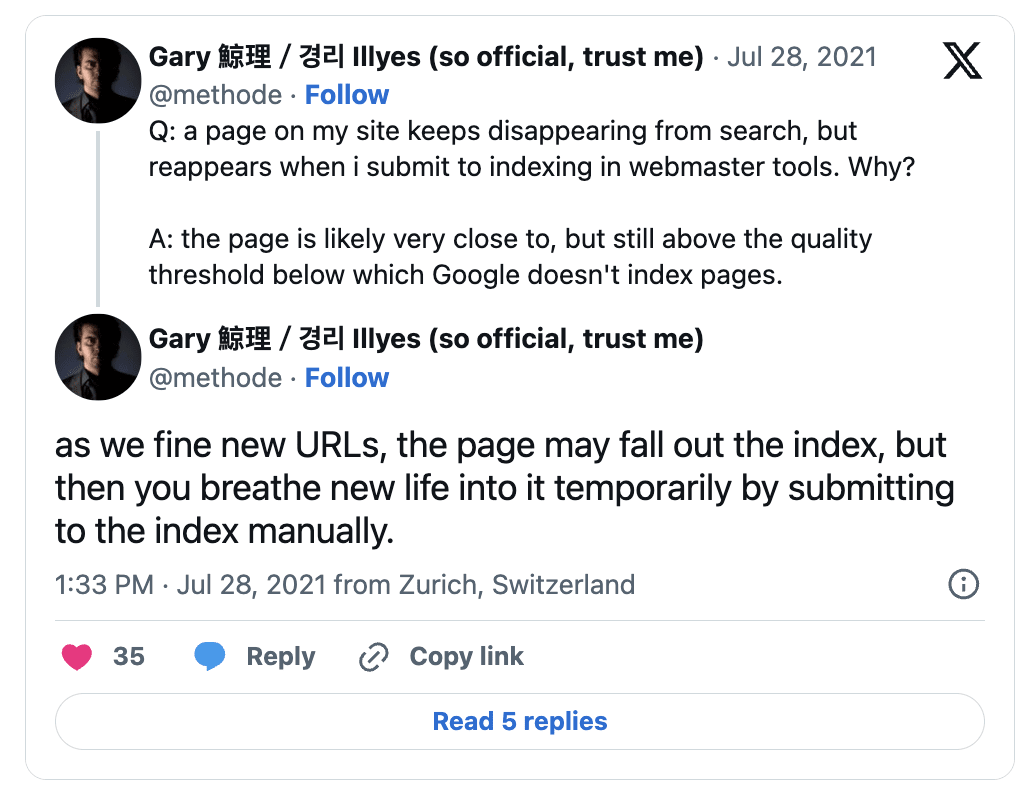
This system explains why some pages move from the "Crawled—currently not indexed" to the "URL is Unknown to Google" indexing states in Google Search Console.
It's all about their importance rank relative to the current threshold.
The decline in importance rank score over time means that a URL can go from:
⚠️ “Crawled—currently not indexed"
🚧 “Discovered —currently not indexed"
❌ "URL is Unknown to Google"
Gary Illyes from Google confirmed that Google’s Search Index does “forget” URLs over time based on the signals. And that these URLs have zero crawl priority.
🤓 What does this mean for you (as an SEO)?
Understanding Google's index management can directly impact your SEO success.
Here are 4 tips to action the information in this article:
🚑 Monitor your indexing states
🏆 Focus on quality over quantity
🧐 Identify content that's at risk
🔄 Regularly audit and improve existing content
🚑 Monitor your indexing states
Check your indexing states on a weekly or monthly basis, especially after core updates.
Pay attention to the following trends:
Increase in pages in the 'Crawled - currently not indexed' report
Increases in pages in the 'Discovered - currently not indexed' report
Pages that are being flagged as 'URL is unknown to Google' in GSC
These shifts can indicate that Google is actively deprioritizing or removing your content from the index based on importance thresholds.
🙋♂️ Note to readers
Google Search Console makes monitoring indexing states difficult.
The importance threshold mechanism shows that Google constantly evaluates page quality relative to the entire web.
This means:
Higher-quality pages push out lower-quality pages from the index
Importance score of your pages continues to worsen if you don’t improve them
Your content isn't just competing against your previous versions but against all new content being created.
This explains why a page that was indexed for years can suddenly get deindexed. Its importance rank may have remained static while the threshold increased.
🧐 Identify content that's at risk
URLs with frequent indexing state changes (oscillating between indexed and not indexed) are likely near the importance threshold.
These pages should be prioritized to be improved.
For example, if you notice a page was previously indexed but now shows as 'Crawled - currently not indexed', it's likely hovering near the importance threshold.
🔄 Regularly audit and improve existing content
The patent suggests that Google continually reassesses page importance.
To maintain and improve your indexing, it’s important to:
Perform regular content audits focusing on thin content
Update and improve existing content rather than just creating new pages
Monitor internal links and user engagement metrics as they influence importance.
📌 Summary
Google actively removes pages from its index.
In this newsletter, I explained how Google MIGHT use a set of processes to help manage its Search Index using the Google patent (US7509315B1).
The patent sheds some light on how your pages can be actively removed.
The concepts in the patent help explain indexing behaviour they are witnessed by SEO professionals when they use Google Search Console.
Hopefully, this newsletter has given you a deeper understanding of how Google works and what you should be doing to help get your pages indexed.
After tracking millions of URLs with Indexing Insight, we've uncovered significant gaps in what Google Search Console tells you about your page’s indexing status.
In this newsletter, I'll reveal the top 5 things most SEOs don't know about the Page Indexing report and how these hidden insights could be affecting your SEO analysis.
So, let's dive in.
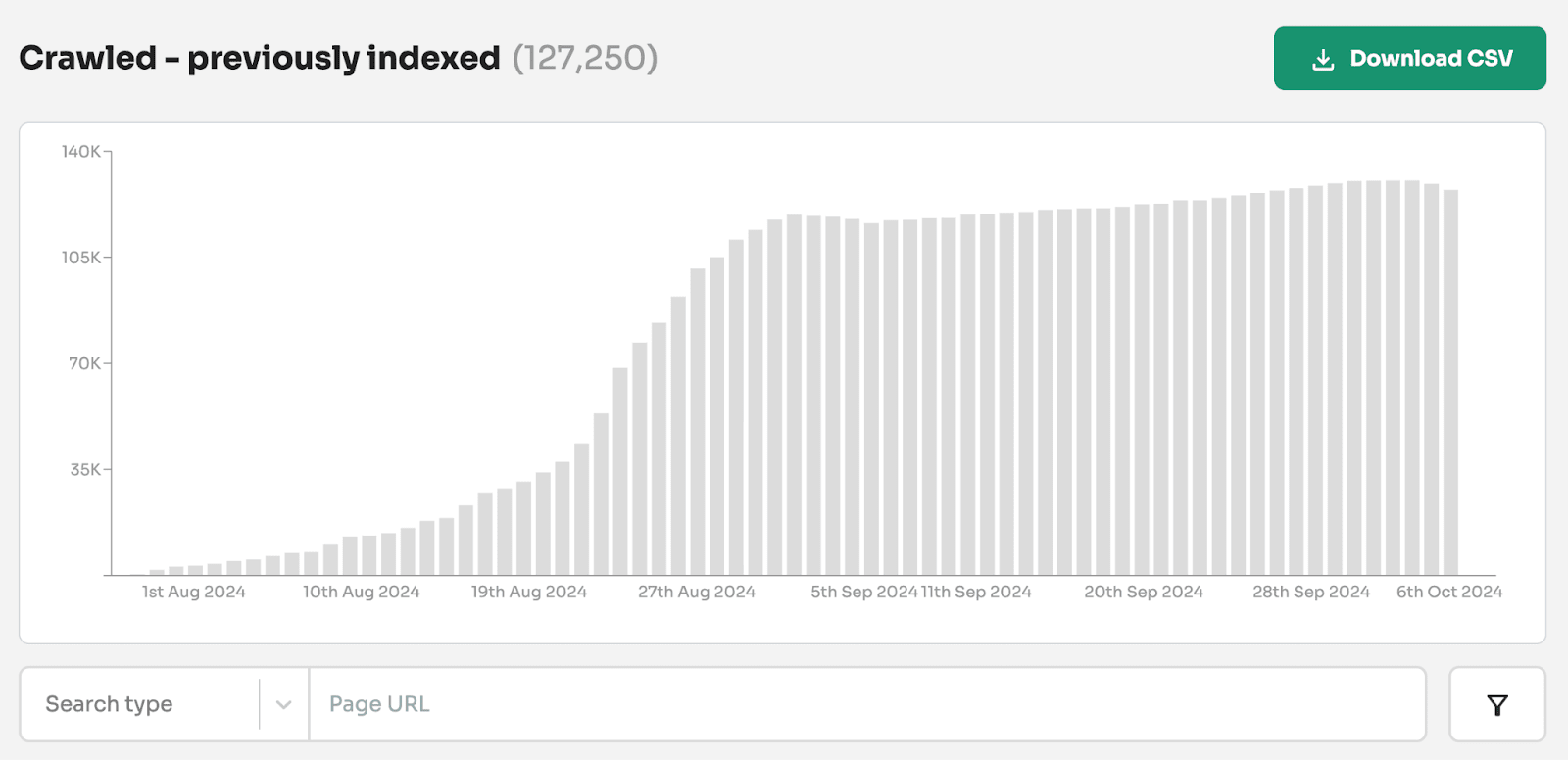
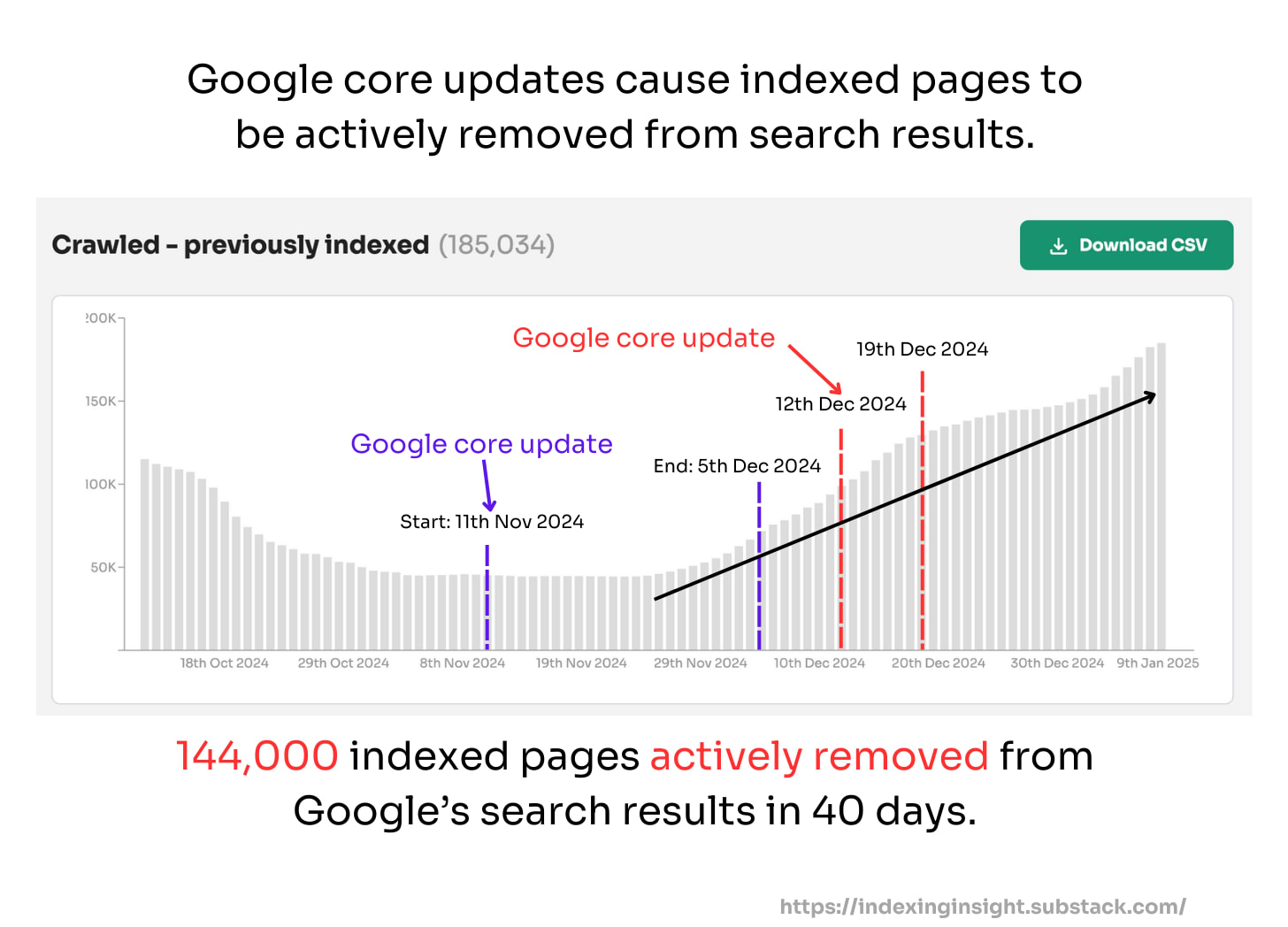
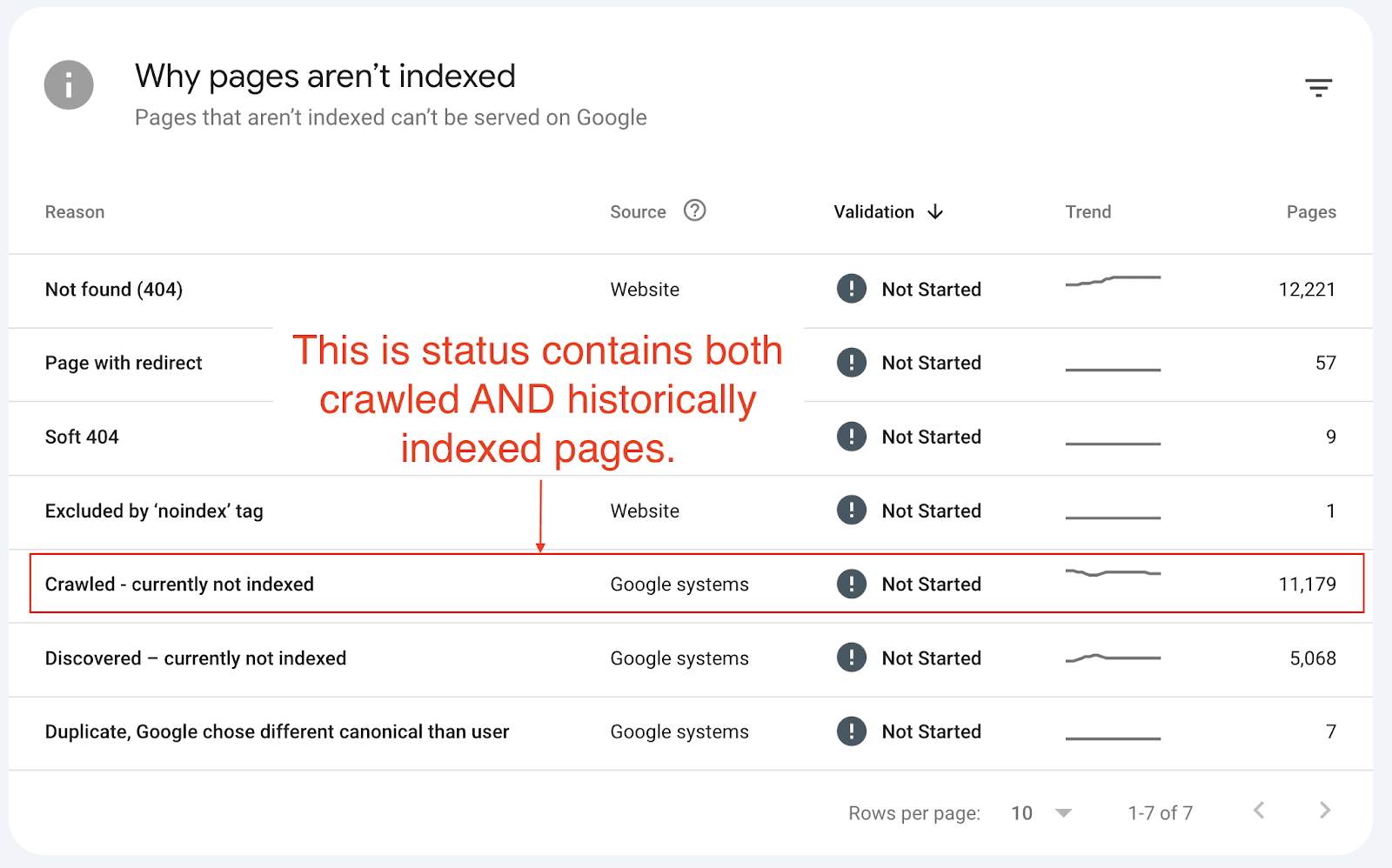
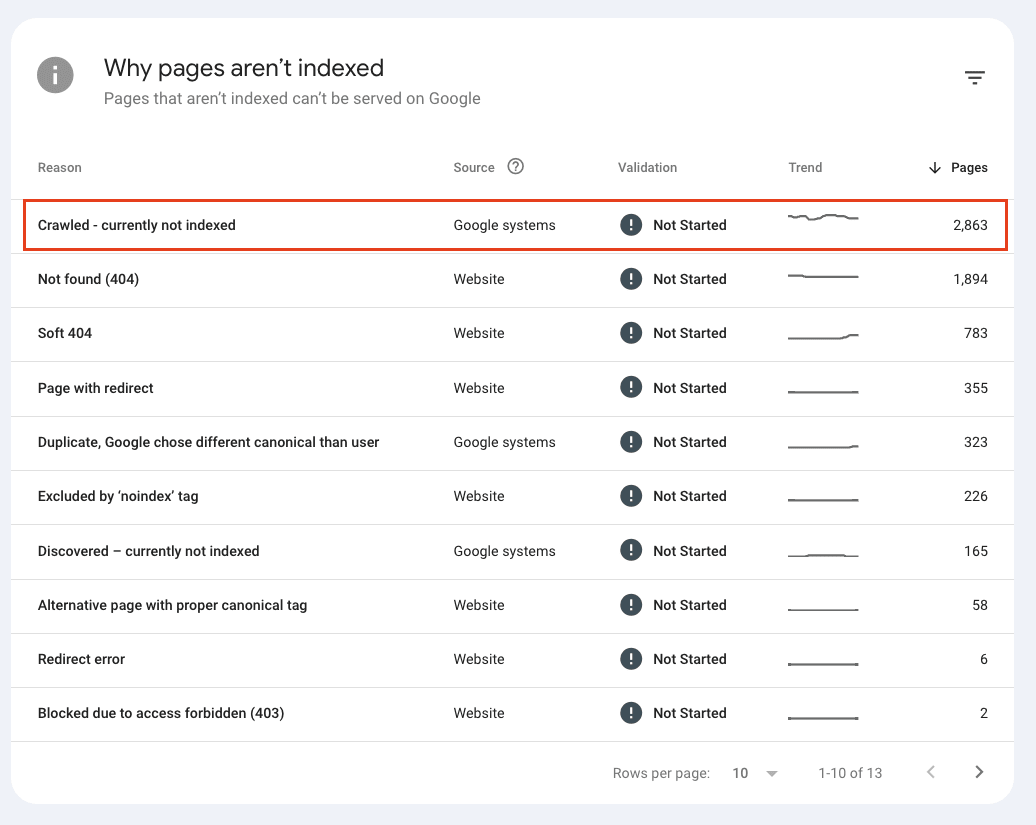
🕷️ 1. 'Crawled - currently not indexed' often means 'previously indexed'
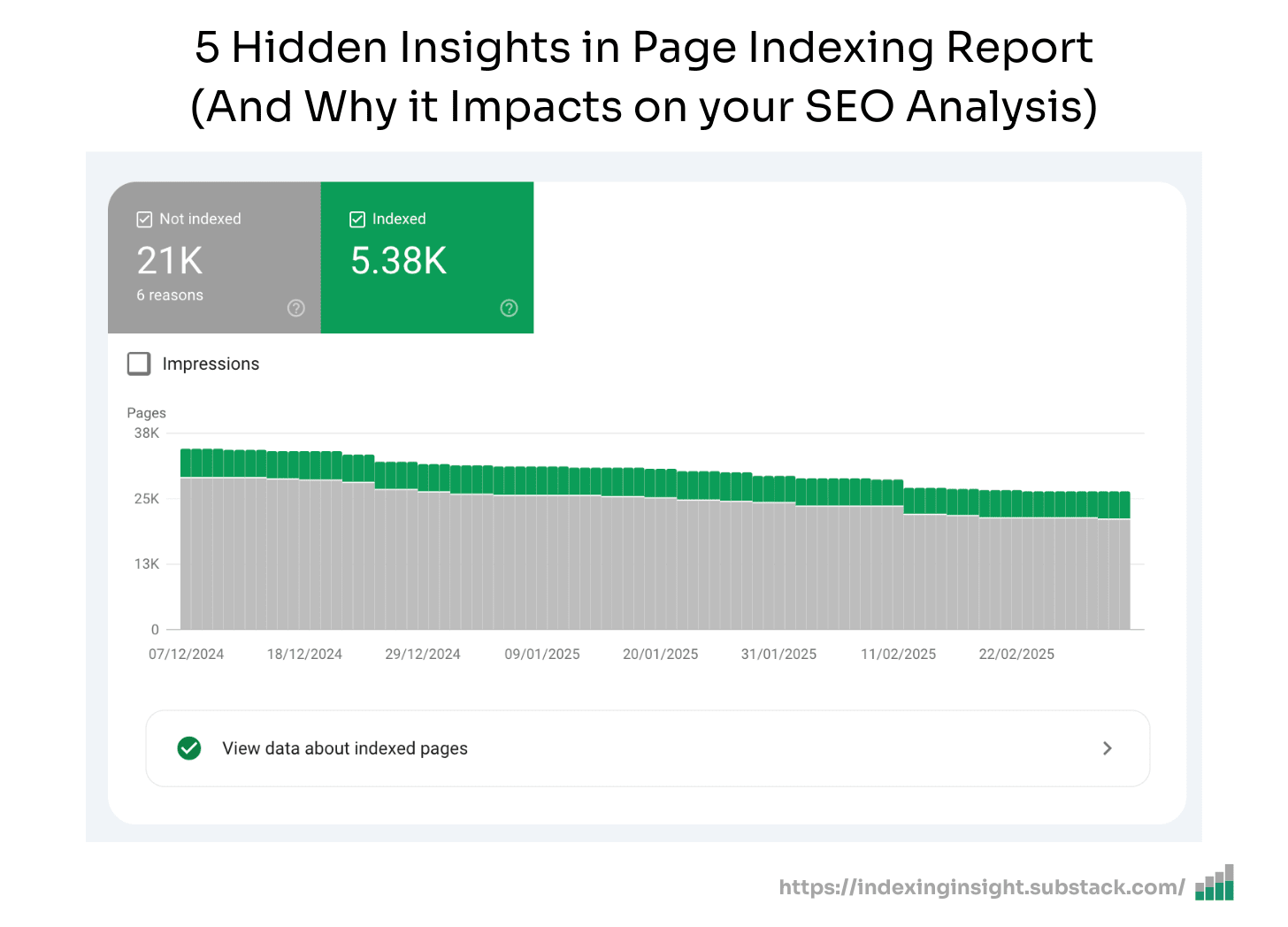
The current definition of 'crawled - currently not indexed' is misleading.
If you search for 'crawled - currently not indexed', most articles define this status as Google having crawled the page but not yet chosen to index it.
This comes directly from Google's documentation:
“The page was crawled by Google but not indexed. It may or may not be indexed in the future; no need to resubmit this URL for crawling”.
And these pages have been actively removed by Google from its index.
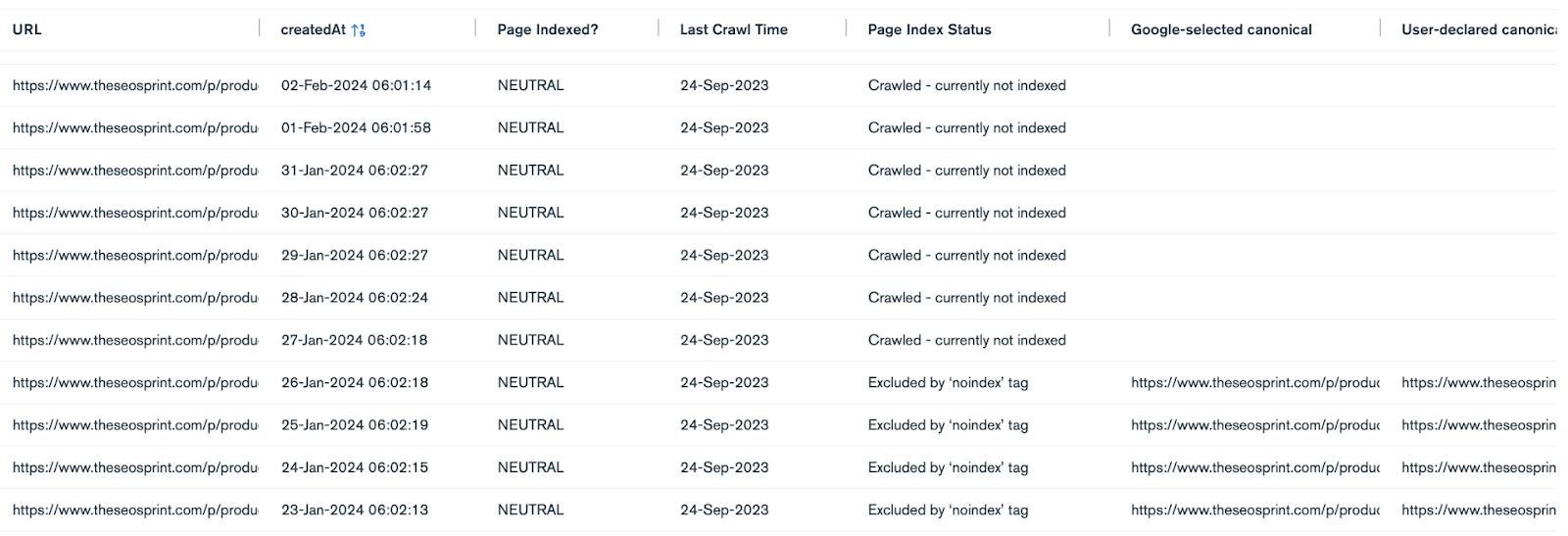
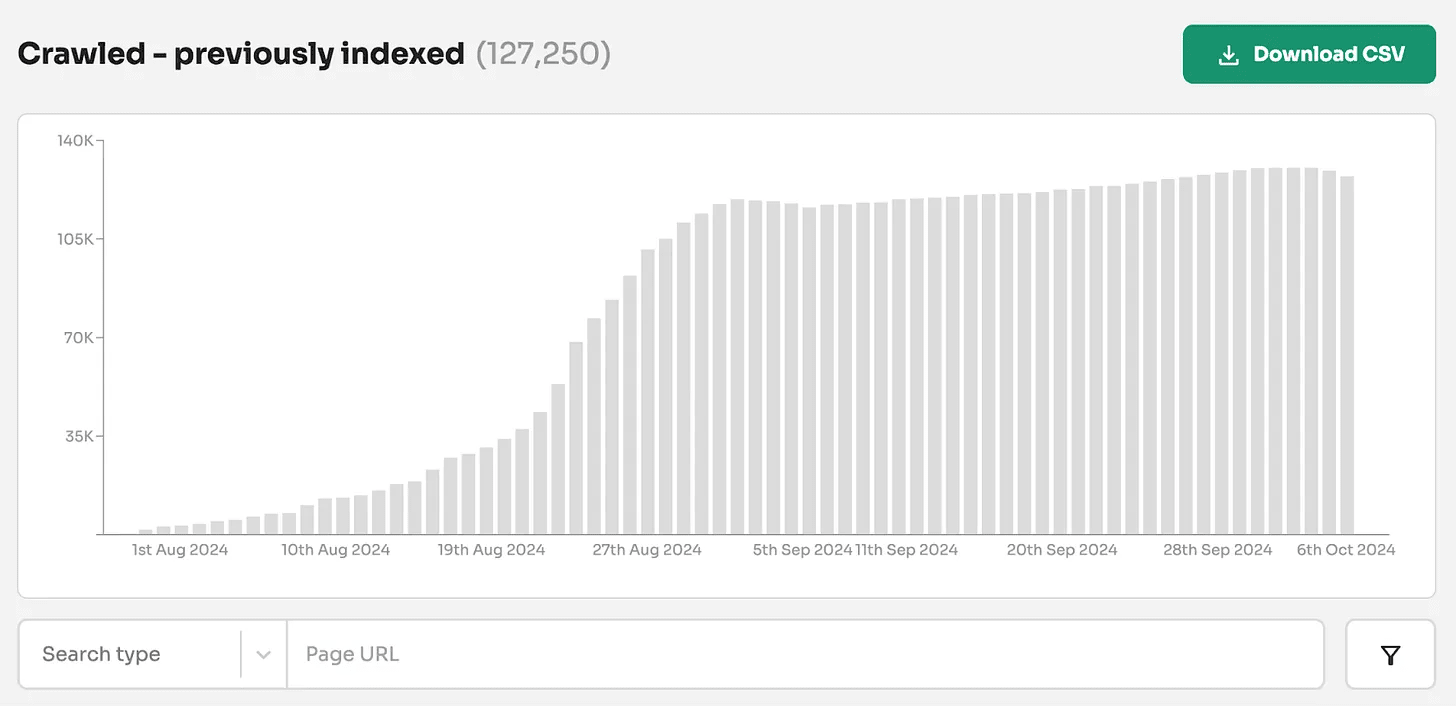
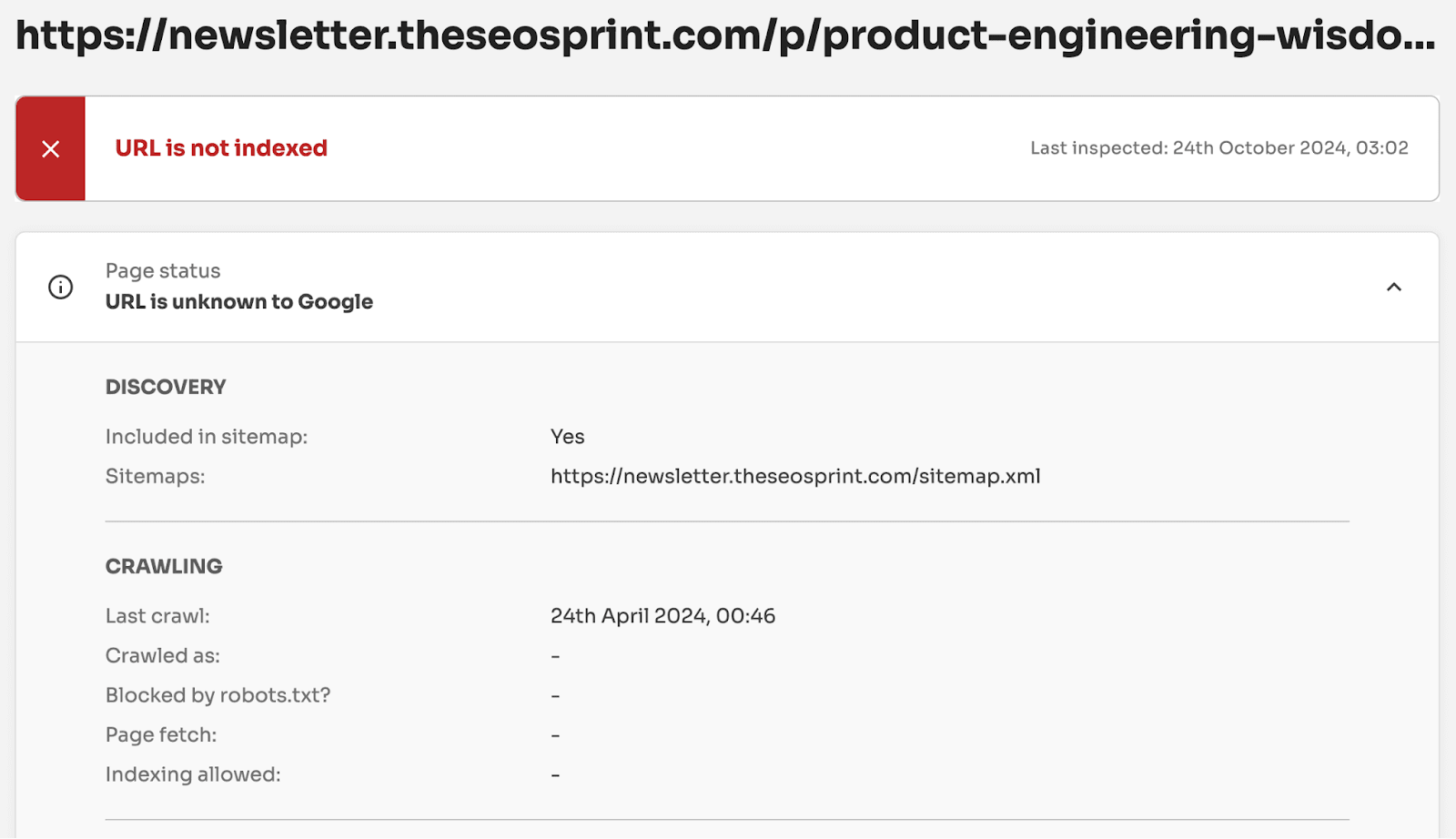
This means when you see this status, you're not looking at pages waiting to be indexed. In fact, you're looking at pages Google has actively removed from its search results.
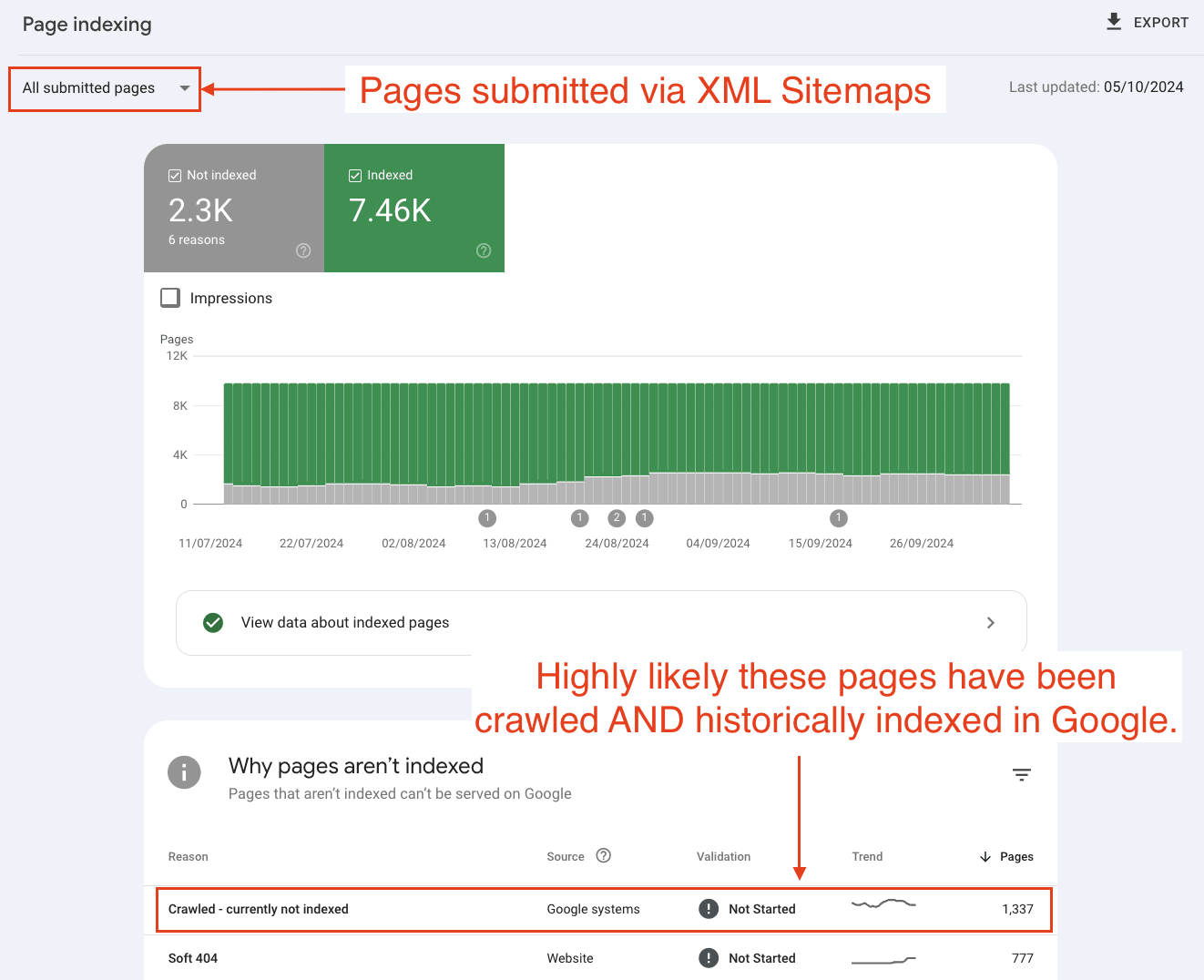
For one client alone, we found nearly 130,000 pages with what should be called 'crawled - previously indexed' status. That's 13% of their monitored pages that Google has actively removed from serving in search results.
This data helped the client understand they needed to take action. Not waiting for indexing.
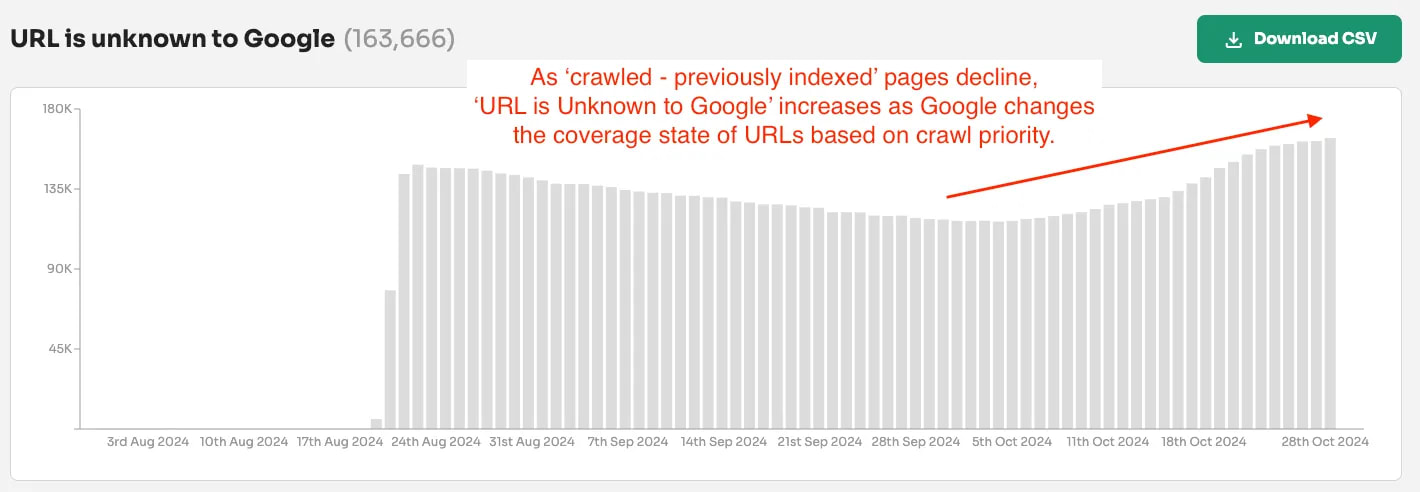
2. Google can 'forget' URLs have been previously crawled and indexed
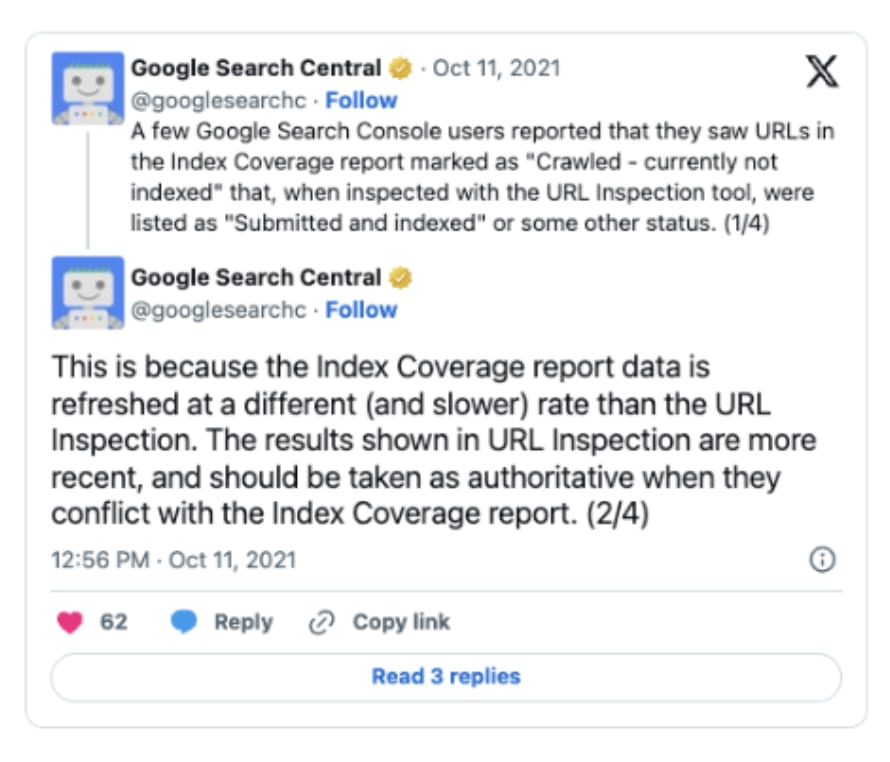
The coverage state 'URL is unknown to Google' is even more misleading than you might think.
Google's official documentation states:
"If the label is URL is unknown to Google, it means that Google hasn't seen that URL before, so you should request that the page be indexed. Indexing typically takes a few days."
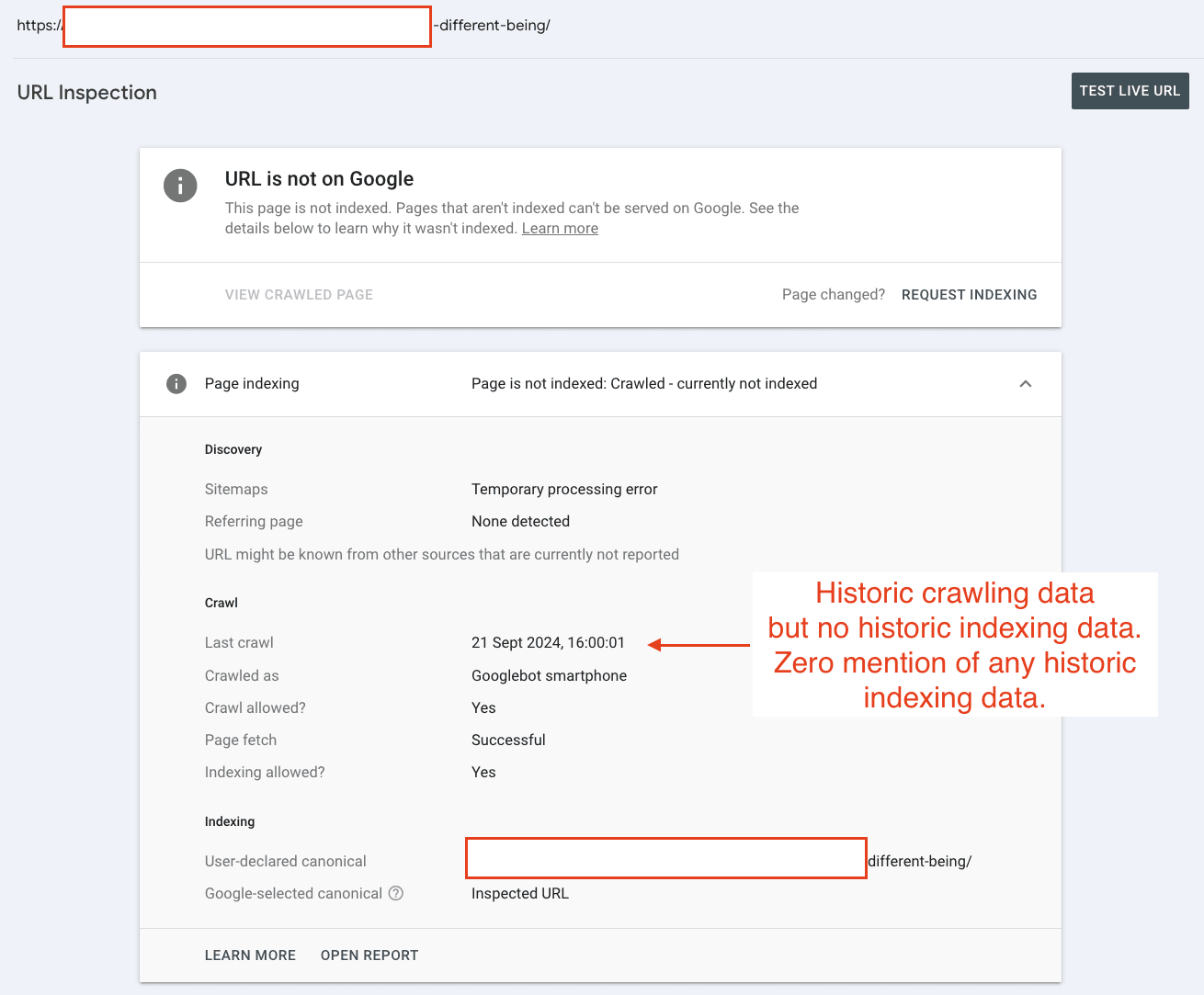
But our data tells a different story. Many pages labeled as 'URL is unknown to Google' have actually been crawled and indexed before.
Gary Illyes from Google confirmed this phenomenon on LinkedIn, explaining that Google's systems can "forget" URLs as they purge low-value pages from their index over time.
The signals Google collects about a page can eventually lead to it being forgotten entirely.
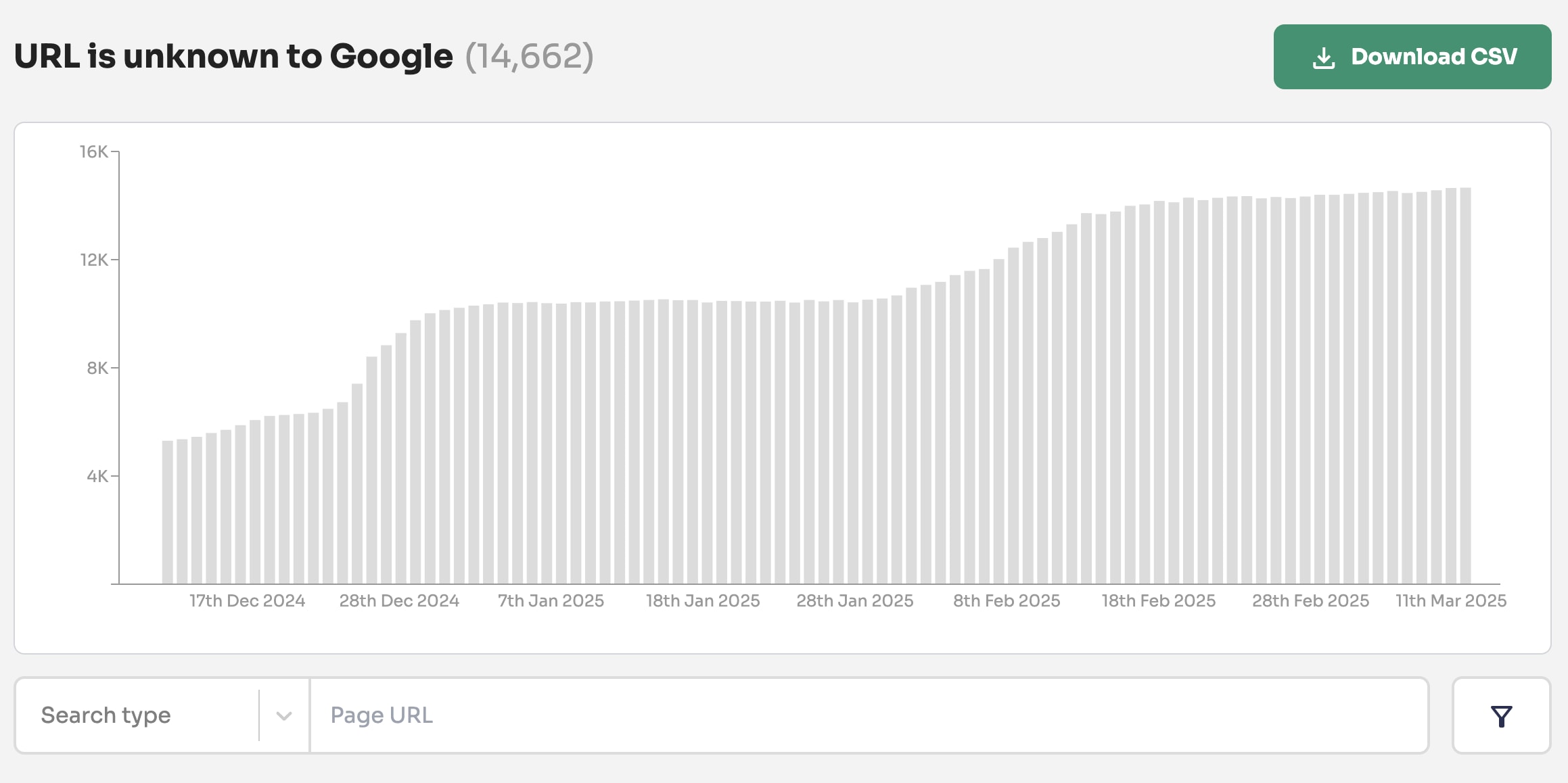
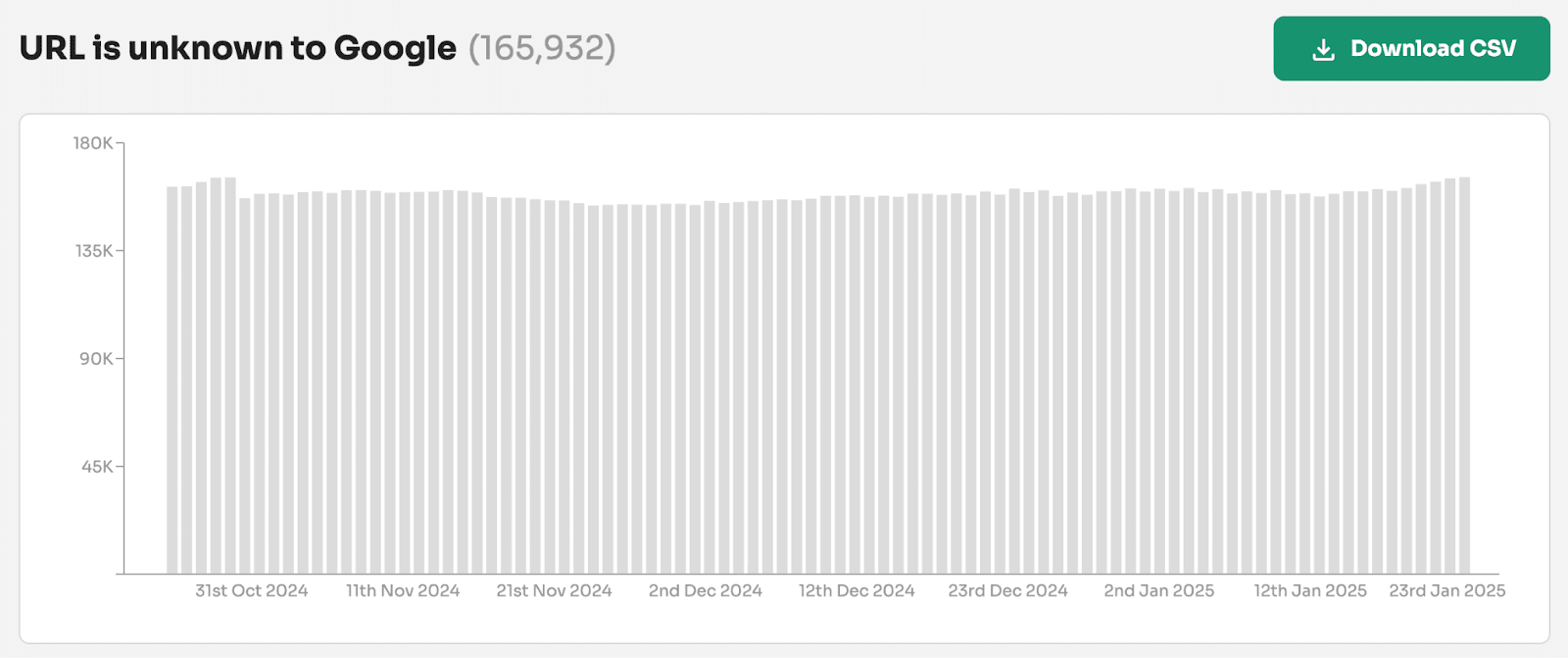
For one website monitoring 1 million URLs, 16% of URLs were labelled 'URL is unknown to Google' and many of these had search performance data proving they were previously indexed.
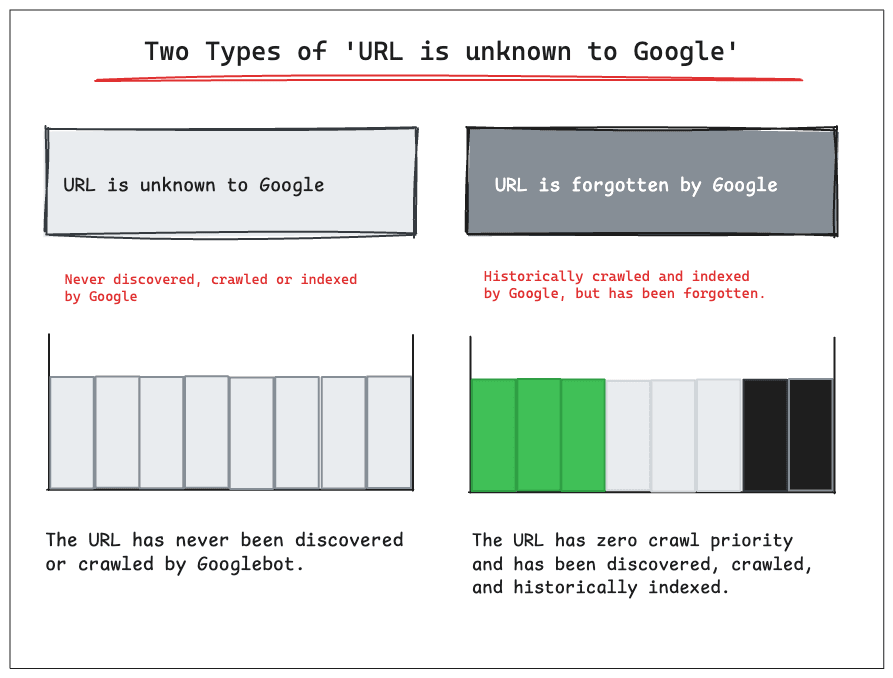
Based on this first-party data, ‘URL is unknown to Google’ should be split into two different definitions:
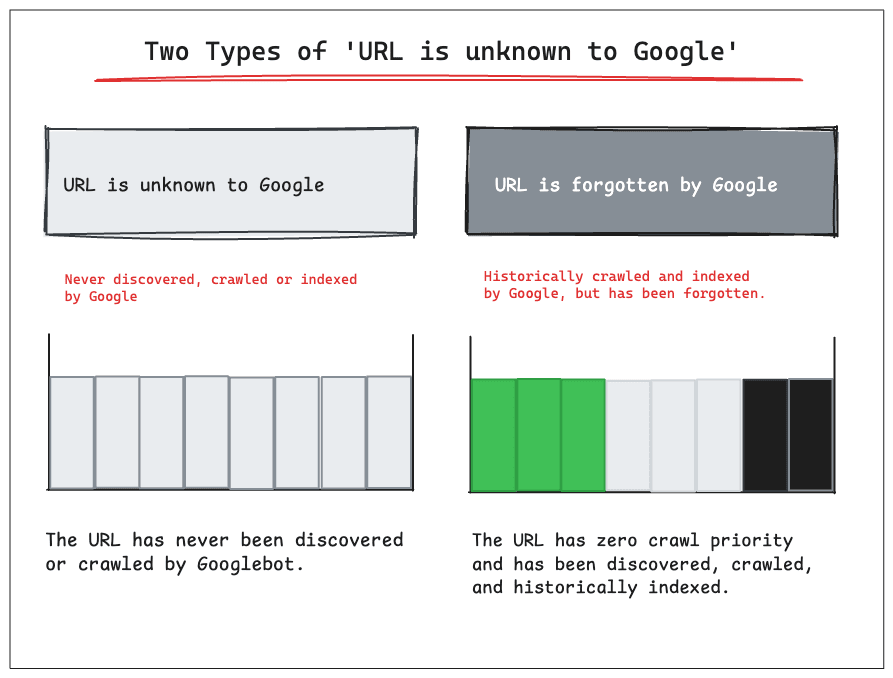
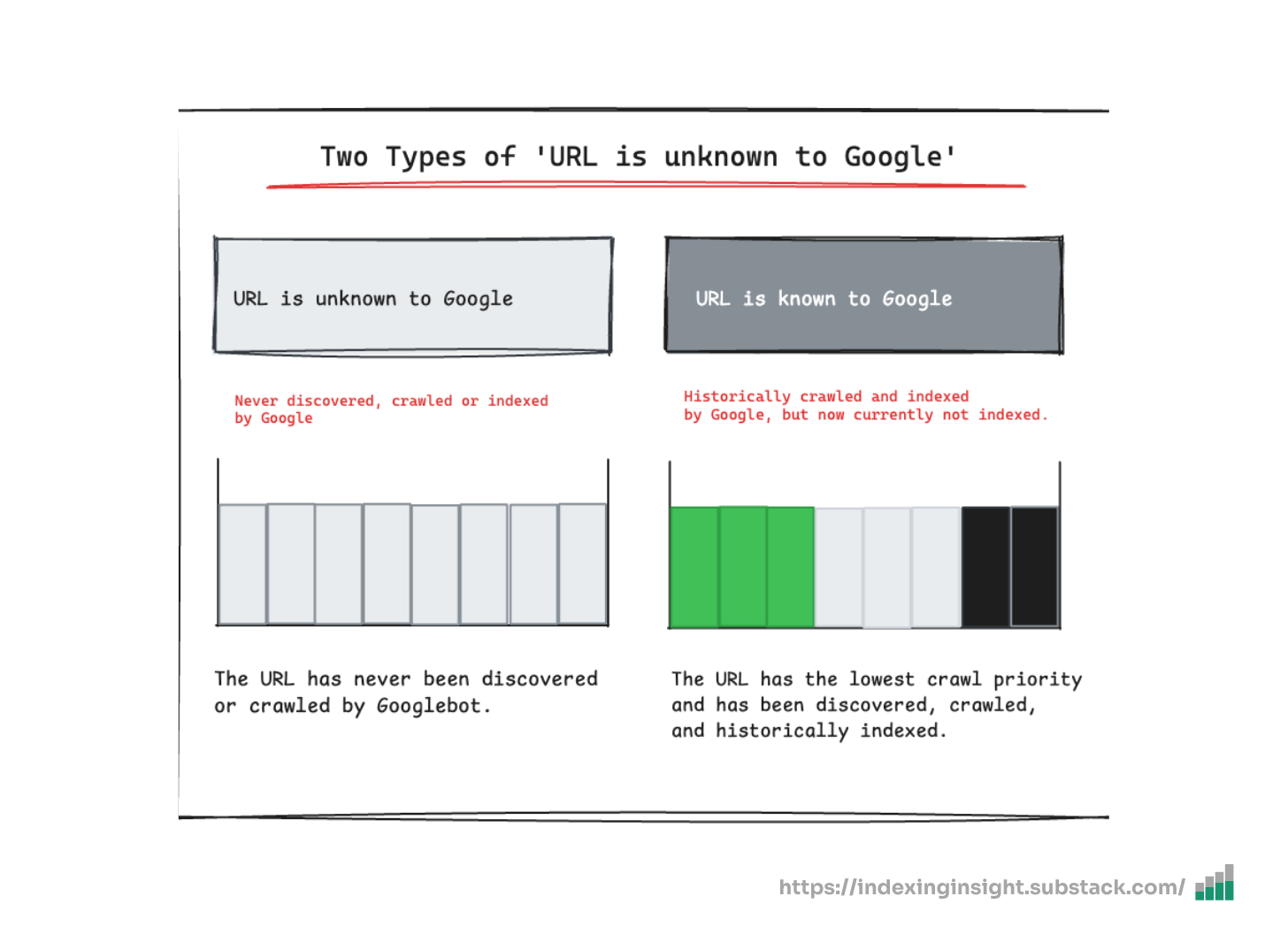
URL is unknown to Google: The URL has never been discovered or crawled by Googlebot.
URL is forgotten by Google: The URL was previously crawled and indexed by Google but has been forgotten.
This distinction is crucial for understanding the true health of your website in Google's index.
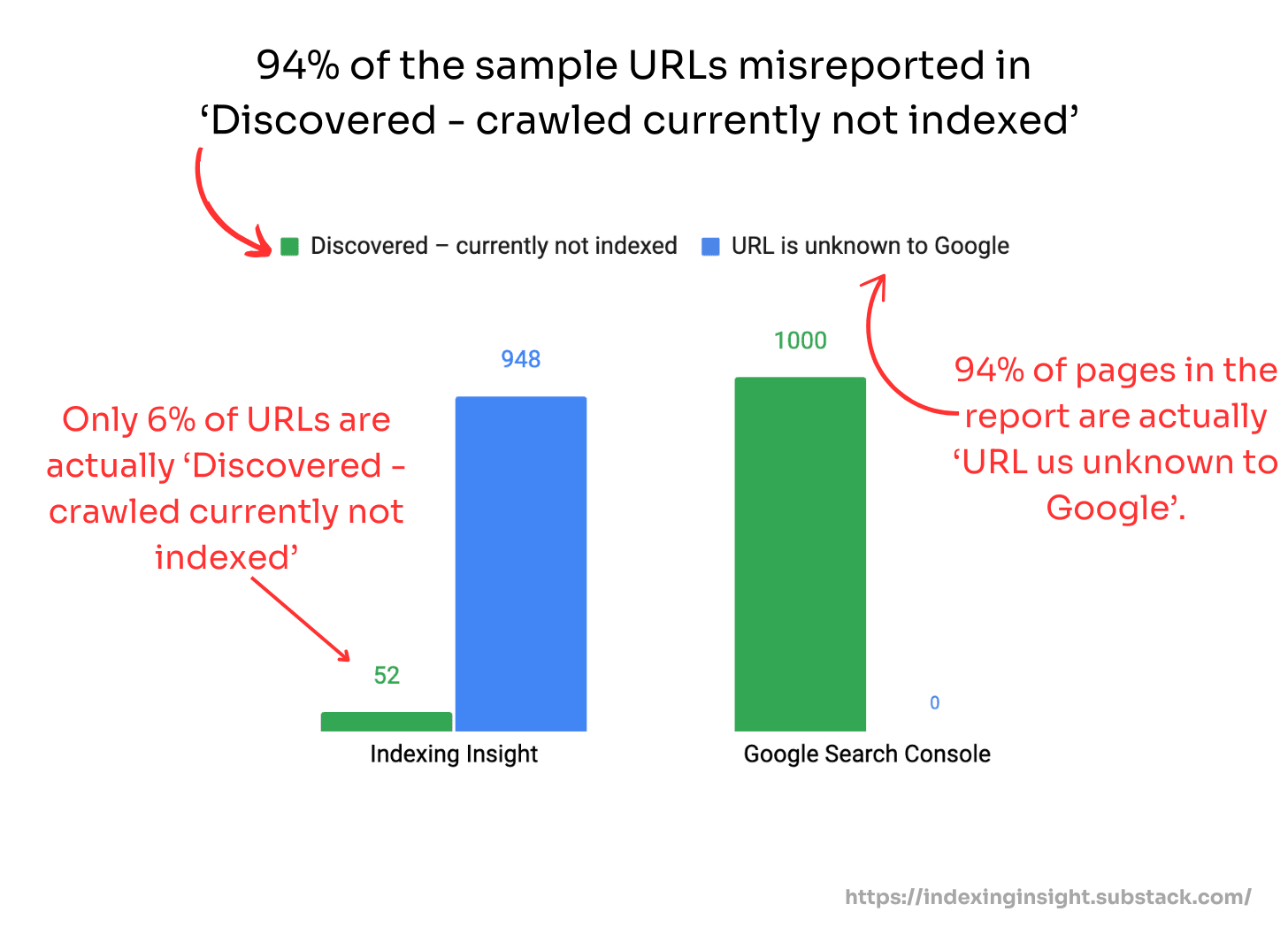
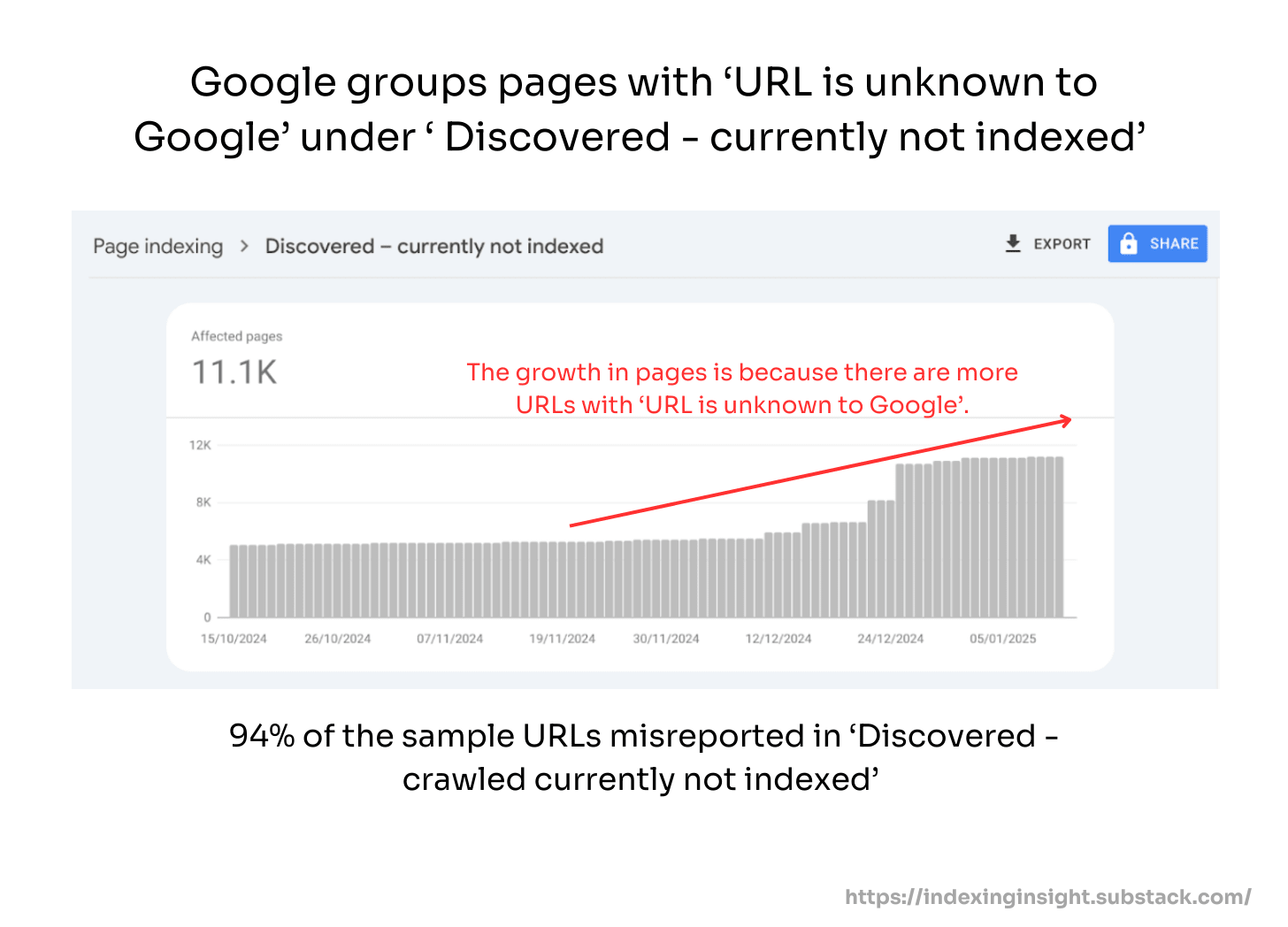
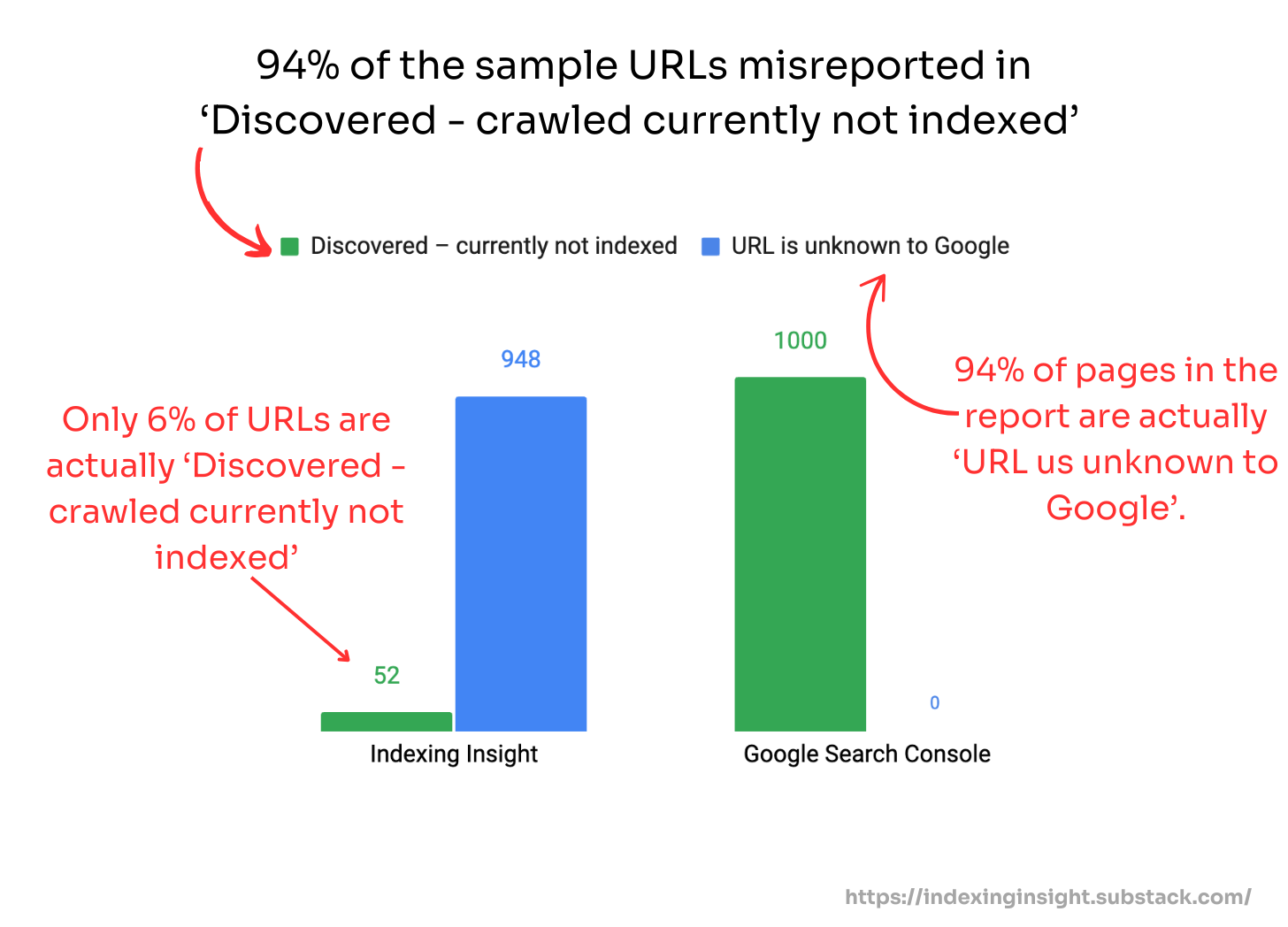
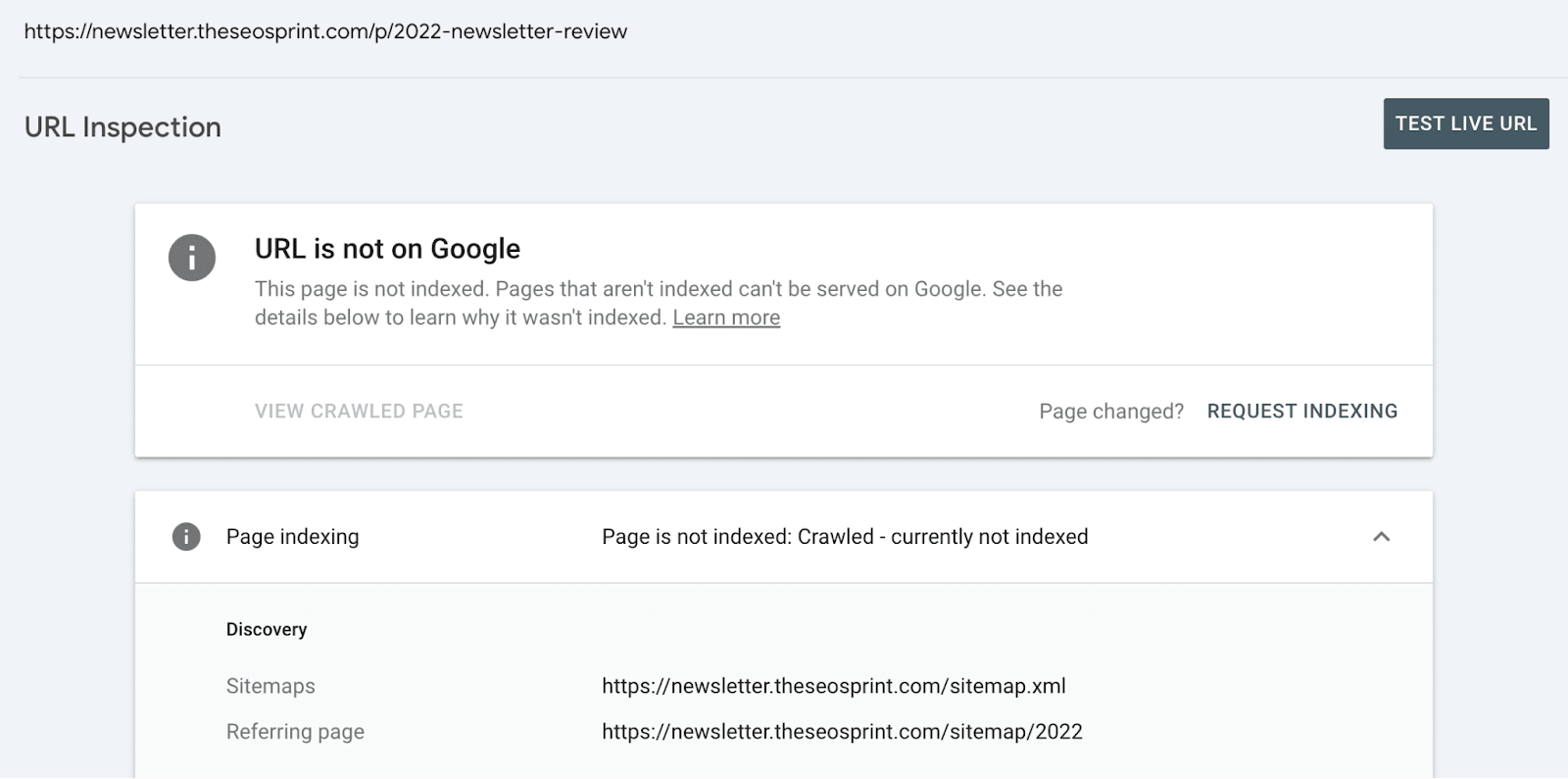
3. Google Search Console misreports 'URL is unknown to Google' pages in ‘Discovered - currently not indexed’
When Google actively deprioritizes your pages, GSC doesn't tell you the whole truth.
Our analysis found that 94% of pages that should be labeled 'URL is unknown to Google' are instead grouped under the 'Discovered - currently not indexed' report in GSC.
This misreporting isn't a bug. It's by design.
When you inspect these URLs individually using the URL Inspection tool, they show the 'URL is unknown to Google' status, contradicting what the Page Indexing report shows.
Why does this matter?
Because pages with 'URL is unknown to Google' status have zero crawl priority in Google's system, according to Gary Illyes.
When you can't see which pages have this status, you can't take appropriate action to address the underlying quality issues.
By grouping these URLs under 'Discovered - currently not indexed', GSC leads you to believe you have a discovery problem when you actually have a quality problem that's so severe Google has chosen to forget your content entirely.
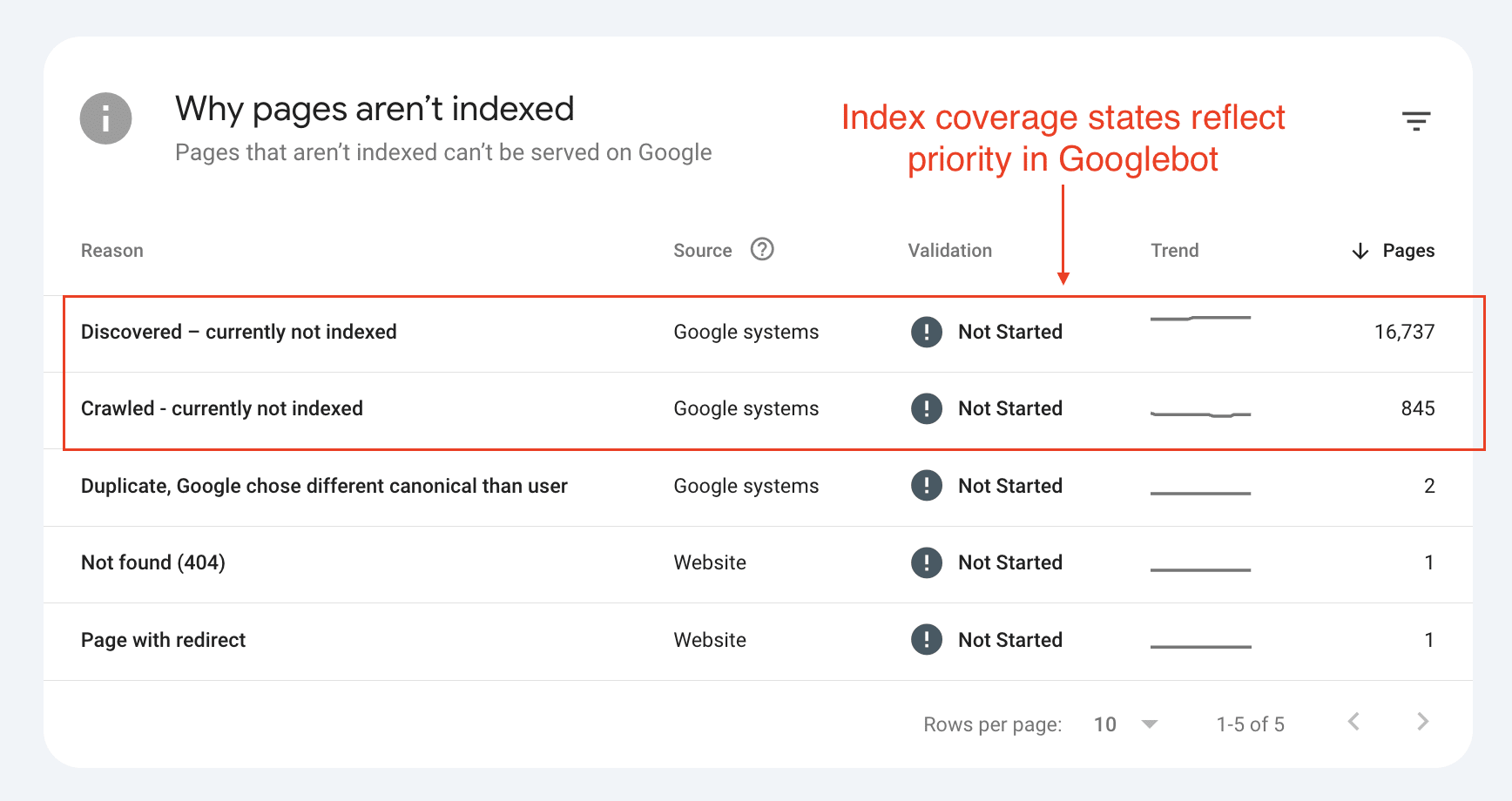
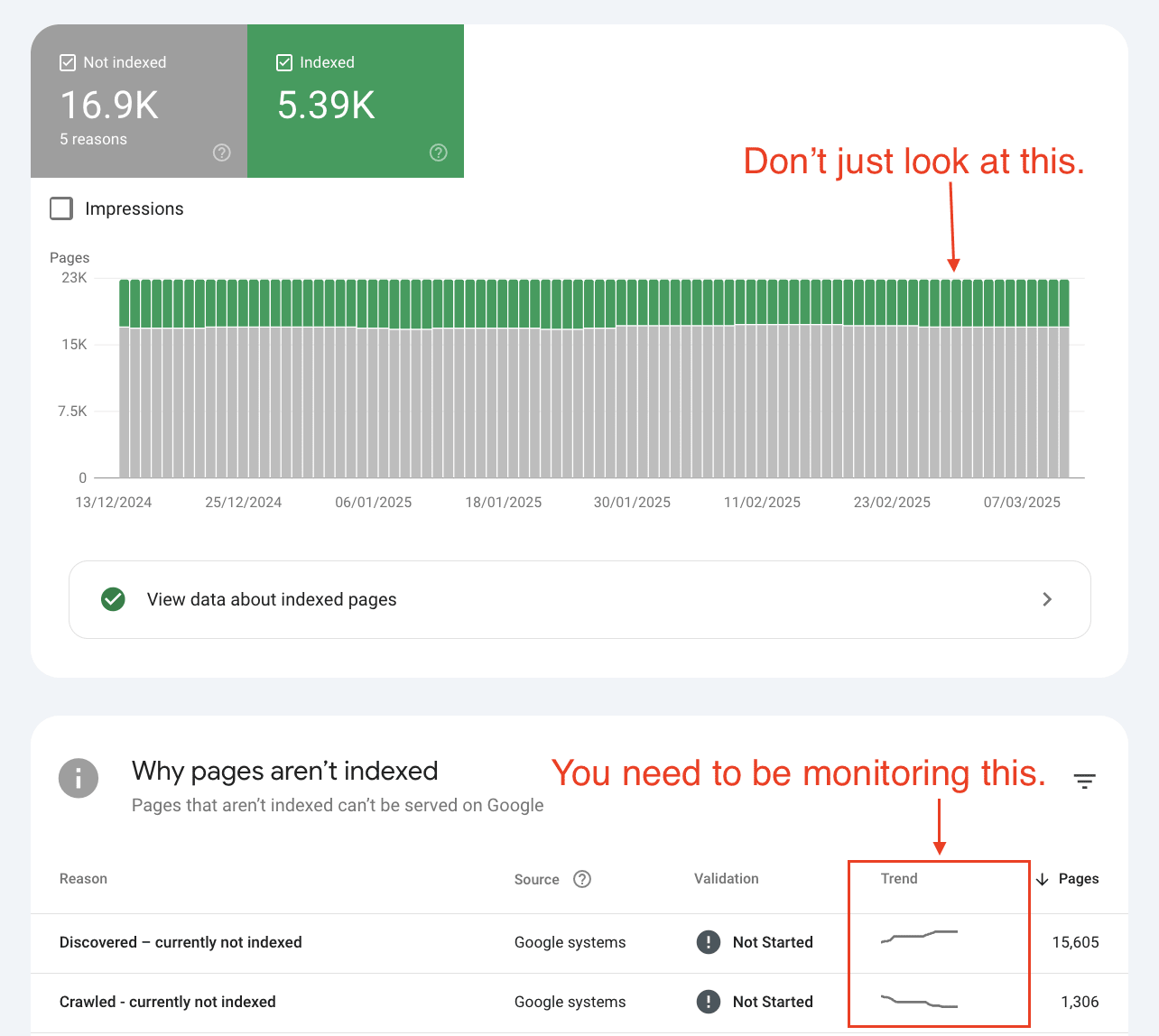
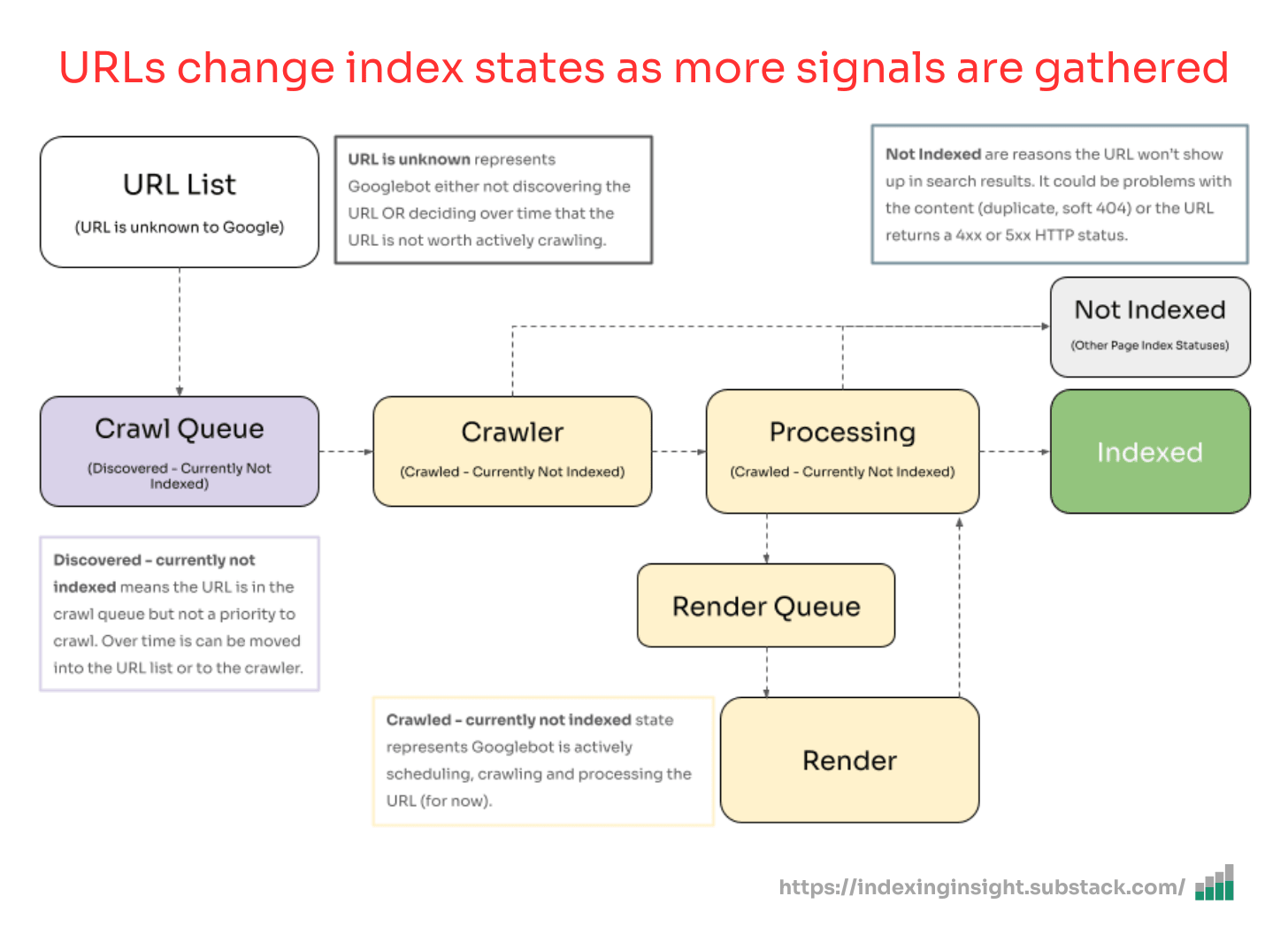
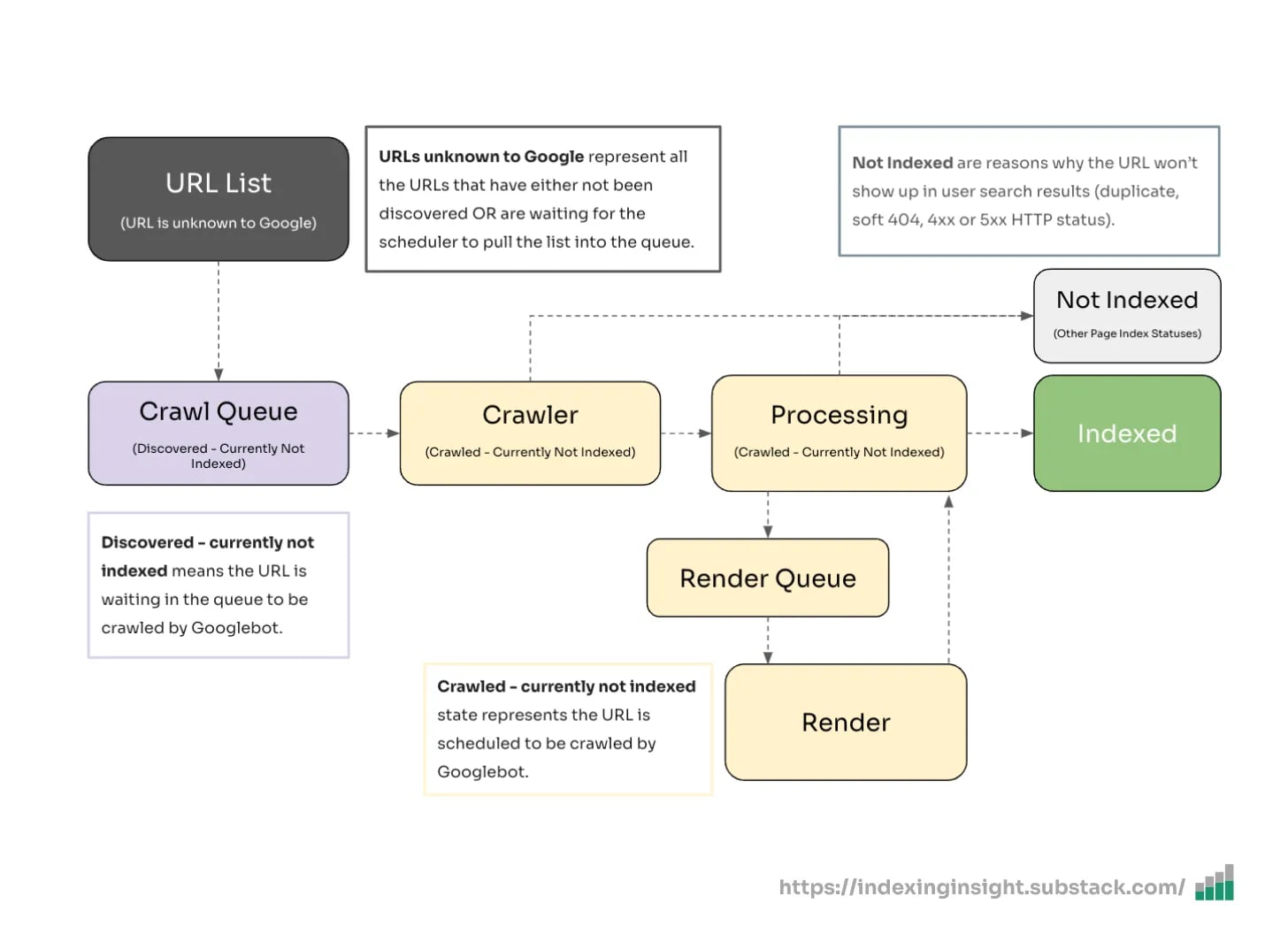
4. Index coverage states reveal your site's crawl priority
The various index states in GSC aren't just status labels, they're indicators of how Google prioritizes crawling your site.
Based on data from Indexing Insight and confirmation from Google's Martin Splitt, we can map the index coverage states to Googlebot's crawl, render, and index process:
'Submitted and indexed': Higher priority, actively shown in search results
'Crawled - currently not indexed': Medium priority, stored but not served
'Discovered - currently not indexed': Low priority, on the crawl list but deprioritized
'URL is unknown to Google': Zero priority, completely forgotten
Pages can move backwards through these states over time.
This reverse progression through index states often accelerates after Google core updates, indicating system-wide reprioritization of what's worth crawling and indexing.
When a page moves from 'Submitted and indexed' to 'URL is unknown to Google,' it shows that Google's systems have determined that it has such a low value that it's not worth remembering.
5. URL Inspection tool and Page Indexing report conflict
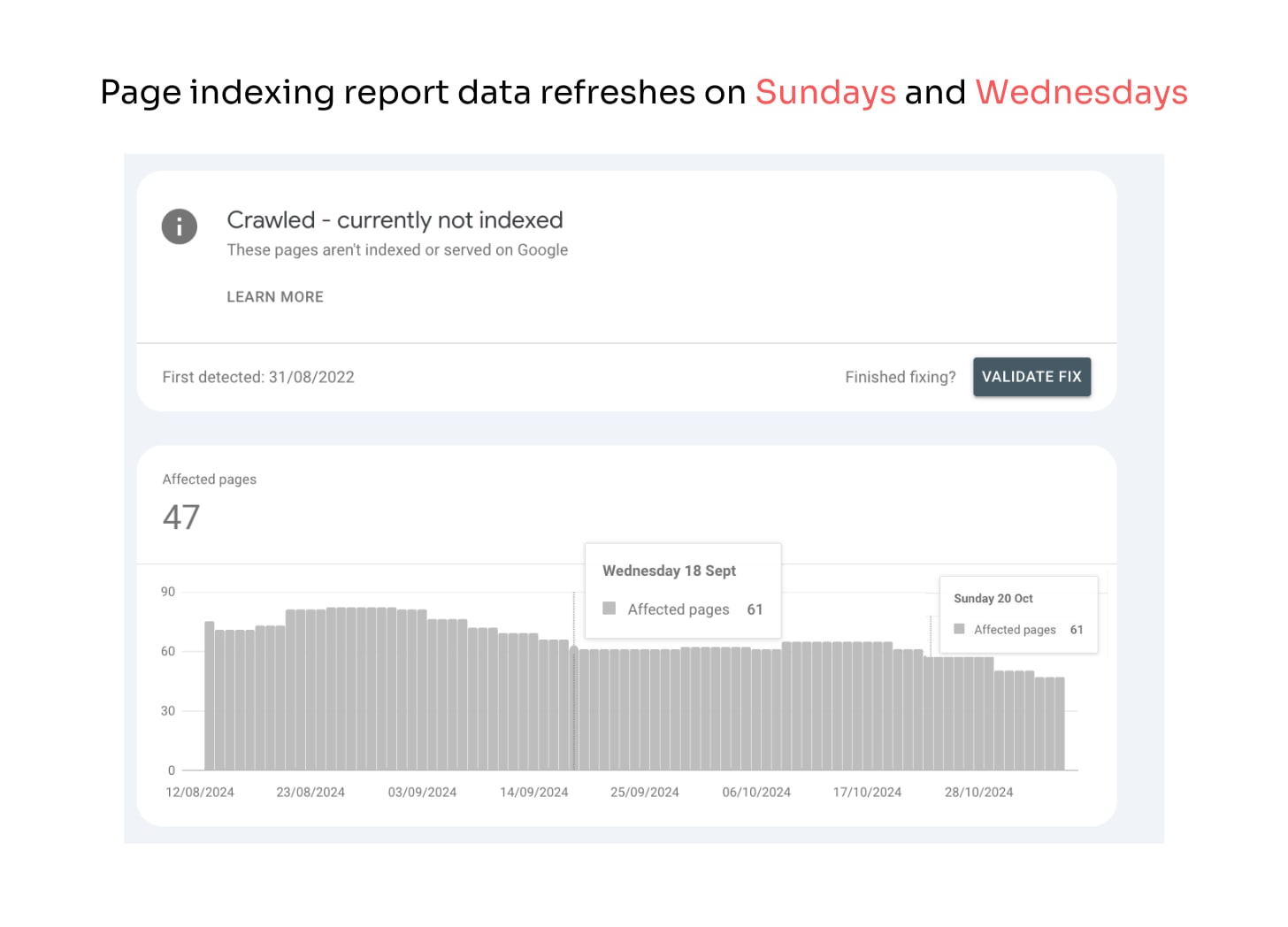
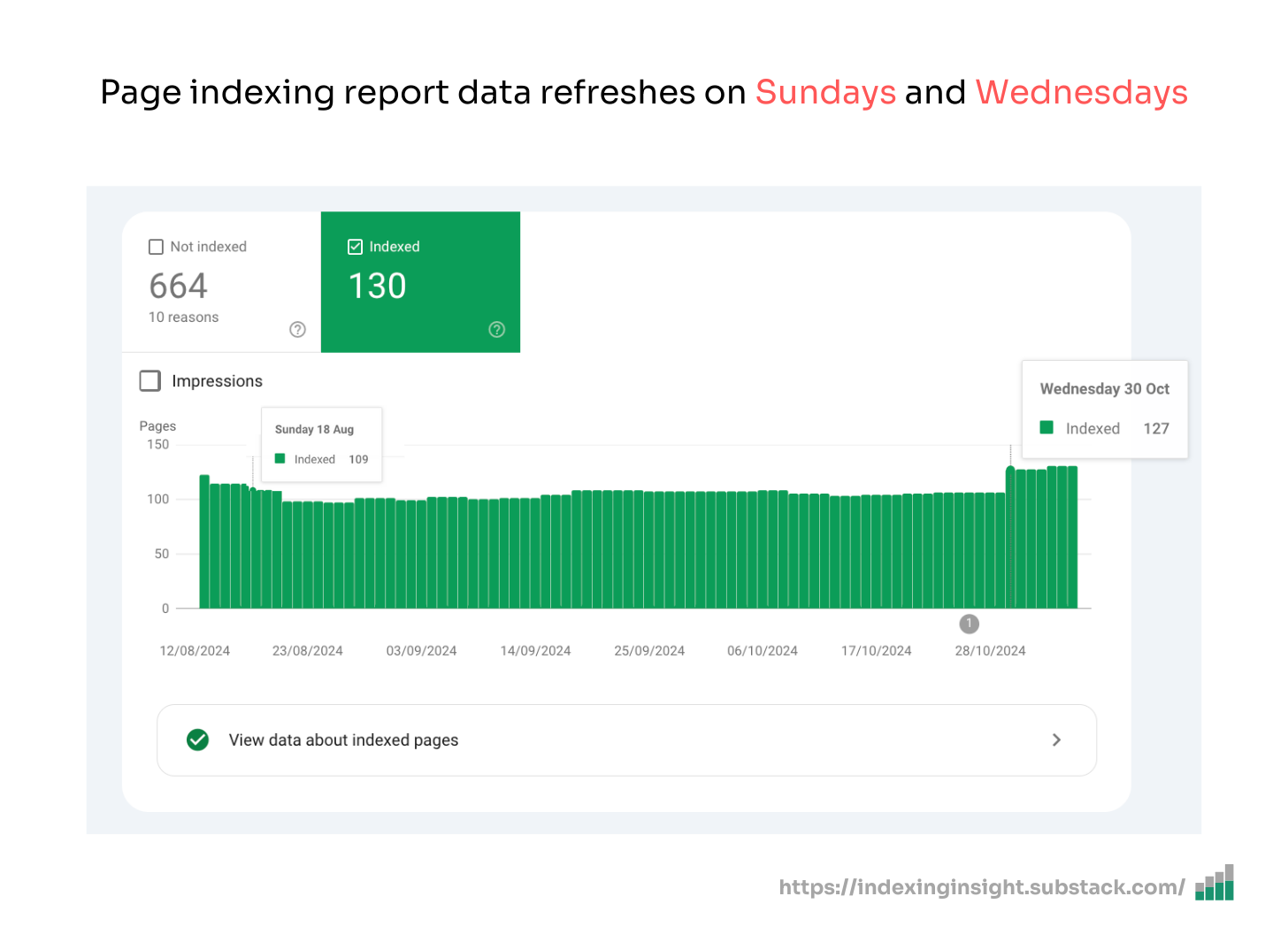
When you see conflicting data between the URL Inspection tool and the Page Indexing report, you should always trust the URL Inspection tool.
Here's why:
Page Indexing report updates only twice a week (Sundays and Wednesdays)
The URL Inspection tool pulls live information directly from Google's index
The Google Search Central team has confirmed that the URL Inspection Tool is the most authoritative source for indexing data and should be considered the source of truth when conflicts arise.
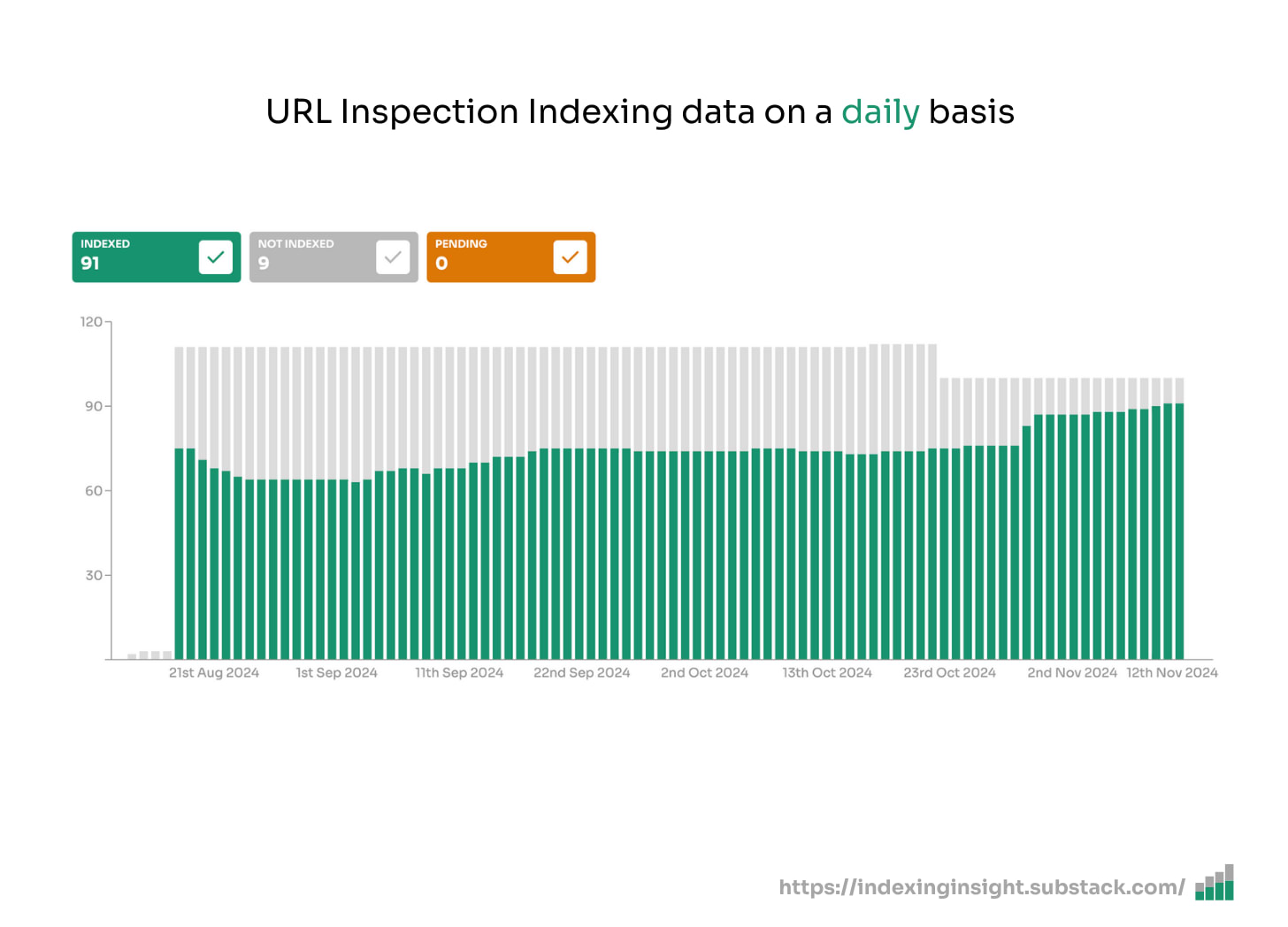
This means that for truly accurate indexing analysis, you need to inspect URLs individually or use the URL Inspection API, which is what Indexing Insight does to provide daily monitoring.
It completely changes how you should approach SEO analysis:
When you see 'crawled - currently not indexed', don't assume these pages are waiting to be indexed. Most likely, Google has actively removed them from the index.
After Google Core updates, check both your rankings AND your indexing status. Core updates don't just affect rankings — they actively reprioritize what's worth crawling and indexing.
Look beyond the surface-level Page Indexing report. The most important insights come from tracking coverage state changes over time, which GSC doesn't show.
Always verify with the URL Inspection tool for important pages with indexing issues rather than trusting the Page Indexing report.
If you find many important pages with 'URL is unknown to Google' or 'Discovered—currently not indexed' status, this indicates severe quality issues that need to be addressed before Google will consider re-indexing them.
These nuances become even more critical for sites with 100,000+ pages as the scale makes manual analysis through GSC virtually impossible.
📌 Summary
The Page Indexing report in Google Search Console doesn't tell the full story about your website's indexing health.
By understanding the true meaning behind coverage states, the misreporting of 'URL is unknown to Google', and how index states indicate crawl priority, you can develop a more accurate picture of how Google views your content.
Importantly, when Google core updates roll out, they don't just impact rankings.
They actively cause Google's systems to reprioritize what is worth crawling and indexing, potentially removing large numbers of pages from the index entirely.
Hopefully, this newsletter has inspired you to examine your page indexing report with a new perspective and identify which pages are truly at risk in Google's indexing system.
📊 Interested in Google index monitoring?
Indexing Insight is a tool for monitoring Google indexing at scale. It is for websites with 100K—1 million pages.
Check out the demo of the tool using the link below.
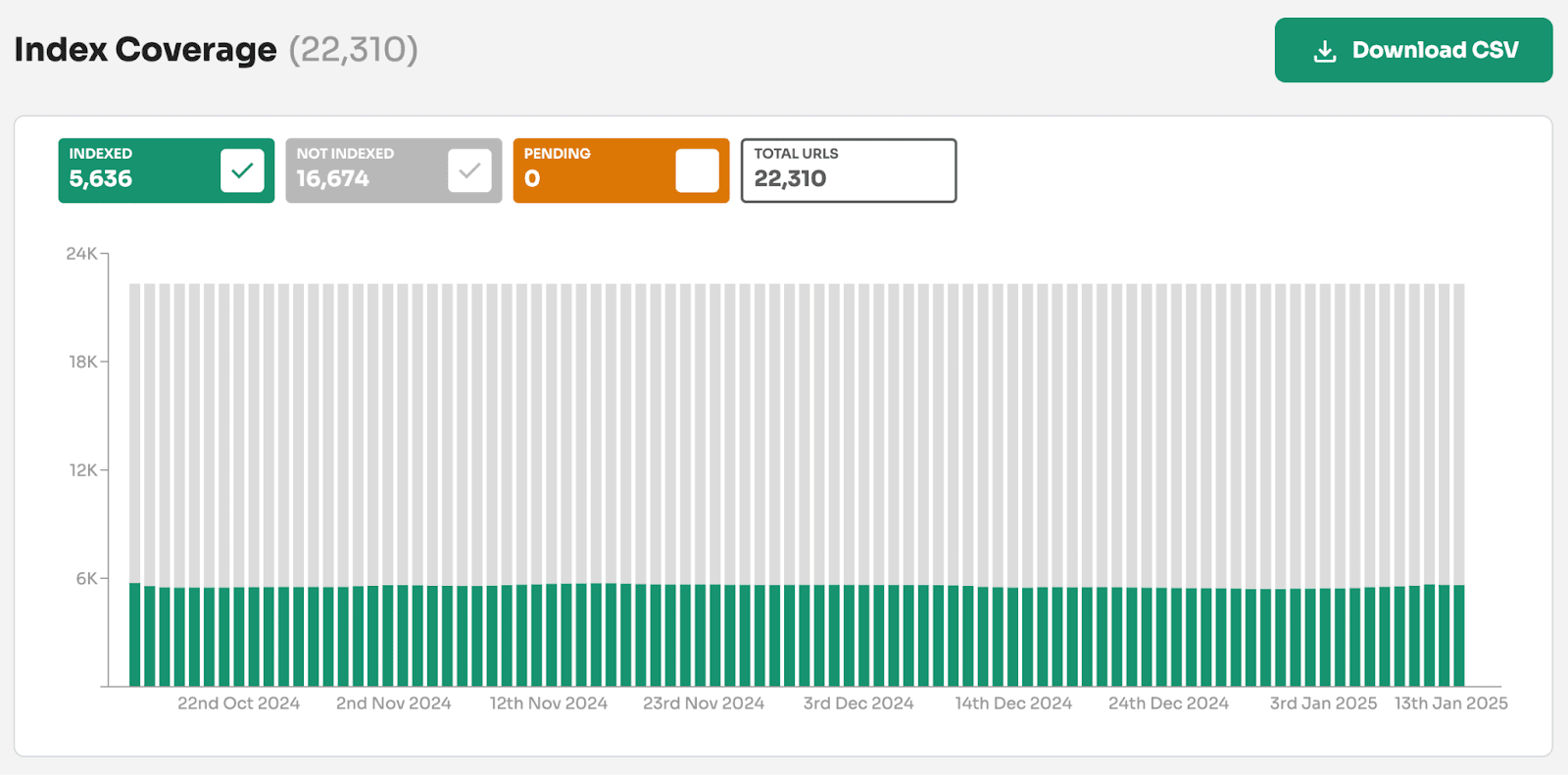
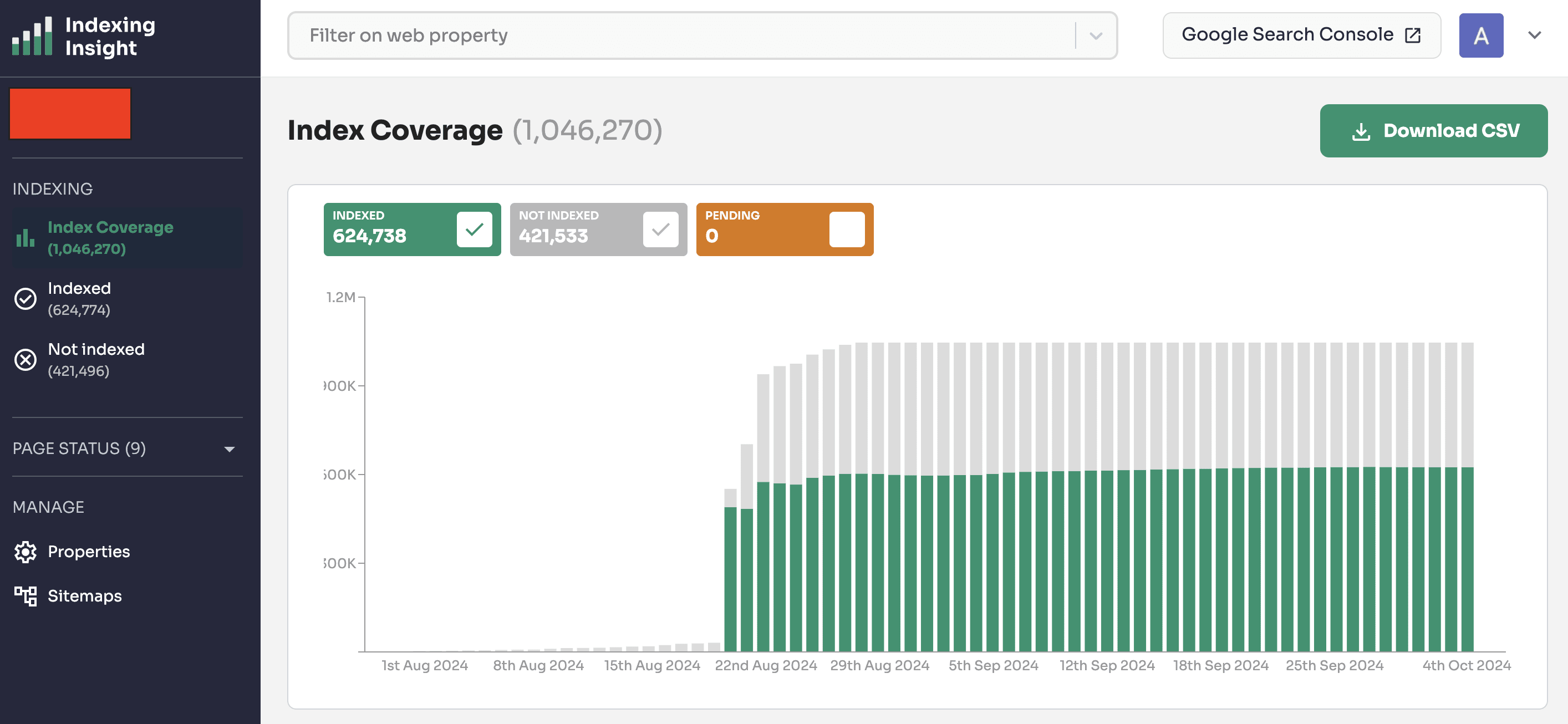
Indexing Insight is a unique tool that helps you monitor Google indexing for large-scale websites with 100,000 to 1 million pages.
Index Coverage Report in Indexing Insight
The tool can be broken down into 5 key features:
⚙️ Daily monitoring: The tool is automated; it checks your selected XML sitemaps daily for changes and monitors the indexing state of your pages.
🕵️ Daily inspection: The tool uses the URL inspection API to monitor Google indexing on a daily basis for your most important pages.
✉️ Daily email alerts: The tool sends out a daily email alert with a breakdown of any indexing changes to your pages, sent straight to your inbox.
📊 Data Analysis: The tool allows you to segment using URL subdirectories and filter/sort based on several indexing data points.
⬇️ Downloading data: The tool allows you to download unlimited rows from any report (even when segmenting or filtering the data).
👥 Who is Indexing Insight for?
Indexing Insight is designed for large-scale websites with 100K - 1 million URLs.
Our tool is for SEO, marketing, and product teams working in industries with large and complex websites.
For example:
🛒 E-commerce: Our tool can help Ecommerce SEO specialists monitor the indexing state of important revenue-driving categories and product pages.
✈️ Travel: Our tool can help SEO teams identify which key travel categories are actively removed from Google’s search results.
📰 Publishing: Our tool can help SEO teams monitor the index state of evergreen content hubs in Google’s search results.
🖥️ SaaS: Our tool can help B2B SaaS SEO experts monitor the indexing state of the blog, guide, and programmatic content.
🏢 Listings: Our tool can help SEO teams that manage listing websites monitor the indexing state of hundreds of thousands of pages.
🌍 International: Our tool can help SEO teams identify which pages across multiple international sites are not appearing in Google search results.
❓ Why use Indexing Insight?
Indexing Insight allows you to unlock insights hidden in Google Search Console.
Crawled - previously indexed report in Indexing Insight
The benefits of using Indexing Insight:
🚀 Monitor 3x faster: Our tool is designed to help you maximise the GSC API limits to get indexing data 2-3 times faster than any other tool on the market.
🏭 Automation built-in: Our tool saves you hours of time by automating downloading important pages from XML sitemaps and inspecting URLs.
💰 Build a business case: Our tool allows you to export data and combine it with other third-party tools to build a business case for your SEO opportunities.
❤️🩹 Monitor content quality: Our unique reports help identify indexed pages that are being actively removed from Google’s search results.
📈 Add indexing data to reports - Our tool allows you to monitor the entire website or specific site sections so you can add index data as part of your KPIs.
Don’t just take our word for it:
⚙️ How does Indexing Insight work?
Indexing Insight is simple to set up and manage.
The tool is designed to help SEO teams be in complete control of which important pages they want to monitor.
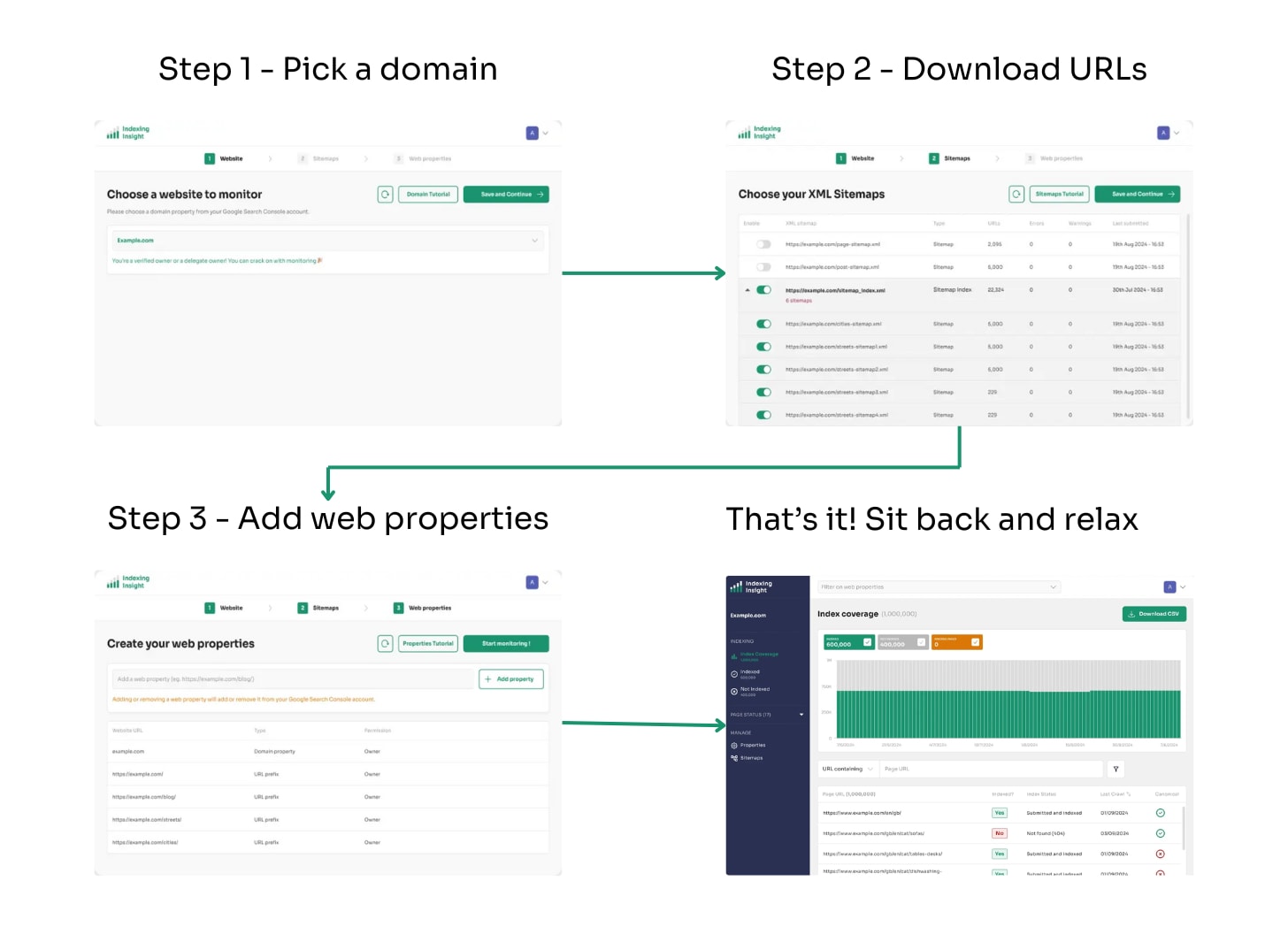
Any website can start monitoring in three easy steps:
🌐 Pick a domain: Log into your Google Account and choose the domain property you want to monitor.
📄 Download URLs: Select individual XML Sitemaps or your Sitemap Index that have been submitted to GSC.
📁 Add web properties: Create URL prefix web properties based on your website’s folder structure.
3 steps to set up monitoring in Indexing Insight
That’s it! You can sit back, relax and let our tool do all the heavy lifting.
Our tool automatically optimises the limits within the Search Console API, enabling you to effectively monitor your website's Google indexing on a large scale.
But that’s not all!
Once you’ve set up your project, you can add or remove both your sitemaps and/or web properties for the project. Any changes will be taken into account in the next scheduled inspection (the next day).
So, you always remain in complete control over what pages are inspected.
Web Properties Settings in Indexing Insight
💲 What are the pricing plans?
Indexing Insight has three pricing plans:
Automate - For companies who want to monitor up to 100,000 URLs.
Scale - For companies who want to monitor up to 500,000 URLs.
Company - For companies who want to monitor up to 1,000,000 URLs.
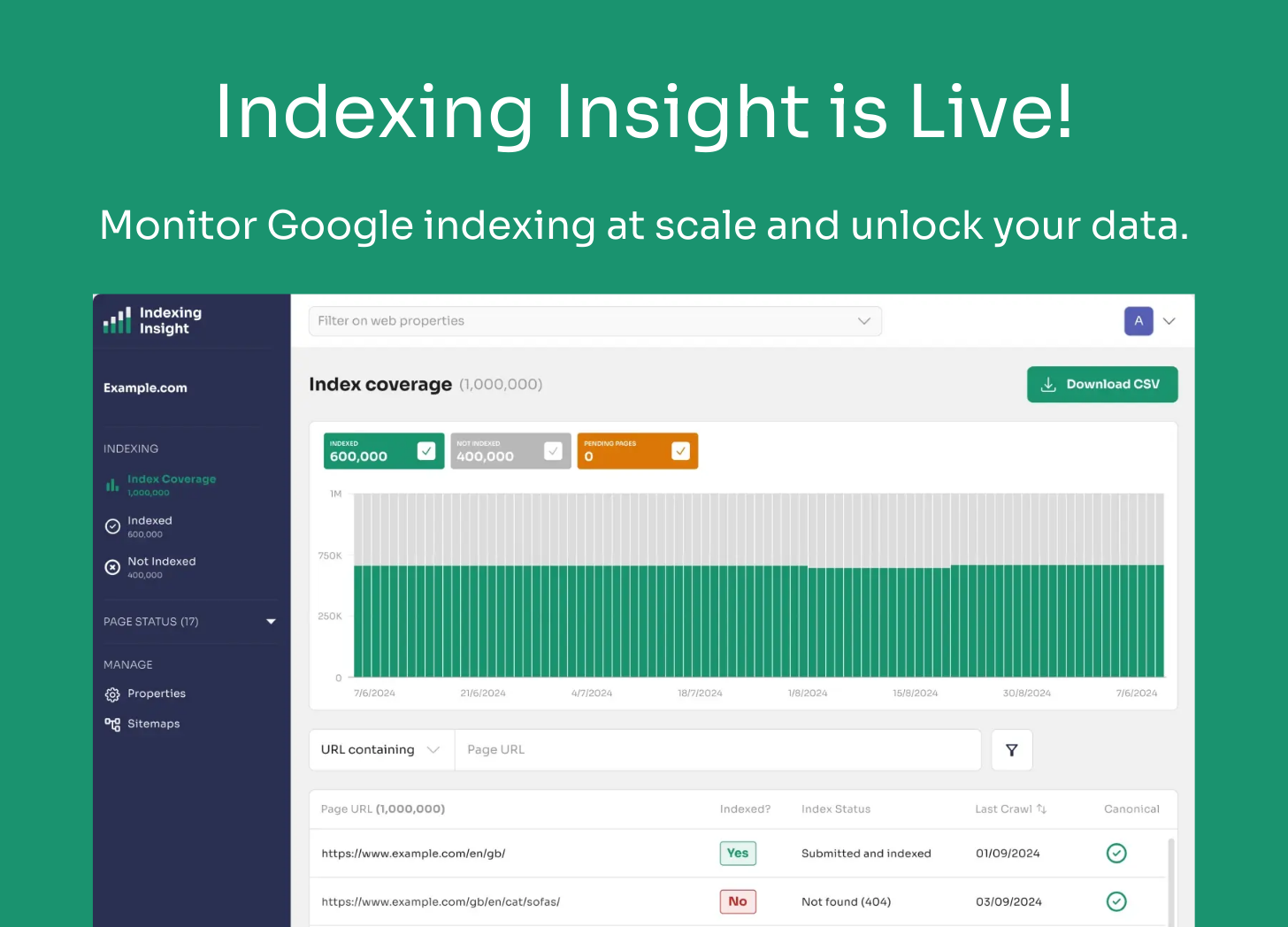
Indexing Insight will go live on 17th Feb 2025 at 12 pm UK time (7 am EST).
Any SEO team who wants to start Google index monitoring at scale will be able to use the tool to unlock their data.
We’ve provided more details about the tool below👇.
🎁 Special Subscriber Discount: For anyone who has signed up to this newsletter before the go live date you will get an email with an early bird discount code of 10% for any plan.
The discount code has a limited time offer and will expire on 28/02/2025.
Indexing Insight is a unique tool that helps you monitor Google indexing for large-scale websites with 100,000 to 1 million pages.
Index Coverage Report in Indexing Insight
The tool can be broken down into 5 key features:
⚙️ Daily monitoring: The tool is automated; it checks your selected XML sitemaps daily for changes and monitors the indexing state of your pages.
🕵️ Daily inspection: The tool uses the URL inspection API to monitor Google indexing on a daily basis for your most important pages.
✉️ Daily email alerts: The tool sends out a daily email alert with a breakdown of any indexing changes to your pages, sent straight to your inbox.
📊 Data Analysis: The tool allows you to segment using URL subdirectories and filter/sort based on several indexing data points.
⬇️ Downloading data: The tool allows you to download unlimited rows from any report (even when segmenting or filtering the data).
👥 Who is Indexing Insight for?
Indexing Insight is designed for large-scale websites with 100K - 1 million URLs.
Our tool is for SEO, marketing, and product teams working in industries with large and complex website setups.
For example:
🛒 E-commerce: Our tool can help Ecommerce SEO specialists monitor the indexing state of important revenue-driving categories and product pages.
✈️ Travel: Our tool can help SEO teams identify which key travel categories are actively removed from Google’s search results.
📰 Publishing: Our tool can help SEO teams monitor the index state of evergreen content hubs in Google’s search results.
🖥️ SaaS: Our tool can help B2B SaaS SEO experts monitor the indexing state of the blog, guide, and programmatic content.
🏢 Listings: Our tool can help SEO teams that manage listing websites monitor the indexing state of hundreds of thousands of pages.
🌍 International: Our tool can help SEO teams identify which pages across multiple international sites are not appearing in Google search results.
❓ Why use Indexing Insight?
Indexing Insight allows you to unlock insights hidden in Google Search Console.
Crawled - previously indexed report in Indexing Insight
The benefits of using Indexing Insight:
🚀 Monitor 3x faster: Our tool is designed to help you maximise the GSC API limits to get indexing data 2-3 times faster than any other tool on the market.
🏭 Automation built-in: Our tool saves you hours of time by automating downloading important pages from XML sitemaps and inspecting URLs.
💰 Build a business case: Our tool allows you to export data and combine it with other third-party tools to build a business case for your SEO opportunities.
❤️🩹 Monitor content quality: Our unique reports help identify indexed pages that are being actively removed from Google’s search results.
📈 Add indexing data to reports - Our tool allows you to monitor the entire website or specific site sections so you can add index data as part of your KPIs.
⚙️ How does Indexing Insight work?
Indexing Insight is simple to set up and manage.
The tool is designed to help SEO teams be in complete control of which important pages they want to monitor.
Any website can start monitoring in three easy steps:
🌐 Pick a domain: Log into your Google Account and choose the domain property you want to monitor.
📄 Download URLs: Select individual XML Sitemaps or your Sitemap Index that have been submitted to GSC.
📁 Add web properties: Create URL prefix web properties based on your website’s folder structure.
3 steps to set up monitoring in Indexing Insight
That’s it! Please sit back, relax and let our tool do all the heavy lifting.
Our tool automatically optimises the limits within the Search Console API, enabling you to effectively monitor your website's Google indexing on a large scale.
But that’s not all!
Once you’ve set up your project, you can add or remove both your sitemaps and/or web properties for the project. Any changes will be taken into account in the next scheduled inspection (the next day).
So, you always remain in complete control over what pages are inspected.
Web Properties Settings in Indexing Insight
💲 What are the pricing plans?
Indexing Insight has three pricing plans:
Automate ($75/month) - For companies who want to monitor up to 100,000 URLs.
Scale ($150 /month) - For companies who want to monitor up to 500,000 URLs.
Company ($300/month) - For companies who want to monitor 1 million URLs.
🤖 What are the requirements?
Your website and Google account must meet the following requirements:
🌐 Google Search Console contains the domain property you want to monitor
Google Search Console is misreporting ‘URL is unknown to Google’.
The page indexing report in Google Search Console (GSC) misreports important historically crawled and indexed pages with the indexing state ‘URL is unknown to Google’.
It groups these pages under the ‘Discovered - currently not indexed’ report.
In this newsletter, I'll show examples of how GSC misreports the pages have changed their indexing state to ‘URL is unknown to Google’.
Let's dive in.
🌊 The hidden changes beneath the surface
Google core updates impact crawling and indexing.
However, you might miss the impact if you check your website’s indexing data in your Google Search Console > Page Indexingreport.
As you can see, nothing has changed on the surface.
But dig 1 level deeper. You can see the impact of Google core update on indexing.
If you visit the ‘Why pages aren’t indexed’ reports, you can see a decline in the ‘Crawled - currently not indexed’ and an increase in ‘Discovered - currently not indexed’.
If we look at the ‘Discovered—currently not indexed’ report, we can see that the number of pages has increased after a Google core update.
If you check the ‘crawled—currently not indexed’ report, you will see a decline in the total number of pages in this index state.
This shows that the page’s index state switched from ‘crawled - currently not indexed’ to ‘discovered - crawled currently not indexed’.
BUT that is not the most interesting part of this report.
Indexing Insight has uncovered that Google Search Console isn’t being honest about the index states of pages that get hit by the core update.
Indexing Insight reporting spike in ‘URL is unknown to Google’
We will get different results if we rerun the same analysis in Indexing Insights as we did above.
Just like Google Search Console, if we consider indexing in terms of indexed vs. unindexed, nothing much changes after a Google core update.
However, we get a very different result when we go to why pages aren’t being indexed.
Instead of a sharp increase in ‘Discovered—crawled currently not indexed’, we see a sharp rise in pages with the index state ‘URL is unknown to Google’.
Checking the ‘Discovered - currently not indexed’ report has shown that there has been an increase in the total number of pages in this report.
But not the 11,000 URLs reported in Google Search Console. Only 747 URLs are in the report.
I was shocked by the difference in reporting. I did some analysis.
The manual GSC indexing report analysis
The analysis was pretty straightforward and designed to answer a basic question:
How many URLs were reported correctly in the 1,000 sample URLs in the report?
First, I performed some manual checks.
Then, I went to the sample URL list in the ‘Discovered—crawled currentlynot indexed’ section and changed the number of URLs shown to 500. I then scrolled to the bottom of page 1 of the report and started inspecting using the URL inspection tool in GSC.
…and noticed that when you check the page with the URL Inspection tool, it shows the index state as ‘URL is unknown to Google’.
I did this 10 times from the bottom of the page to the top and inspected random URLs. They all returned with the same result: ‘URL is unknown to Google.
I then reversed the order in which I inspected URLs. And started at the top of the report and worked my way down (starting with the 1st result).
The result was different. Pages reported as being ‘Discovered - crawled currently not indexed’.
Something was happening, so I downloaded all the sample URLs and compared them to the indexing state found in Indexing Insight.
Random manual checks showed that there was misreporting in the Google Search Console.
So, I did more investigating.
Google Search Console misreporting data
Next, I conducted a simple comparison between the page states reported in GSC vs Indexing Insight.
I found that 94% of the index states are being misreported:
After a Google core update, I found that 94% of page indexing states are being misreported as ‘Discovered - crawled currently not indexed’ instead of ‘URL is unknown to Google’.
The sheer volume of URLs that were being misreported was staggering to me.
Over 90% of the pages in the ‘Discovered—crawled currently not indexed’ category are being misreported.
The question I asked myself is why?
⁉️ Why is GSC misreporting the data?
This misreporting is by design.
You might argue that it’s because of the page indexing delay. But the number of affected pages in the report graph in the ‘Discovered - currently not indexed’ is increasing week-by-week over 30-40 days.
Indicating the misreporting is done by design.
In the GSC backend, a rule does not show the report ‘URL is unknown to Google’ if those pages were previously crawled and indexed.
This is relatively simple for Google engineers to execute because we do something similar with ‘Crawled - previously indexed’ in Indexing Insight. And we only have 1 developer.
For Google to change the reporting rules, it should be easy peasy.
Instead, Google Search Console groups pages with the index states ‘URL is unknown toGoogle’ and ‘Discovered—currently not indexed’ together and shows sample URLs of both states in the report.
Why would their team do this?
I have a couple of theories, but the main one is that Google wants people to avoid thinking toohard about crawling and indexing. Remember, Google Search Console is designed for the averageuser. It’s not meant to be a deep technical analysis tool.
So, they will prioritise UX over technical reporting.
This is why they group historic pages with the index state ‘URL is unknown to Google’ under the ‘Discovered—currently not indexed’ report. Fewer reports mean fewer headaches (and questions).
Or it’s a bug. And the Google Search Console team will eventually fix it after it deals with other priorities.
Who really knows (outside Google)?
🤷 Why does this misreporting matter?
The change in index state indicates that Google is actively deprioritising the crawl priority of your pages, especially when Google core updates are rolled out.
But because there is no ‘URL is unknown to Google’ report, you are unaware of the change.
In a previous newsletter, How Index States Indicate Crawl Priority, I showed how the page indexing states could be reversed and how this can be mapped to crawl priority within Googlebot.
And ‘URL is unknown to Google’ is the lowest priority.
In another newsletter, What is ‘URL is unknown to Google’? I proved that pages within the ‘URL is unknown to Google’ index state have been previously crawled and indexed.
Update 27/01/2025: I updated the article based on Gary Illyes comments. Google can “forget” URLs as they purge low-value pages from their index over time.
To Googlebot they have not seen that URL before because of the signals gathered over time or lack of signals. So to Googlebot a historic URL can be “unknown” because it was so forgettable.
This means two types of ‘URL is unknown to Google’ exist:
URL is unknown to Google - The URL has never been discovered or crawled by Googlebot.
URL is forgotten by Google - The URL was previously crawled and indexed by Google but has been forgotten.
Google core updates don’t just impact your rankings. They can also cause your pages to be removed from the index or deprioritise the crawl priority of your not indexed pages (changing the index state).
Why am I hammering home these three points?
Because each of these newsletters helps us build a picture of how the misreporting stacks:
🚨Previously indexed pages - Pages with the index state ‘URL is Unknown to Google’ that have been historically crawled and indexed by Google are forgotten.
🚨Google core updates impact indexing states - The Google core updates can cause your indexed pages to turn into not indexed pages. And your not indexed pages to change indexing state (and crawl priority).
🚨Grouped under ‘Discovered - currently not indexed’ - Previously crawled and indexed pages with the ‘URL is unknown to Google’ are grouped under the ‘Discovered - currently not indexed’ report.
All of this misreporting means that when you analyse your website in GSC, you might be led to believe your website has never been indexed. That it has a discovery and crawling problem.
This assumption is easy to make. But wrong.
This is why it is important to understand the difference between the different indexing states and be able to see historic indexing trends.
Your important submitted pages are likely being actively removed or deprioritised by Google’s index.
🤓 What does this mean for you (as an SEO)?
As an SEO, you need to be able to spot misreporting in the page indexing report.
The good news is that it’s relatively easy to spot misreporting in Google Search Console for important pages. However, the data you can download from the tool is limited.
Let me show you an example of finding ‘URL is unknown to Google’ pages in GSC.
Step 1: Filter on the submitted pages in the page indexing report
Go to the page indexing report in Google Search Console and filter on the submitted pages using XML sitemaps.
Step 2: Sort on pages in the ‘Why pages aren’t allowed’ section of the page indexing report
Scroll down to the bottom of the report and sort the pages by the largest number of URLs.
You should see the trend of total pages within each report. And if the total number of pages is increasing or decreasing.
Step 3: Go to the ‘Discovery - currently not indexed’ report and change rows per page to 500
Visit the ‘Discovered - currently not indexed’ report and scroll to the table of URLs. And change the total row from 10 to 500.
Step 4: Inspect the bottom pages in the list of URLs in the report
Then start inspecting the URLs at the bottom of the table.
When inspecting the pages using the URL inspection tool, you want to look for the indexing state ‘URL is unknown to Google’.
If you see a lot of pages with ‘URL is unknown to Google’, move into the final step.
Step 5: Compare the data in the Search Console and URL Inspection API
Finally, you need to download the sample list of URLs and compare them to the URL inspection API.
Then, crawl the URLs using the list mode in the tool
Once the crawl is complete, you must compare the indexing states from the URL Inspection API with the page indexing report. You’re looking for the % difference between the indexing states.
For example, 44% of the pages we’re using in this example in the ‘Discovery - currently not indexed’ are actually ‘URL is unknown to Google’.
The problem is that if you want to find pages at scale, Google only allows you to download 1,000 URLs from any report. And you need to do this analysis manually.
But not with Indexing Insight.
Indexing Insight allows you to find pages that Google has actively deprioritised and moved into the ‘URL is unknown to Google’ report by monitoring Google indexing at scale. And you download all of this data.
So, you can focus on actioning the data rather than having to stitch it together.
📌 Summary
‘URL is unknown to Google’ is being misreported in Google Search Console.
In this newsletter, we’ve discussed how Google Search Console groups pages with the ‘URL is unknown to Google’ index state under the ‘Discovered - currently not indexed’.
This happens even when Google has previously crawled and indexed the pages.
Finally, we’ve reviewed a simple technique for identifying ‘URL is unknown to Google’ pages within the ‘Discovered - currently not indexed’ report.
📊 What is Indexing Insight?
Indexing Insight is a B2B SaaS tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Google ranking updates don’t just impact rankings.
Instead, the system-wide updates actively cause Google’s systems to reprioritise what is worth crawling and indexing.
In this newsletter, I'll explain how the Google core updates impact the priority of pages that Google crawls and indexes. And show you examples of this happening in the wild.
I will provide evidence that Google updates impact crawling and indexing.
Let's dive in.
🔄 What are Google Core updates?
Google core updates are significant system-wide changes that Google teams make to the search ranking algorithms and systems.
In the second example, the publishing website is not as big, with less than 10,000 pages.
However, what is interesting is that at the end of the core update in December, the number of ‘crawled - previously indexed’ pages started to increase.
The website has had 500 indexed pages actively removed by Google’s index.
#2 Google core updates purge URLs from the index
A Google Core update can cause the indexing system to actively ‘forget’ URLs.
It seems that Google core updates delete the crawl priority of not indexed pages, especially for websites that have seen pages actively removed from Google’s index.
For example, a programmatic SEO website using Indexing Insight to monitor pages.
Since the Google core update, this website has seen not indexed pages moved from ‘crawled—not currently indexed’ to ‘URL is unknown to Google’.
Going from 5,000 pages to 10,000 pages in 30 days. After the Dec-24 core update.
A comment from Gary Illyes on LinkedIn mentions that URLs with the ‘URL is unknown to Google’ have zero priority to Googlebot.
Gary mentions that URLs can move between states as Google collects signals about a set of URLs. Over time, Google may forget a page and make it ‘unknown’.
A Google core update might actively cause the index to ‘forget’ the URL.
🧪 Evidence that Google updates impact indexing
The short answer is yes.
Research suggests that Google updates to its systems does impact indexing. And there are three big pieces of evidence to support this idea:
As you can see in the graph from the study below, search engine indexes don’t show monotonic growth. Instead, the index size is highly variable due to constant system updates.
However, this study was done in 2015. And A LOT has happened since then.
These system and core ranking updates will impact the number of pages indexed in Google.
Google constantly fine-tunes its algorithm and index to ensure its users are served high-quality pages. The definition of high quality is up for interpretation, but this is Google’s goal.
🚮 Google patent describing how Google manages indexing
A Google patent titled ‘Managing URLs’ describes how Google might manage pages in its index.
The US patent describes using ‘importance thresholds’ to handle the trillions of crawled and indexed pages that commercial search engines will handle daily.
Why?
The patent describes how search engines have a finite number of pages that can be indexed.
Interestingly, this patent describes how a search engine like Google uses dynamic importance threshold scores for each URL to determine whether it should be crawled or indexed.
Importance threshold mechanism from Google Patent Managing URLs
This process of defining the importance of each URL is continuous.
The importance thresholds help search engines, like Google, keep their indexes as high-quality as possible. Based on the importance threshold, pages are added to and removed from the index.
If new pages have a higher importance score, and there is no more space to store indexed pages, then old pages will be removed.
Note: I will write more about this patent in a future newsletter, as I am not doing nearly enough justice in this one.
🗣 Googlers confirm pages can be suddenly removed
The final piece of evidence is from the Googlers themselves.
Gary Illyes, on Twitter, has said that ‘index selection’ is tied to the quality of the content. If there is more space in the index, low-quality content will be indexed.
This comment backs up the idea of an ‘importance threshold’ score described in the patent above.
Gary also said this in an interview at the SERP Conference. He talks explicitly about how Google is deindexing a lot of URLs due to the quality of the website:
“Since February, where suddenly we just decided that we are de-indexing a vast amount of URLs on a site just because the perception, or our perception of the site has changed. And in general, also the the general quality of the site, that can matter a lot of how many of these crawled but not indexed, you see in Search Console. If the number of these URLs is very high that could hint at a general quality issues.”
When Google updates its system, the number of indexed pages is impacted.
How Google updates impact crawling & indexing
Based on this evidence, it becomes obvious Google core updates impact indexing.
When Google rolls out a system or core ranking algorithm update, it must impact the ‘importance threshold’, determining whether a page is indexed.
This is why we are seeing pages actively removed from Google’s index.
However, Google core updates impact more than whether a URL is indexed. They also impact the crawl priority of your URLs. And whether the index ‘forgets’ your URLs.
So a URL can move from ‘crawled - currently not indexed’ to ‘URL is unknown to Google’.
The patent supports this, describing how the importance threshold impact whether a page is prioritised for recrawling or a new URL is crawled.
It’s important to remember three things from this post:
Google core ranking updates don’t just impact rankings
Google core updates can actively remove pages from the index
Google core updates can deprioritise the crawling of your important pages
When assessing whether a Google core update has impacted your website, don’t just look at your Search Analytics or third-party visibility graphs. Also, examine your page indexing report.
Why?
Because even though you might see a recovery or decline for your website after an update…
…it doesn’t mean the update hasn’t caused Google to deprioritise your not indexed pages as less of a priority to crawl. And it indicates bigger quality issues on the site.
If you want to analyse to see the impact of an update on your website, all you have to do is follow this quick process:
Go to the page indexing report
Filter on ‘All submitted pages’ (need to have XML Sitemaps submitted)
Scroll down to the ‘Why page aren’t indexed’
Sort by pages on the far right of the table
Check to see if you have seen an increase in ‘Crawed - currently not indexed’ pages
Check to see if you have seen an increase in Discovered - currently not indexed’ pages
Do you see an increase in the number of pages in these reports after a core update?
Yes?
There is a high chance that Google’s indexing systems are:
Actively removing your important pages from the index.
Actively deprioritising your important pages to be crawled by Googlebot.
Google core updates impact the crawling and indexing of your pages.
In this newsletter, we’ve discussed how Google core updates and system changes can impact the number of pages indexed by Google. Indexing Insight has provided examples of core updates actively removing pages from Google’s index.
We’ve looked at evidence to support the idea that updates impact crawling and indexing.
Finally, we’ve reviewed a simple technique for identifying indexed and non-indexed pages impacted by Google updates in the Google Search Console.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Google Search Console is misreporting ‘URL is unknown to Google’.
URL Inspection tool is the authority source for indexing data.
One problem many SEO professionals face is conflicting indexing states between page indexing reports and the URL inspection tool in Google Search Console.
This is caused due to the indexing refresh rates in the reports.
In this newsletter, I'll explain the difference between the report refresh rates and why SEOs need to understand the difference.
So, let's dive in.
🔄 What is the URL Inspection Tool?
The URL Inspection tool pulls live information from Google’s index about a single page URL. It allows you to test if a page URL is indexed or not indexed.
It provides a top-level summary of the pages that have been indexed and not indexed over the last 90 days. And a link to a report for the indexed pages.
Indexed and Not Indexed Graph Over Time
It also lists reasons why Google has not indexed page URLs that have been crawled. These reasons are called index coverage states.
Index Coverage State reports
When you click on a reason (index coverage state), you are taken to a report showing you the affected pages over time and the list of 1,000 sample URLs.
Page Indexing > Index Coverage Report (‘Craweled - currently not indexed’)
⁉️ What is the Difference in the Indexing Data?
The biggest difference is how often indexing states are refresh rates:
📊 Page indexing report updates twice a week.
🔍 URL Inspection tool updates daily.
📊 Page Indexing Report Refreshes Twice a Week
This Google indexing data source updates twice a week.
The report refreshes the indexing data in the timeline graph on Sundays and Wednesdays during the week.
Page indexing report updates on a Wednesday and Sunday
This happens for both Indexed and Not Indexed reports. Even the individual indexing state reports (e.g. ‘Crawled - currently not indexed’).
Index state reports updated twice a week: Sunday and Wednesday
🔍 URL Inspection Tool
The index data refresh rate in the URL Inspection tool is more recent.
In Indexing Insights, we use the URL Inspection API to monitor page URL indexing states and can see the indexing state daily.
You can see the change in Indexed and Not Indexed states for page URLs over 90 days. These states change daily (rather than twice a week).
The refresh rate being more authoritative was confirmed by the Google Search Central team when the URL Inspection Tool and API in 2021.
John Mueller also confirmed this in 2018 on Twitter (by me, and I forgot I asked this question).
The URL Inspection tool is the authority indexing data source.
The Google Search Central team confirmed that the URL Inspection Tool is the most recent and up-to-date data source for an indexing state. And should be considered authoritative when in conflict.
Indexing Insight uses the URL Inspection API (the most authoritative data source).
Our tool checks your page's indexing status daily, helping you identify any changes straight from Google’s own data warehouse.
Indexing Insight monitors daily using an authoritative indexing source
📌 Summary
There is a difference in indexing refresh rates in reports.
In this newsletter, I’ve provided evidence that the URL Inspection tool is the most authoritative indexing data source. It refreshes much faster than the page indexing report in Google Search Console.
Indexing Insights uses the URL Inspection API to monitor indexing daily.
This allows our tool to refresh the page indexing data much faster than Google Search Console. And pull updated information straight from Google’s data warehouse about your pages.
Hopefully, this has helped clarify why you might see a difference between the page indexing report and the URL Inspection tool.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Google Search Console is misreporting ‘URL is unknown to Google’.
The coverage state ‘URL is unknown to Google’ indicates to SEO teams that Google has never seen this page before.
However, this definition is misleading.
In this newsletter, I'll explain the current definition of ‘URL is unknown to Google’ and why it needs to change.
I'll explain why we need two definitions using examples from Indexing Insight data.
So, let's dive in.
Update 27/01/2025:: I updated the article based on Gary Illyes comments. It seems that Google can “forget” URLs as they purge low-value pages from their index over time.
🕷️ What is ‘URL is unknown to Google’?
‘URL is unknown to Google’ is a page indexing coverage state in Google’s Search Console.
If you do a Google search for ‘URL is unknown to Google’, many articles define this state as Google’s crawlers having never seen this URL before. Ever.
All of these definitions are just repeating the official definition from Google’s documentation:
“If the label is URL is unknown to Google, it means that Google hasn't seen that URL before, so you should request that the page be indexed. Indexing typically takes a few days.”
However, based on the data on Indexing Insights, this definition needs to change.
Update 27/01/2025: It seemsthat Googlebot’s systems can “forget” a URL that was previously crawled and indexed over time as they gather more signals. So the definition is strictly correct.
To Googlebot they have not seen that URL before because it was so forgettable.
❓ Why does the definition need to change?
Data from Indexing Insight shows that ‘URL is unknown to Google’ definition is inaccurate.
Based on our data, Google has seen pages labelled ‘URL is unknown to Google’. In some cases, Google has historically crawled and indexed these URLs.
The problem is that indexing data in the URL Inspection Tool isn’t giving you all the data.
↔️ Index coverage states change (constantly)
It’s important to understand that coverage states for pages are constantly changing.
Active removal - Google actively removes URLs from being displayed in its search results (Submitted and indexed > Crawled - currently not indexed)
Index States Change - When URLs are removed from being served in Google Search results, their coverage state changes based on their crawl priority in Googlebot.
Reversal - But any change isn’t static. The coverage state can reverse over time.
The ‘URL is unknown to Google’ ends this process.
A URL with an “unknown” coverage state indicates zero crawl priority in Googlebot’s crawling process. You want to avoid this state.
Let’s look at examples of indexed URLs moving to ‘URL is unknown to Google’.
🎨 Examples of “unknown” URLs to Google
Let’s look at a few examples of URLs marked as ‘URL is unknown to Google’.
Example #1 - The SEO Sprint newsletter
The first example is from The SEO Sprint website.
If we test the following URL /p/product-engineering-wisdom-27 in the URL Inspection Too, we can see that it shows the coverage state ‘URL us unknown to Google’.
However, if we check the URL in the URL Inspection API, we can see that Google has, in fact, crawled it.
Interestingly, the URL historically also had the indexing state ‘crawled - currently not indexed’ in Google Search Console. This can be tracked in Indexing Insights.
This historical data provides evidence that Google definitely saw this URL.
Example #2 - Programmatic SEO website
The second example is from a programmatic SEO website.
If we test the /cities/banbury/ page using the URL Inspection tool. It gives the coverage state “URL is unknown to Google’.
However, if we check the URL with the URL Inspection API, it gives you a Last Crawl Time.
What is even more interesting is that this URL was historically indexed on June 13, 2024, and its canonical URL was dropped (changed) on October 14, 2024.
All of this historical data provides evidence that Google definitely saw this URL.
Indexing Insights provides links to the historic URL Inspection Tool in Search Console. So, you can double-check historic changes in indexing states.
Again, this data shows that Google has definitely seen this URL before.
📈 How often does this happen?
It happens a lot more than you think.
For one alpha tester monitoring 1 million URLs, the state “URL is unknown to Google” accounts for 16% of the total URLs being inspected.
In fact, when writing this newsletter, the ‘URL is unknown to Google’ is increasing…
…which is being caused by a decrease in ‘crawled - previously indexed’ submitted pages.
The increase in the number of ‘URL is unknown to Google’ and the decrease in ‘crawled—previously indexed’ indicates that Google has seen these URLs before.
🔎 How can you tell if Google has seen a URL before in GSC?
The URL Inspection API is the only way to check if Google has seen the URL.
For example, a pSEO website has over 4,900 URLs with the coverage state ‘URL is unknown to Google’...
…but when checking the web property /streets/, you can see the ‘URL is unknown to Google’ coverage state is nowhere to be found.
The only way to check if a page with the state ‘URL is unknown to Google’ has been seen before is to:
Know the URL already exists (e.g. XML Sitemap)
Inspect the URL using the URL Inspection API
Identify if the URL has a last crawl date.
For example, if you try to check for indexing data in Search Console using the URL Inspection tool, it doesn’t show you any data for ‘URL is unknown to Google’.
BUT if you check the same URL using the URL Inspection API, It provides you with the Last Crawl date. And this indicates that Google has seen the URL before.
📚 Definition of ‘URL is unknown to Google’ Needs to change
The definition of ‘URL is unknown to Google’ is misleading and needs to change.
URL is unknown to Google - The URL has never been discovered or crawled by Googlebot.
URL is forgotten by Google - The URL was previously crawled and indexed by Google but has been forgotten.
The Indexing Insight data from the URL inspection API shows that Google has seen many submitted URLs before with the coverage state ‘URL is unknown to Google’.
If historically crawled and indexed pages have this state, it is a sign that a URL has experienced reverse indexing over the last 90 - 180 days.
And it is a very low priority to crawl in Google’s crawling system.
📌Summary
The current definition of ‘URL is unknown to Google’ is misleading.
In this newsletter, I’ve provided evidence that just because a page has this state in GSC does not mean Google has never crawled or indexed the URL.
Quite the opposite.
By using Indexing Insight data, we can see that important traffic-driving pages are experiencing reverse indexing. And URLs with the state ‘URL is unknown to Google’ have the least crawl priority in Google’s systems.
The problem is that you can’t detect these problem pages in Search Console.
Hopefully, this newsletter has inspired you to use the URL Inspection API to identify important pages with the ‘URL is unknown to Google’ coverage state.
A page with this coverage state strongly indicates that it is becoming less of a priority for crawling, indexing, and ranking in Google Search.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Google Search Console is misreporting ‘URL is unknown to Google’.
Every SEO team uses the coverage states in Google Search Console to debug crawling and indexing issues in Google Search.
However, Google can actively reverse index coverage states.
In this newsletter, I'll explain how index coverage states can be reversed. And how these states can tell us the level of crawl priority in Google’s system by mapping them to Googlebot’s crawl, render and index process.
I'll explain reverse indexing coverage states using examples from Indexing Insight.
Let's dive in.
Update: I’ve updated the article due to comments from Gary Illye.
🚦 What is the coverage state?
Every page in the Search Console’s Page Indexing report has a coverage state.
The coverage state of a page is why a page is either indexed or not indexed (e.g. ‘crawled - currently not indexed’ and ‘submitted and indexed’).
You can see the coverage state in the Page Indexing report under the Reasons category…
The most fascinating thing about the page’s coverage state is that it’s constantly changing.
BUT you can’t usually detect these changes in Google Search Console because they don’t track historic changes in a page’s coverage state.
However, we can detect these changes with Indexing Insight.
For example, we track any change in the coverage state of page URLs being monitored and any changes in the canonical URL.
We also email users daily to update them on any changes we’ve found.
These emails are always interesting. You can see pages move between the different index coverage states.
Tracking changes over millions of URLs for our alpha testers led us to a surprising conclusion.
A page’s indexing coverage state can go backwards from being submitted and indexed to Google, telling you that the URL is “unknown”.
For example, a typical page usually goes through the following steps:
⬇️ ‘URL is unknown to Google’
⬇️ ‘Discovered - currently not indexed’
⬇️ ‘Crawled - currently not indexed’
✅ ‘Submitted and indexed’
But over time, the same page coverage state can go backwards from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Discovered - currently not indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’
Let’s look at some examples to understand page coverage states going backwards in the wild.
Examples of Coverage States Going Backward
Below are 3 examples of a page’s coverage status reversing.
Example #1 - The SEO Sprint
The first example is from The SEO Sprint.
The current coverage state in the URL Inspection tool is ‘URL is unknown to Google’.
However,using the URL report in Indexing Insight, we can see that this particular URL was indexed and had its Google-selected canonical URL.
The Google-selected canonical change happened on the 15th of August, 2024. We even provide a link to a historic URL Inspection tool in Google Search Console.
The change in the canonical links indicates that Google dropped the data from its index.
When you open the link, you can see that historically, this page had a ‘crawled - currently not indexed’ coverage state.
If we look at the page's search performance, we can see that it had 18 impressions in March 2024. This indicates that this page was indexed and served in search results.
This page URL reverse index state went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’
This page URL indexing state reversed, and the URL coverage state “went backwards”.
Example #2 - Programmatic SEO website
The second example is a programmatic SEO website.
In this example you can see the /cities/banbury/ URL is shown as URL is not on Google.
However, when checking the page's history in the URL report, we can see historic changes. The page was indexed (13th June 2024), and there were changes to the canonical URL (14th October 2024).
If we check the link to Search Console, we can see that the page has the coverage state of ‘crawled - currently not indexed’.
If we check the Search Performance of the page URL over the last 16 months we can see that this page was indexed. And it was served to users (which is why it has impressions).
Again, this page URL reverse index state went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘URL is unknown to Google’ (current state in the URL Inspection tool)
Like the previous example, this page's URL indexing state reversed, and the URL coverage state “went backwards”.
Example #3 - Niche Website
The final example is a niche cricket website.
If we input the page /players/niaz-khan/ into the URL Inspection tool, the current coverage state is ‘Discovered - currently not indexed’.
However, using Indexing Insights, we track any changes in a page's index state. As you can see, this particular URL was indexed on May 31st, 2024, and the canonical URL changed on October 9th, 2024.
If we open the historic URL Inspection report for when the canonical URL changed (9th October 2024), this page will have a ‘crawled - currently not indexed’ coverage state.
Finally, if we look at the performance over the last 16 months, we can see that the page has had impressions and clicks.
This indicates that Google indexed this page and showed it in its search results.
To recap, this cricket niche website page URL index state reversed and went from:
⬇️ ‘Submitted and indexed’
⬇️ ‘Crawled - currently not indexed’
❌ ‘Discovered - currently not indexed’ (current state in the URL Inspection tool)
Like the other examples this page URL indexing state reversed, and the URL coverage state “went backwards”.
❓ Why are index coverage states reversing?
A page’s Indexing state can change based on historical data about the page.
The video focuses on the ‘Discovered - currently not indexed’ state in Search Console.
In the video, Martin explains that one of the most common reasons pages are in the ‘Discovered - currently not indexed’ category is that they have been activelyremovedfrom its index.
To quote the video:
“The other far more common reason for pages staying in "Discovered-- currently not indexed" is quality, though. When Google Search notices a pattern of low-quality or thin content on pages, they might be removed from the index and might stay in Discovered.”
It also confirms Google actively removes indexed content from its index AND when it is removed the coverage state changes.
But how do other coverage states work in Google’s crawling and indexing system?
That is what I set out to figure out.
⚙️ Googlebot System vs Coverage States
There is a lot of literature to choose from to explain crawling and indexing.
However, rather than trying to map the coverage states to years of in-depth documentation. I think it’s better to map the index coverage states to a simple diagram widely used by the SEO industry.
Luckily, I didn’t have to do much digging. Martin Splitt provided a Crawl, Render and Index diagram in the Help! Google Search isn’t indexing my pages YouTube video:
Based on the reverse coverage state examples I’d seen (and just shown), this diagram gave me an idea.
So, I asked Martin on Linkedin if the indexing status in Google Search Console could be mapped to the simple process he presented (source).
Martin confirmed that this was an accurate mapping to his knowledge.
Gary Illyes also confirmed on LinkedIn that URLs move between index states as they collect signals over time.
The confirmation from Martin and Gary was the final piece of the puzzle. It helped develop a theory on how the index coverage states map to the crawling and indexing system.
It’s all about how Google’s system prioritises the URLs to be crawled.
Below is a simple diagram of the crawling and indexing system mapped to the index coverage states.
The diagram is based on Martin's confirmation on LinkedIn and the Crawl, Render, and Index diagram from the Understand the JavaScript SEO basics documentation.
As you can see, certain index coverage states reflect less of a priority for Google.
The less “importance” a page URL is allocated over time, the more it moves backwards through the crawling and indexing process. And the more the indexing coverage state changes over time.
Until it reaches, the ‘URL is unknown to Google’ indexing state.
A URL can be so forgetful that Google’s systems can forget it exists. And a previously crawled or indexed page with this state has zero crawl priority.
To quote Gary Illyes when I asked him about historically crawled and indexed pages with the ‘URL is unknown to Google’:
“Those have no priority; they are not known to Google (Search) so inherently they have no priority whatsoever. URLs move between states as we collect signals for them, and in this particular case the signals told a story that made our systems "forget" that URL exists.”
Google is actively removing pages from being displayed in its search results.
When pages are removed from Google’s index, the index coverage state changes based on the URL's priority in the Googlebot web crawling process.
But any change isn’t static. The coverage state can reverse over time.
What is interesting is that pages can become less important to crawl.
The index coverage states like ‘Discovered - currently not indexed’ and ‘URL is Unknown to Google’ for historically indexed pages are strong indicators that Google actively finds these pages low-quality.
How often does reverse indexing occur?
It happens more often than you think.
For one alpha tester, 32% of their 1 million submitted URLs have experienced reverse indexing over the last 90 days.
They can see that historical URLs are slowly being removed from Google’s serving index. And as more time passes the state is changing to be moved to other indexing states…
…which reflects the crawl priority in Google’s crawling system.
They can see the slow increase of coverage states ‘discovered - currently not indexed’ as the number of ‘crawled - previously indexed’ declines.
They are also seeing an increase in ‘URL is unknown to Google’ as important URLs become less of a crawl priority to Googlebot.
They are watching Googlebots crawl system deprioritizing URLs to be crawled.
🕵️ How to detect reverse index coverage in GSC
The coverage states in the page indexing report indicate levels of crawl prioritisation.
SEO teams can use the Search Console index coverage report to identify which important pages they want to rank are being actively removed by Google.
How can you find out?
Filter on the important pages you want to rank in Google Search.
In Google Search Console, go to Page Indexing > All Submitted Pages. This will provide you with a clearer picture of the pages that you want to rank in Google Search.
Do you see ‘crawled - currently not indexed’ or ‘discovered - currently not indexed’?
Then, it’s highly likely your pages are experiencing reverse index coverage states.
If you find ‘crawled - currently not indexed’ or ‘discovered - currently not indexed’ with this filter, it means:
❌ Google is removing pages - These pages will be actively removed from Google’s search results due to the quality or popularity of your pages/website.
🕷️ Less of a crawl priority - Any pages under ‘discovered - currently not indexed’ also indicate that these URLs are less of a priority to crawl and rank in Google Search.
🚦 Pages need action - The pages in the ‘discovered - currently not indexed’ category might need urgent action before disappearing into ‘URL is Unknown to Google’.
If nearly all your pages submitted are in these two categories, then it's a strong indication that your website is less of a priority to crawl, index, and rank in Google.
📌 Summary
The coverage states of your pages in the Page Indexing report are not static.
In this newsletter, I’ve provided evidence that Google will actively remove pages from its search results. AND that the coverage states of your pages can go backwards.
This reverse in index coverage state indicates low crawl priority in Googlebot’s system.
If we map the index coverage states to Googlebot’s crawl, render and index process we can see that pages in the ‘URL is Unknown to Google’ and ‘discovered - currently not indexed’ are less of a priority to crawl.
This is a problem because crawl priority indicates a page's ability to rank in Google.
Hopefully, this newsletter has inspired you to look at your page indexing report with a new understanding. And identify which pages are less of a priority for Google to crawl and index.
If you have any questions, please leave them in the comments below 👇.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
Google Search Console is misreporting ‘URL is unknown to Google’.
I’ve been using the ‘crawled - currently not indexed’ report in Google Search Console for quite a while to identify opportunities to drive business growth.
However, the definition of ‘crawled - currently not indexed’ needs to change.
In this newsletter, I'll explain the current definition of ‘crawled - currently not indexed’ and propose a new indexing status, ‘crawled - previously indexed’.
I'll explain why we need a new definition using examples from Indexing Insight data.
So, let's dive in.
🕷️ What is ‘crawled - currently not indexed’?
The current definition of ‘crawled - currently not indexed’ is misleading.
Based on the data on Indexing Insights, I think this definition needs to change.
❓Why does the definition need to change?
First-party data from Indexing Insight shows that the current definition isn’t accurate.
Based on our data, most pages in the ‘crawled - currently not indexed’ report have been crawled AND historically indexed by Google.
It’s just that the report isn’t clear. Let’s take a look at some examples.
🎨 Examples of historically indexed pages
Here are examples of historically indexed pages in the ‘crawled - currently not indexed’ report in GSC.
Example #1 - theseosprint.com
I’ll start by showing an example from theseosprint.com.
The SEO Sprint 2022 Review piece of content was not designed to rank for any particular keywords in Google. And it was published Dec 01, 2022 (almost 2 years ago).
When checking the URL Inspection tool in GSC, we see it has the ‘crawled—currently not indexed’ index status.
BUT this page URL WAS indexed in Google.
Thanks to the Index Insight (the Google index monitoring tool) we track if a page was historically indexed in Google. And we even provide the exact date it switch from ‘submitted and indexed’ to ‘crawled - currently not indexed’ (20th August 2024).
Don’t just take our word for it.
We even link to your GSC account's historic URL Inspection report on the switch date. The screenshot below shows that this page was indexed.
Finally, if we check this URL's Search performance, we can see that it had impressions and clicks in Google Search. Again, this shows that it was indexed and could appear in Google Search results.
Example #2 - Programmatic SEO website
The following example is from a programmatic SEO website with 20K pages.
If you were to check the page URL in the URL Inspection report you can see that it is reporting ‘crawled - currently not indexed’.
Again, with Indexing Insight we monitor when a page switches from indexed to not indexed. And the date it switched. In this case, it was 12th August 2024.
We provide the link to the historic URL Inspection report in GSC account. Which shows that the page was indexed in Google.
Finally, by checking the Search Performance report and filtering for the exact URL, you can see that it drove clicks and impressions, showing that it was indexed and could appear in search results.
Example #3 - Niche website
The final example is from a niche website with almost 10K pages.
Again, I don’t want to show the website's domain name, but I will try to show part of the URL so you can see that it’s the same page being tested.
As you can see below, the URL Inspection status for the /alfreton-cricket-club/ is ‘crawled - currently not indexed’.
When checking the historic indexing status in Indexing Insight, we can see that this page was indexed and last indexed on July 23rd 2024.
We can confirm the page was indexed by opening up the historic URL Inspection report.
The /alfreton-cricket-club/ also has impressions when checking the Search Analytics.
Again, just like the other URLs tested, a page can only get impressions if it appears in Google Search results. This means that the page needed to have been indexed to be shown to users at some point.
📈 How often does this happen in GSC?
Based on our data from Indexing Insight, this happens more than you think.
For example, when testing pages submitted via XML sitemaps from alpha testers, 70-80% of pages with the ‘crawled — currently not indexed’ status in GSC had been historically indexed.
The problem of “backward” indexing was so frequent that we had to create a new indexing status in the tool to understand how often Google removed pages from being served in search results.
This new page status is called ‘crawled - previously indexed’.
When rolling out this new report, our team was surprised at the results and the sheer scale of this new status.
For example, for one alpha tester, there are almost 130,000 pages with the ‘crawled - previously indexed’ status.
This means 13% of the pages we’re monitoring for this site have been actively removed from being served in search results by Google’s indexing system.
This indicates a BIG issue with the website’s content.
🕵️ Two Types of ‘crawled - currently not indexed’
Based on our experience and data, a new definition of ‘crawled - currently not indexed’ is needed.
The definition should be split into two categories:
Crawled - currently not indexed: Pages that have been crawled but never been indexed by Google.
Crawled - previously indexed: Pages that have been crawled AND historically indexed, but Google recently stopped serving the content in its search results.
#1 - Crawled - currently not indexed
The traditional definition of ‘crawled - currently not indexed’ pages.
“Pages with the traditional ‘crawled - currently not indexed’ status have been crawled BUT not indexed by Google. For whatever reason, the system has not decided to index it.
Google can decide to index or not index these pages in the future.”
Here are a few characteristics of pages that fall under this indexing status:
Never been indexed - Page URLs with this status have never been historically indexed by Google and shown in search results.
Zero search performance - Page URLs with this status have never appeared in Google Search and have no impressions or clicks over the last 16 months.
Canonicalized URLs - There are URLs that have been crawled but have been canonicalized by the user to a canonical URL.
Non-HTML URLs - When crawled, Google detected that the content type is not HTML, and its system knows not to index these pages in web search.
Low-quality content - Page URLs submitted to Google were so low-quality or thin that they didn’t make it through Google’s indexing pipeline.
#2 - Crawled - previously indexed
A new definition for pages with the ‘crawled -currently not indexed’ status:
“Pages with the new ‘crawled - previously indexed’ status have been crawled AND historically indexed by Google.
However, over time, Google has decided that these pages should not be served to users and removes them from being served in search results.”
Here are a few characteristics of pages that fall under this indexing status:
Submitted and indexed - Page URLs are typically important SEO traffic-driving pages that site owners want to rank in Google Search.
Historically indexed - Page URLs with this status have been historically crawled AND indexed by Google. And have been shown in search results.
Search performance - Page URLs with this status have appeared in Google Search and have had impressions and/or clicks over the last 16 months.
🤷 What does this new definition mean for SEOs?
Ensure you don’t take ‘crawled - currently not indexed’ literally.
When working on websites with a large number of ‘crawled - currently not indexed’ pages in Search Console, do not be fooled into thinking that Google has never indexed these pages.
There is a high probability that Google has chosen to deindex the pages in this report.
You can easily check which pages have a high chance of being ‘crawled - previously indexed’ if you have XML Sitemaps submitted to GSC. Then filter on “All submitted pages” in the Page Indexing report:
Unfortunately, the index removal could have happened 12 months or 12 days ago.
The exact date the pages were removed from Google’s index in Search Console is not known. If you use the URL Inspection tool it will just give you the current status.
But there are clear indications that pages were indexed.
You can use the Search Analytics report or API to determine if the page had clicks and impressions over the last 12-16 months.
Even a tiny amount of performance shows that Google indexed the page at some point.
📌 Summary
The current definition of ‘crawled - currently not indexed’ is misleading.
In this newsletter, I’ve provided evidence that just because a page has this status in GSC does not mean that it was never indexed. In fact, quite the opposite.
A new indexing status needs to be created: ‘Crawled - previously indexed’.
At Indexing Insight, we automatically tag any pages that move from ‘submitted and indexed’ to ‘crawled - currently not indexed’ and enter this new status.
But I’ve also shown you can easily do the same in Google Search Console.
Hopefully, this newsletter has inspired you to dig deeper into ‘crawled - currently not indexed’ reports. And identify which pages have been ‘crawled - previously indexed’.
📊 What is Indexing Insight?
Indexing Insight is a tool designed to help you monitor Google indexing at scale. It’s for websites with 100K—1 million pages.
A lot of the insights in this newsletter are based on building this tool.
Subscribe to learn more about Google indexing and future tool announcements.
I’ve been fascinated by a particular problem: Monitoring Google indexing at scale.
Google indexing has become a growing problem over the years. Many companies and website owners find indexing pages or keeping them in the index more difficult.
“Anecdotally, since November 2021, I’ve also seen more and more indexing fluctuations across websites of all sizes – with the greater impacts being witnessed on websites 100k, and 100-million URL plus.” - Dan Taylor, August 2022
OR
“But in recent months, we’ve seen complaints from the owners of much smaller websites and our own data shows a similar trend spreading to 300-3,000 page websites as well. In fact, client Search Console accounts show a marked change in the way Google’s interacting with content.” - Alex Bussey, July 2024
OR
“I checked a large sample of the most popular e-commerce stores in the US for indexing issues. I discovered that, on average, 15% of their indexable product pages cannot be found on Google.” - Tomek Rudzki, November 2021
I’ve seen Google indexing problems for both clients and my personal websites. It was Google indexing issues that caused me to start investigating indexing at scale.
At the end of 2023, I noticed an important traffic-driving page for The SEO Sprint was suddenly marked as Not Indexed in Google Search Console.
There was no warning, no alert. One day, it was indexed. And the next, it wasn’t.
A tweet showing Google marking an important page as Not Indexed
The lack of warning from Google bothered me. So, I set out to try to solve it.
At the start of Q1 in 2024, I teamed up with a full-stack dev to create an index monitoring prototype to answer the following question:
Is it possible to monitor Google indexing of important pages at scale?
What is crazy is that we did it. We figured out how to monitor Google indexing at scale for site owners who want to check 100K pages.
Index Monitoring Prototype Page Fetching in 30 days
But we didn’t stop there. I was curious if we could push the solution to its limits.
So, we’ve been working with a handful of alpha testers with massive websites to stress test our solution with 100K - 1 million page websites.
For example, we’re inspecting over 1 million important pages for a client in 16 days.
The result of monitoring and analyzing millions of pages in Google’s index in 2024?
It has broken my mental model of how Google crawling and indexing works. And how page indexing reports work in Google Search Console.
In fact, I think the daily index monitoring has helped me better understand Google’s web search architecture. And has helped understand why there are Google's crawling and indexing fluctuations.
This technical knowledge has helped me work with tech teams and debug/fix issues. I think it can also help other SEO professionals solve indexing issues.
So, the goal of the newsletter is simple:
Tohelp SEO professionals learn more about how Google Indexing works AND help provide practical tips to fix indexing issues.
For example, the newsletter will help answer questions like:
How does page indexing status in GSC map to crawling & indexing architecture?
How does “crawled - currently not indexed” actually work?
How does Google decide what to index and not index?